【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 10—Advice for applying machine learning 机器学习应用建议
Lecture 10—Advice for applying machine learning
10.1 如何调试一个机器学习算法?
有多种方案:
1、获得更多训练数据;2、尝试更少特征;3、尝试更多特征;4、尝试添加多项式特征;5、减小 λ;6、增大 λ

为了避免一个方案一个方案的尝试,可以通过评估机器学习算法的性能,来进行调试。
机器学习诊断法 Machine learning diagnostic 的定义:

10.2 评估一个假设
想要评估一个算法是否过拟合

(一)首先,划分测试集和训练集
如果数据已经随机分布了, 可以选择前70%数据作为训练集,剩下的30%作为测试集;
如果数据不是随机分布的,最好先打乱,或者随机选择70%数据作为训练集,剩下的30%作为测试集

(二)然后,计算测试误差
1、对于回归问题。例如线性回归。首先使用训练集进行训练,然后使用测试集计算测试误差:

2、对于分类问题。例如逻辑回归,也是一样的:

有一种更易理解的测试误差定义方式,叫做 错分率 Misclassification error (也叫0/1错分率):

err(hθ(x),y) 的意思是:如果分类预测结果 hθ(x) 错误,则 err 值为1;如果 hθ(x) 预测正确,则 err 值为0。 整体的测试误差就是所有 err 值的加和。
10.3 模型选择 和 "训练/验证/测试"集
产生过拟合的一个原因是:仅仅在测试集合上调试 θ 得到的训练误差,通常不能作为对实际泛化误差的一个好的估测。

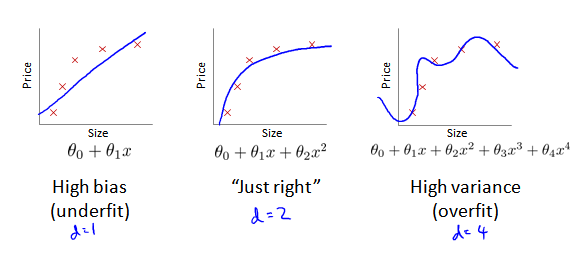
那么究竟应该选择几次多项式来作为我们的模型呢?
假设针对 x 有10个模型:一次方程 直到 十次方程。对每个多项式,在训练集上训练出 θ 。然后分别使用 test 集合计算误差,分别得到 Jtest(θ(1)),...Jtest(θ(10)),发现 Jtest(θ(5))的值最小,因此选择 d=5 这个模型。
但这里有个问题:我们选的这个模型,就是能够最好地拟合测试集的参数d的值及多项式的度。因此,再使用同样的测试集来评价假设,显然很不公平,很可能导致过拟合。
所以,我们改为将数据集分为 6:2:2 三部分:training set、cross validation set(cv, 或者直接简称validation set)、test set
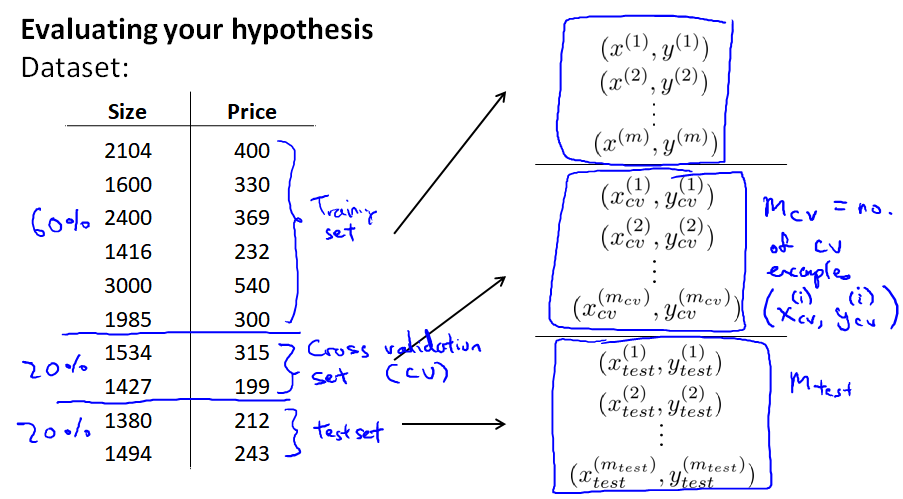
每个集合上的误差计算公式:

