python抓取网站URL小工具
1、安装Python requests模块(通过pip):

环境搭建好了!
2、测试一下抓取URL的过程:

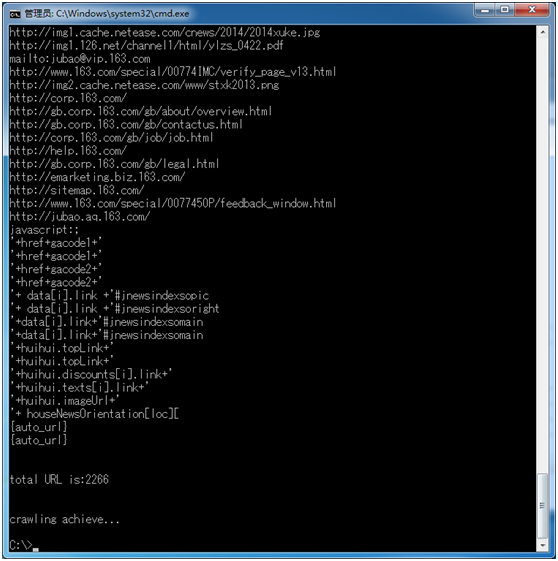
抓取出来的URL有JavaScript代码,正则上还有待更加完善,有兴趣的可以研究下~!
工具源代码:
#coding:utf-8
import sys
import re
import requests
#获取输入URL,并获取网页text
input = raw_input("please input URL format like this(http://www.baidu.com):")
print 'input : %s' % input
r = requests.get(input)
data = r.text
#利用正则查找所有URL
link_list =re.findall(r"(?<=href=\").+?(?=\")|(?<=href=\').+?(?=\')" ,data)
count = 0
for url in link_list:
file = open("c:\\test.txt", "a")
file.write(url+"\n")
count = count + 1
print url
print '\n'
print 'total URL is:' + str(count)
print '\n'
print 'crawling achieve...'
file.close()
python抓取网站URL小工具的更多相关文章
- python抓取网站提示错误ssl.SSLCertVerificationError处理
python在抓取制定网站的错误提示:ssl.SSLCertVerificationError: [SSL: CERTIFICATE_VERIFY_FAILED] certificate verify ...
- BeautifulSoup 抓取网站url
1 # -*- coding:utf-8 -*- 2 import urlparse 3 import urllib2 4 from bs4 import BeautifulSoup 5 6 url ...
- 【转】详解抓取网站,模拟登陆,抓取动态网页的原理和实现(Python,C#等)
转自:http://www.crifan.com/files/doc/docbook/web_scrape_emulate_login/release/html/web_scrape_emulate_ ...
- Python入门-编写抓取网站图片的爬虫-正则表达式
//生命太短 我用Python! //Python真是让一直用c++的村里孩子长知识了! 这个仅仅是一个测试,成功抓取了某网站1000多张图片. 下一步要做一个大新闻 大工程 #config = ut ...
- Python抓取页面中超链接(URL)的三中方法比较(HTMLParser、pyquery、正则表达式) <转>
Python抓取页面中超链接(URL)的3中方法比较(HTMLParser.pyquery.正则表达式) HTMLParser版: #!/usr/bin/python # -*- coding: UT ...
- 使用python抓取并分析数据—链家网(requests+BeautifulSoup)(转)
本篇文章是使用python抓取数据的第一篇,使用requests+BeautifulSoup的方法对页面进行抓取和数据提取.通过使用requests库对链家网二手房列表页进行抓取,通过Beautifu ...
- Python抓取视频内容
Python抓取视频内容 Python 是一种面向对象.解释型计算机程序设计语言,由Guido van Rossum于1989年底发明,第一个公开发行版发行于1991年.Python语法简洁而清晰,具 ...
- 使用 Python 抓取欧洲足球联赛数据
Web Scraping在大数据时代,一切都要用数据来说话,大数据处理的过程一般需要经过以下的几个步骤 数据的采集和获取 数据的清洗,抽取,变形和装载 数据的分析,探索和预测 ...
- Python抓取百度百科数据
前言 本文整理自慕课网<Python开发简单爬虫>,将会记录爬取百度百科"python"词条相关页面的整个过程. 抓取策略 确定目标:确定抓取哪个网站的哪些页面的哪部分 ...
随机推荐
- lucene-查询query->PrefixQuery使用前缀搜索
PrefixQuery就是使用前缀来进行查找的.通常情况下,首先定义一个词条Term.该词条包含要查找的字段名以及关键字的前缀,然后通过该词条构造一个PrefixQuery对象,就可以进行前缀查找了. ...
- iis Server Error in '/' Application
1.开始-运行-cmd-输入cd C:\WINDOWS\Microsoft.NET\Framework\v2.0.50727-回车-aspnet_regiis.exe -i 回车 2.如果不是检查链接 ...
- 【CodeForces 699A】Launch of Collider
维护最新的R,遇到L时如果R出现过就更新答案. #include <cstdio> #include <algorithm> using namespace std; int ...
- 如何在iOS9的plist文件中配置不使用https
App Transport Security has blocked a cleartext HTTP (http://) resource load since it is insecure. Te ...
- ARP协议工作流程
地址解析协议,即ARP(Address Resolution Protocol),是根据IP地址获取物理地址的一个TCP/IP协议.主机发送信息时将包含目标IP地址的ARP请求广播到网络上的所有主机, ...
- UVa 714 Copying Books(二分)
题目链接: 传送门 Copying Books Time Limit: 3000MS Memory Limit: 32768 KB Description Before the inventi ...
- python列表、元组、字典(四)
列表 如:[11,22,33,44,44].['TangXiaoyue', 'bruce tang'] 每个列表都具备如下功能: class list(object): ""&qu ...
- shell 中 &&和||的方法
Shell && 和 || shell 在执行某个命令的时候,会返回一个返回值,该返回值保存在 shell 变量 $? 中.当 $? == 0 时,表示执行成功:当 $? == 1 时 ...
- css004 用样式继承节省时间
css004 用样式继承节省时间 继承:inherit 继承可以简化样式表 继承是有局限的,有些样式没法继承,如:border,width,height
- phpcms从表v9_news_data中字段content中用正则取出图片的地址输出
preg_match ("<img.*src=[\"](.*?)[\"].*?>",$test,$match); echo "$match ...