跟我学算法-Logistic回归
虽然Logistic回归叫回归,但是其实它是一个二分类或者多分类问题
这里的话我们使用信用诈骗的数据进行分析
第一步:导入数据,Amount的数值较大,后续将进行(-1,1)的归一化
data = pd.read_csv('creditcard.csv') #读取数据
#查看前5行数据
print(data.head())
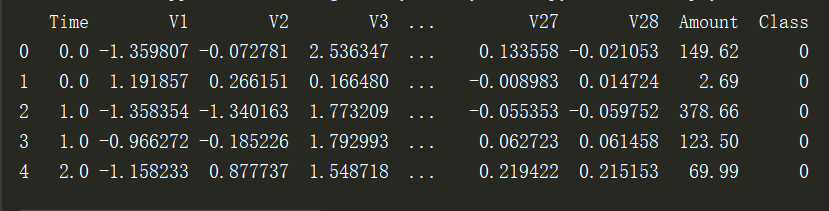
第二步: 对正常和欺诈的数目进行查看,正常样本的数目远大于欺诈样本,这个时候可以使用下采样或者过采样
# 画图查看
count_data = pd.value_counts(data['Class'], sort=True).sort_index() #统计样本数
count_data.plot(kind='bar') #画条形图
plt.title("Fraud class histogram") #标题
plt.xlabel('Classes')
plt.ylabel('Frequency')
plt.show()
第三步:将amount进行归一化形成amountNorm,并且去除time和amount项
#把amount数据标准化到-1, 1
from sklearn.preprocessing import StandardScaler
#reshape 需要转换到的数值范围
data['NormAmount'] = StandardScaler().fit_transform(data['Amount'].values.reshape(-1, 1),)
data = data.drop(['Time', 'Amount'], axis=1) # 去除两列 #进行分组
X = data.ix[:, data.columns != 'Class']
y = data.ix[:, data.columns == 'Class']
第四步,使用随机挑选来生成下采样数据
number_record_fraud = len(data[data.Class==1])
#找出其索引,组成数组
fraud_indices = np.array(data[data.Class == 1].index)
norm_indices = data[data.Class == 0 ].index
#从Class=0中任意挑选500个组成正常的类别
random_norm_indices = np.random.choice(norm_indices, 500, replace=False)
random_norm_indices = np.array(random_norm_indices) #把正常的类别和欺诈类别进行组合
under_sample_indices = np.concatenate([fraud_indices, random_norm_indices])
#根据重组索引重新取值
under_sample_datas = data.iloc[under_sample_indices,:]
#选择出属性和结果
X_undersample = under_sample_datas.ix[:, under_sample_datas.columns != 'Class']
第5步,交叉验证选择权重,这里采用的加权方法为|L* w|
from sklearn.linear_model import LogisticRegression
from sklearn.cross_validation import KFold, cross_val_score
from sklearn.metrics import confusion_matrix,recall_score,classification_report
def printing_Kfold_socres(x_train_data, y_train_data):
fold = KFold(len(y_train_data), 5, shuffle=False) c_param_range = [0.01, 0.1, 1, 10, 100]
#创建一个空的列表用来存储Mean recall score的值
results_table = pd.DataFrame(index=range(len(c_param_range), 2), columns=['C_parameter', 'Mean recall score']) results_table['C_parameter'] = c_param_range j = 0
for c_param in c_param_range:
print('-----------------------')
print('C paramter:', c_param)
print('-----------------------')
print('') recall_accs = []
for iteration, indices in enumerate(fold, start=1):
lr = LogisticRegression(C = c_param, penalty='l1') #放入参数,权重模式为l1
print('indices', indices)
#建立模型并训练
lr.fit(x_train_data.iloc[indices[0], :], y_train_data.iloc[indices[0], :].values.ravel())
y_pred_undersample = lr.predict(x_train_data.iloc[indices[1], :].values)
print(y_pred_undersample)
#计算回归得分
recall_acc = recall_score(y_train_data.iloc[indices[1],:].values, y_pred_undersample)
recall_accs.append(recall_acc)
print('Iteration', iteration, ': recall score=', recall_acc) #求得平均的值
results_table.ix[j, 'Mean recall score'] = np.mean(recall_accs)
j += 1
print('')
print('Mean recall score', np.mean(recall_accs))
print('')
# 数据类型进行转换
results_table['Mean recall score'] = results_table['Mean recall score'].astype('float64')
# 求得Mean recall score 对应的最大的C_parameter值
best_c = results_table.loc[results_table['Mean recall score'].idxmax()]['C_parameter']
print('*********************************************************************************')
print('Best model to choose from cross validation is with C parameter = ', best_c)
print('*********************************************************************************') return best_c #执行程序
best_c = printing_Kfold_socres(X_train_undersample, y_train_undersample)
跟我学算法-Logistic回归的更多相关文章
- 【机器学习】分类算法——Logistic回归
一.LR分类器(Logistic Regression Classifier) 在分类情形下,经过学习后的LR分类器是一组权值w0,w1, -, wn,当测试样本的数据输入时,这组权值与测试数据按照线 ...