现在我们是用 cv 集合计算误差,分别得到 Jcv(θ(1)),...Jcv(θ(10)),发现 Jcv(θ(4)) 的值最小,因此选择 d=4 这个模型,最后在 test 集合上进行预测,能得到一个更理想的泛化误差。

10.4 检验误差和方差 Diagnosing bias vs. variance
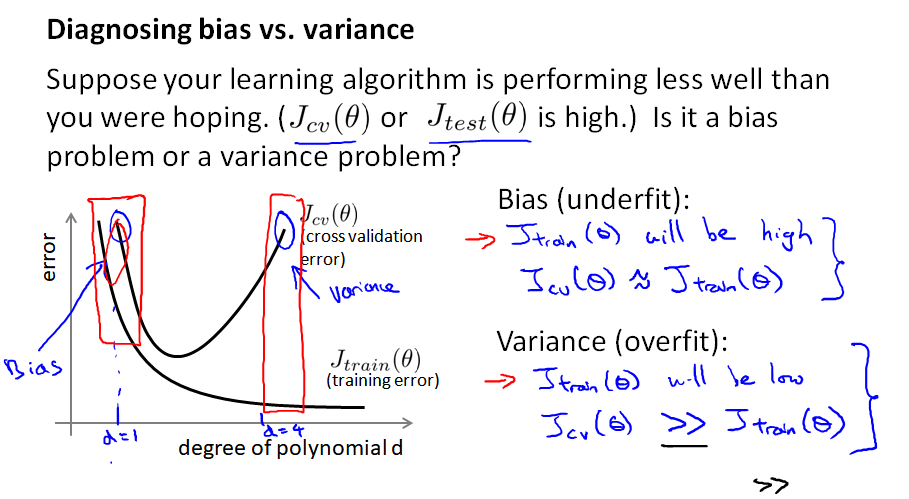
模型表现不好,通常有两种情况:
(1) 误差 bias 过大,导致欠拟合 underfitting;
(2) 方差 variance 过大,导致过拟合 overfitting
使用多项式的度 d 作为横轴,在训练集和cv集上分别计算 J(θ),得到曲线:
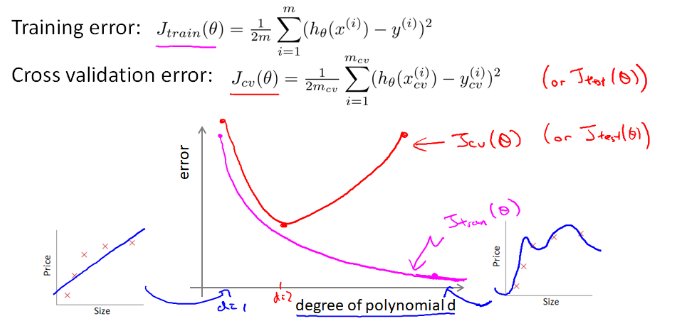
下面说如何根据两条曲线判断模型是高误差(欠拟合)、还是高方差(过拟合)。
(1) 先看曲线左边,当 d=1 ,训练集和cv集的误差都很大,说明欠拟合
(2) 再看曲线右边,当 d=4 ,训练集误差很小、cv集误差远大于训练误差,说明在训练集上过拟合
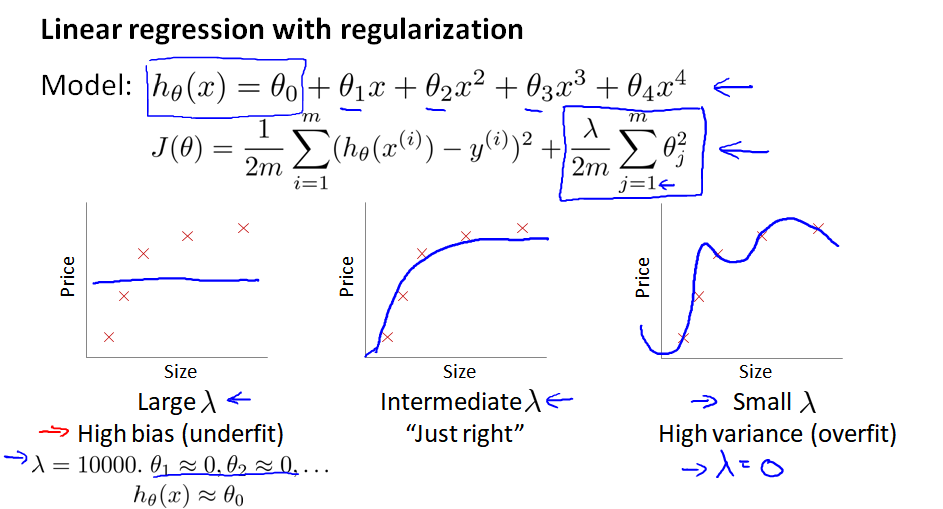
10.5 正规化 和 偏差/方差
考虑正则化的线性回归模型:
(1) 当 λ 过大,θ 被惩罚后会变得很小、接近于0,最后方程只剩下 θ0 这一项,成为一条直线,导致高偏差bias、欠拟合。
(2) 当 λ 过小,正则项不起作用,导致高方差 variance、过拟合。
那怎么选择 λ 的值呢?
首先,当我们定义每个集合上的误差函数时,不考虑 λ。
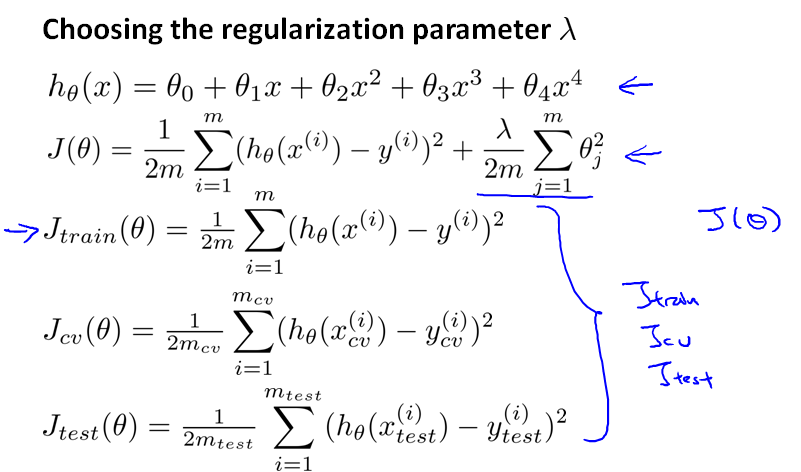
然后按照步长两倍的方式递增 λ,针对每个 λ 训练θ。然后分别计算对应的Jcv(θ),得到最小的Jcv(θ(5))。然后在 test 集合上进行测试。