- 机器学习算法-logistic回归算法
Logistic回归算法调试 一.算法原理 Logistic回归算法是一种优化算法,主要用用于只有两种标签的分类问题.其原理为对一些数据点用一条直线去拟合,对数据集进行划分.从广义上来讲这也是一种多元 ...
- Logistic回归(逻辑回归)和softmax回归
一.Logistic回归 Logistic回归(Logistic Regression,简称LR)是一种常用的处理二类分类问题的模型. 在二类分类问题中,把因变量y可能属于的两个类分别称为负类和正类, ...
- 《机器学习实战》-逻辑(Logistic)回归
目录 Logistic 回归 本章内容 回归算法 Logistic 回归的一般过程 Logistic的优缺点 基于 Logistic 回归和 Sigmoid 函数的分类 Sigmoid 函数 Logi ...
- 常见算法(logistic回归,随机森林,GBDT和xgboost)
常见算法(logistic回归,随机森林,GBDT和xgboost) 9.25r早上面网易数据挖掘工程师岗位,第一次面数据挖掘的岗位,只想着能够去多准备一些,体验面这个岗位的感觉,虽然最好心有不甘告终 ...
- 神经网络、logistic回归等分类算法简单实现
最近在github上看到一个很有趣的项目,通过文本训练可以让计算机写出特定风格的文章,有人就专门写了一个小项目生成汪峰风格的歌词.看完后有一些自己的小想法,也想做一个玩儿一玩儿.用到的原理是深度学习里 ...
- Logistic回归分类算法原理分析与代码实现
前言 本文将介绍机器学习分类算法中的Logistic回归分类算法并给出伪代码,Python代码实现. (说明:从本文开始,将接触到最优化算法相关的学习.旨在将这些最优化的算法用于训练出一个非线性的函数 ...
- 第三集 欠拟合与过拟合的概念、局部加权回归、logistic回归、感知器算法
课程大纲 欠拟合的概念(非正式):数据中某些非常明显的模式没有成功的被拟合出来.如图所示,更适合这组数据的应该是而不是一条直线. 过拟合的概念(非正式):算法拟合出的结果仅仅反映了所给的特定数据的特质 ...
- 机器学习之Logistic 回归算法
1 Logistic 回归算法的原理 1.1 需要的数学基础 我在看机器学习实战时对其中的代码非常费解,说好的利用偏导数求最值怎么代码中没有体现啊,就一个简单的式子:θ= θ - α Σ [( hθ( ...
随机推荐
- three.js中点生成矩阵方法
正常情况用threejs 点生成matrix4,方法为: 例如生成饶Y轴旋转的矩阵我们要的结果为: [cos, 0, -sin, 0, 0, 1, 0, 0, sin, 0, cos, ...
- BZOJ1087 SCOI2005 互不侵犯King 【状压DP】
BZOJ1087 SCOI2005 互不侵犯King Description 在N×N的棋盘里面放K个国王,使他们互不攻击,共有多少种摆放方案.国王能攻击到它上下左右,以及左上左下右上右下八个方向上附 ...
- POJ3422 Kaka's Matrix Travels 【费用流】*
POJ3422 Kaka's Matrix Travels Description On an N × N chessboard with a non-negative number in each ...
- atom的设置
1.隐藏Keybinding Resolver Packages->Keybinding Resolver->Toggle.
- C语言控制台窗体图形界面编程(八):鼠标事件
上次讲的是键盘事件,这次我们介绍鼠标事件. 以下先介绍下鼠标事件的结构体以及相关信息. typedef struct _MOUSE_EVENT_RECORD //鼠标事件结构体 { CO ...
- [LeetCode系列]N皇后问题递归解法 -- 位操作方式
N皇后问题: 给定8*8棋盘, 放置n个皇后, 使其互相不能攻击(即2个皇后不能放在同一行/列/正反对角线上), 求解共有多少种放置方式? 这个问题的解答网上有不少, 但是位操作解法的我看到的不多. ...
- docker-tomcat
https://yq.aliyun.com/articles/6894 1,add命令源目录 只能从 ./ 当前目录开始,目标目录是容器的目录,不是服务器的目录 2,server.xml改的东西,里面 ...
- CStdioFile的Writestring无法写入中文的问题
解决UNICODE字符集下CStdioFile的Writestring无法写入中文的问题 2009-12-01 23:11 以下代码文件以CStdioFile向无法向文本中写入中文(用notepad. ...
- Service的用法
基本用法: 1.创建一个类继承Service类,并重写onBind() 2.重写其他方法:onCreate().onStartCommand().onDestory() 3.在AndroidManif ...
- java web 程序--注册页面/HashMap的用法。。要懂啊
思路:1.一个form表单,用户输入后,提交 2.第二个是注册页面,主要是用Map.先假设往map里面拿东西,然后判断是否为空 若为空,new 一个HashMap它的子类,然后通过map.conta ...