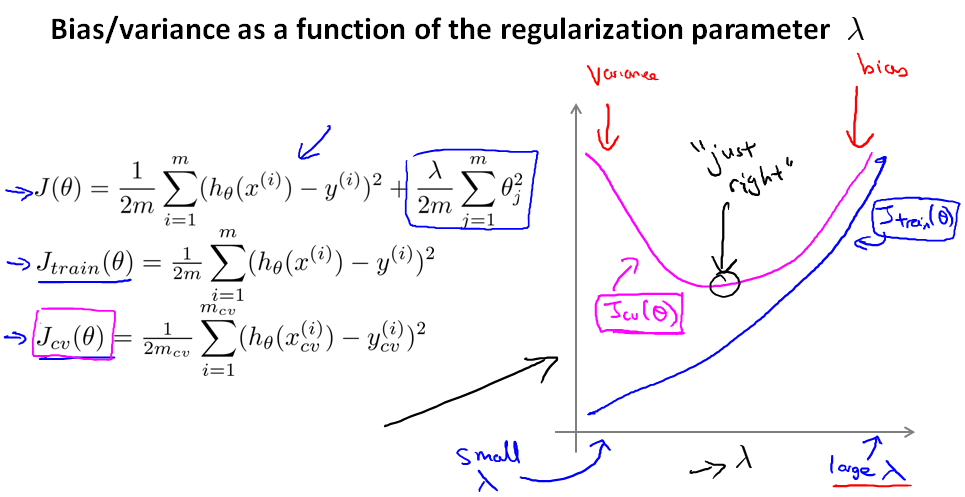
现在我们看一下,λ 的大小对损失函数的影响。
(1) 先看曲线左边,当 λ 很小 ,Jcv(θ) 的值远大于 Jtrain(θ),说明过拟合
(2) 再看曲线右边,当 λ 很大 ,Jcv(θ) 和 Jtrain(θ) 都很大,说明欠拟合
10.6 学习曲线
m指训练样本的个数,曲线显示不同的m对于J(θ)的影响
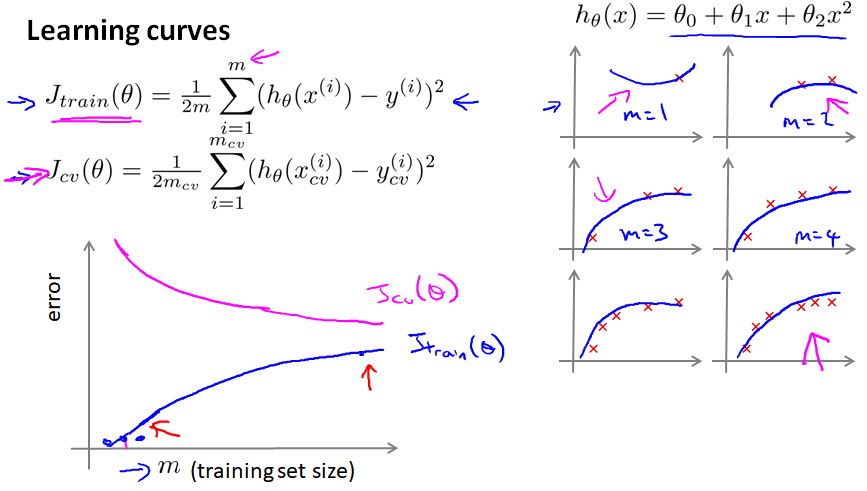
高偏差 bias、欠拟合:

高方差 variance、过拟合。两个曲线会有一个很大的gap:

10.7 接下来
每种解决方案对应的问题如下(箭头右侧指向的是表现出的问题,左侧是解决方案):

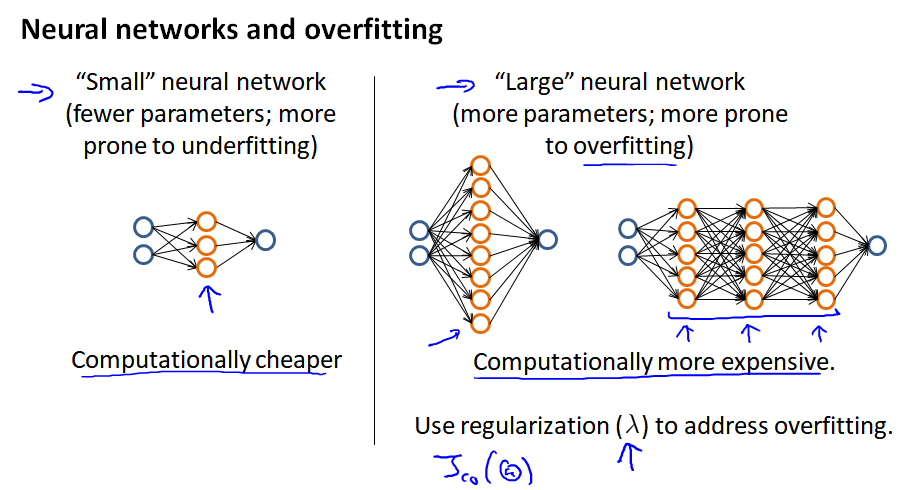
对于神经网络,开始可以尝试一个相对比较简单的神经网络模型,计算量小。
如果使用大型神经网络,使用正则化来修正过拟合。
如果不知道选择几层hidden layer,可以将数据分为三个数据集之后,分别做测试。
附
关于偏差和方差的解释,参考:https://blog.csdn.net/u010626937/article/details/74435109
偏差:描述的是预测值的期望与真实值之间的差距。偏差越大,越偏离真实数据集。(Ps:假设靶心是最适合给定数据的模型,离靶心越远,我们的预测就越糟糕)
方差:描述的是预测值的变化范围,离散程度,也就是离其期望值的距离。方差越大,预测结果数据的分布越散。
基于偏差的误差:所谓基于偏差的误差是我们模型预期的预测与我们将要预测的真实值之间的差值。偏差是用来衡量我们的模型的预测同真实值的差异。
基于方差的误差:基于方差的误差描述了一个模型对给定的数据进行预测的可变性。比如,当你多次重复构建完整模型的进程时,方差是在预测模型的不同关系间变化的多少。
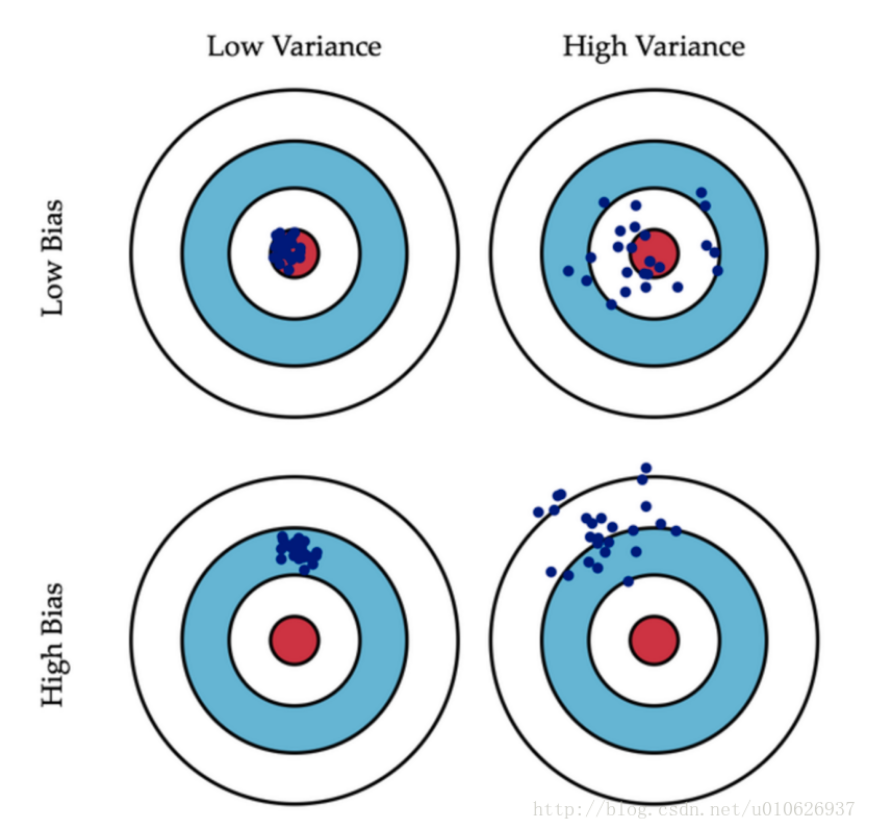
左上:低偏差bias,低方差variance。预测结果准确率很高,并且模型比较健壮(稳定),预测结果高度集中。
右上:低偏差bias,高方差variance。预测结果准确率较高,但是模型不稳定,预测结果比较发散。
左下:高偏差bias,低方差variance。预测结果准确率较低,但是模型稳定,预测结果比较集中。
右下:高偏差bias,高方差variance。预测结果准确率较低,并且模型不稳定,预测结果比较发散。
【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 10—Advice for applying machine learning 机器学习应用建议的更多相关文章
- (原创)Stanford Machine Learning (by Andrew NG) --- (week 6) Advice for Applying Machine Learning & Machine Learning System Design
(1) Advice for applying machine learning Deciding what to try next 现在我们已学习了线性回归.逻辑回归.神经网络等机器学习算法,接下来 ...
- 斯坦福大学公开课机器学习:advice for applying machine learning | diagnosing bias vs. variance(机器学习:诊断偏差和方差问题)
当我们运行一个学习算法时,如果这个算法的表现不理想,那么有两种原因导致:要么偏差比较大.要么方差比较大.换句话说,要么是欠拟合.要么是过拟合.那么这两种情况,哪个和偏差有关.哪个和方差有关,或者是不是 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 14—Dimensionality Reduction 降维
Lecture 14 Dimensionality Reduction 降维 14.1 降维的动机一:数据压缩 Data Compression 现在讨论第二种无监督学习问题:降维. 降维的一个作用是 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 11—Machine Learning System Design 机器学习系统设计
Lecture 11—Machine Learning System Design 11.1 垃圾邮件分类 本章中用一个实际例子: 垃圾邮件Spam的分类 来描述机器学习系统设计方法.首先来看两封邮件 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 1_Introduction and Basic Concepts 介绍和基本概念
目录 1.1 欢迎1.2 机器学习是什么 1.2.1 机器学习定义 1.2.2 机器学习算法 - Supervised learning 监督学习 - Unsupervised learning 无 ...
- 【原】Coursera—Andrew Ng机器学习—课程笔记 Lecture 17—Large Scale Machine Learning 大规模机器学习
Lecture17 Large Scale Machine Learning大规模机器学习 17.1 大型数据集的学习 Learning With Large Datasets 如果有一个低方差的模型 ...
- Coursera 机器学习 第6章(上) Advice for Applying Machine Learning 学习笔记
这章的内容对于设计分析假设性能有很大的帮助,如果运用的好,将会节省实验者大量时间. Machine Learning System Design6.1 Evaluating a Learning Al ...
- Ng第十课:应用机器学习的建议(Advice for Applying Machine Learning)
10.1 决定下一步做什么 10.2 评估一个假设 10.3 模型选择和交叉验证集 10.4 诊断偏差和方差 10.5 归一化和偏差/方差 10.6 学习曲线 10.7 决定下一步做什么 ...
- 斯坦福第十课:应用机器学习的建议(Advice for Applying Machine Learning)
10.1 决定下一步做什么 10.2 评估一个假设 10.3 模型选择和交叉验证集 10.4 诊断偏差和方差 10.5 归一化和偏差/方差 10.6 学习曲线 10.7 决定下一步做什么 ...
随机推荐
- python笔记-12 redis缓存
一.redis引入 1.简要概括redis 1.1 redis默认端口:6379 1.2 redis实现的效果:资源共享 1.3 redis实现的基本原理:不同的进程和一个公共的进程之间建立socke ...
- PHP 生成类似 SqlServer NEWID() 全局唯一标识符
最近在对接SqlServer中对方有一个字段要求 SqlServer 中 有一个 NEWID() 就是生成36位的 唯一标识符 -> 8CBD3198-297D-4037-A859-B27BB ...
- MySQL-Proxy 读写分离、同步延时问题解决方案
MySQL-Proxy 读写分离.同步延时问题解决方案 使用MySQL将读写请求转接到主从Server. 一 安装MySQL Proxy MySQL Proxy的二进制版非常方便,下载解压缩后即用. ...
- Linux中源码安装编译Vim
Linux中源码安装编译Vim Linux下学习工作少不了编辑器,Vim能使你的工作效率成倍的提高.在Ubuntu上安装vim使用命令直接安装很简单.但有时还是需要自己手动编译安装.例如: vim中的 ...
- python官网
https://www.python.org/ https://docs.python.org/2/library/pydoc.html
- jieba分词初学
昨天,做的那个数据分析报告用到了jieba分词.但是只是借用了别人的部分代码.具体函数代表什么还不太明白.今天去官网研究了下..... jieba官网简介 "结巴"中文分词:做最好 ...
- mysql的partition分区
前言:当一个表里面存储的数据特别多的时候,比如单个.myd数据都已经达到10G了的话,必然导致读取的效率很低,这个时候我们可以采用把数据分到几张表里面来解决问题.方式一:通过业务逻辑根据数据的大小通过 ...
- laravel里面使用event
模式:大概是通过一个自定义的event,一个handler,还有一个binder,然后用来简化通知模型 生成自定义的event ./artisan make:event MyEvent 生成自定义的h ...
- HDOJ5521(巧妙构建完全图)
Meeting Time Limit: 12000/6000 MS (Java/Others) Memory Limit: 262144/262144 K (Java/Others)Total ...
- css loading 效果
.loading{ width:160px; height:56px; position: absolute; top:50%; left:50%; line-height:56px; color:# ...