关于urllib、urllib2爬虫伪装的总结
站在网站管理的角度,如果在同一时间段,大家全部利用爬虫程序对自己的网站进行爬取操作,那么这网站服务器能不能承受这种负荷?肯定不能啊,如果严重超负荷则会时服务器宕机(死机)的,对于一些商业型的网站,宕机一秒钟的损失都是不得了的,这不是一个管理员能承担的,对吧?那管理员会网站服务器做什么来优化呢?我想到的是,写一个脚本,当检测到一个IP访问的速度过快,报文头部并不是浏览器的话,那么就拒绝服务,或者屏蔽IP等,这样就可以减少服务器的负担并让服务器正常进行。
那么既然服务器做好了优化,但你知道这是对爬虫程序的优化,如果你是用浏览器来作为一个用户访问的话,服务器是不会拦截或者屏蔽你的,它也不敢拦你,为什么,你现在是客户,它敢拦客户,不想继续经营了是吧?所以对于如果是一个浏览器用户的话,是可以正常访问的。
所以想到方法了吗?是的,把程序伪造成一个浏览器啊,前面说过服务器会检测报文头部信息,如果是浏览器就不正常通行,如果是程序就拒绝服务。
那么报文是什么?头部信息又是什么?详细的就不解释了,这涉及到http协议和tcp/ip三次握手等等的网络基础知识,感兴趣的自己百度或者谷歌吧。
本篇博文不扯远了,只说相关的重点——怎么查看头部信息。
User-Agent
其实我想有些朋友可能有疑惑,服务器是怎么知道我们使用的是程序或者浏览器呢?它用什么来判断的?
我使用的是火狐浏览器,鼠标右键-查看元素(有的浏览器是审查元素或者检查)
网络(有的是network):
出现报文:

双击它, 右边则会出现详细的信息,选择消息头(有的是headers)

找到请求头(request headers),其中的User-Agent就是我们头部信息:
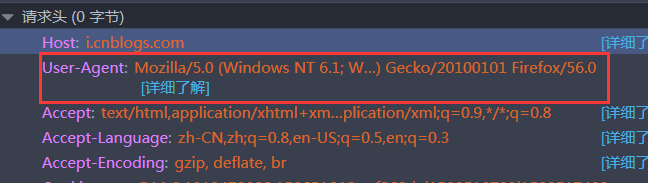
看到是显示的

# -*- coding:utf-8 -*-
import urllib url='http://www.baidu.com' #百度网址
html=urllib.urlopen(url)#利用模块urllib里的urlopen方法打开网页
print(dir(html)) #查看对象html的方法
print(urllib.urlopen) #查看对象urllib.urlopen的方法
print(urllib.urlopen()) #查看对象urllib.urlopen实例化后的方法
Traceback (most recent call last):
File "D:\programme\PyCharm 5.0.3\helpers\pycharm\utrunner.py", line 121, in <module>
modules = [loadSource(a[0])]
File "D:\programme\PyCharm 5.0.3\helpers\pycharm\utrunner.py", line 41, in loadSource
module = imp.load_source(moduleName, fileName)
File "G:\programme\Python\python project\test.py", line 8, in <module>
print(urllib.urlopen())
TypeError: urlopen() takes at least 1 argument (0 given) ['__doc__', '__init__', '__iter__', '__module__', '__repr__', 'close', 'code',
'fileno', 'fp', 'getcode', 'geturl', 'headers', 'info', 'next', 'read', 'readline', 'readlines', 'url'] <function urlopen at 0x0297FD30>
由此,这里就必须注意,只有当urllib.urlopen()实例化后才有其后面的方法,urlopen会返回一个类文件对象,urllib.urlopen只是一个对象,而urllib.urlopen()必须传入一个参数,不然则报错。
urlopen提供了如下方法:
- read() , readline() , readlines() , fileno() , close() :这些方法的使用方式与文件对象完全一样
- info():返回一个httplib.HTTPMessage 对象,表示远程服务器返回的头信息
- getcode():返回Http状态码。如果是http请求,200表示请求成功完成;404表示网址未找到
- geturl():返回请求的url
- headers:返回请求头部信息
- code:返回状态码
- url:返回请求的url
好的,详细的自己去研究了,本篇博文的重点终于来了,伪装一个头部信息
伪造头部信息
由于urllib没有伪造头部信息的方法,所以这里得使用一个新的模块,urllib2
# -*- coding:utf-8 -*-
import urllib2 url='http://www.baidu.com' head={
'User-Agent':'Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0'
} #头部信息,必须是一个字典
html=urllib2.Request(url,headers=head)
result=urllib2.urlopen(html)
print result.read()
或者你也可以这样:
# -*- coding:utf-8 -*-
import urllib2 url='http://www.baidu.com' html=urllib2.Request(url)
html.add_header('User-Agent','Mozilla/5.0 (Windows NT 6.1; Win64; x64; rv:56.0) Gecko/20100101 Firefox/56.0') #此时注意区别格式
result=urllib2.urlopen(html)
print result.read()
结果都一样的,我也就不展示了。
按照上面的方法就可以伪造请求头部信息。
那么你说,我怎么知道伪造成功了?还有不伪造头部信息时,显示的到底是什么呢?介绍一个抓包工具——fidder,用这个工具就可以查看到底报文头部是什么了。这里就不展示了,自己下去常识了。并且我可以确切的保证,确实伪造成功了。
这样,我们就把爬虫代码升级了一下,可以搞定普通的反爬虫限制
关于urllib、urllib2爬虫伪装的总结的更多相关文章
- 第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术、设置用户代理
第三百二十八节,web爬虫讲解2—urllib库爬虫—状态吗—异常处理—浏览器伪装技术.设置用户代理 如果爬虫没有异常处理,那么爬行中一旦出现错误,程序将崩溃停止工作,有异常处理即使出现错误也能继续执 ...
- 人生苦短之Python的urllib urllib2 requests
在Python中涉及到URL请求相关的操作涉及到模块有urllib,urllib2,requests,其中urllib和urllib2是Python自带的HTTP访问标准库,requsets是第三方库 ...
- python urllib urllib2
区别 1) urllib2可以接受一个Request类的实例来设置URL请求的headers,urllib仅可以接受URL.这意味着,用urllib时不可以伪装User Agent字符串等. 2) u ...
- httplib urllib urllib2 pycurl 比较
最近网上面试看到了有关这方面的问题,由于近两个月这些库或多或少都用过,现在根据自己的经验和网上介绍来总结一下. httplib 实现了HTTP和HTTPS的客户端协议,一般不直接使用,在python更 ...
- python爬虫伪装技术应用
版权声明:本文为博主原创文章,转载 请注明出处: https://blog.csdn.net/sc2079/article/details/82423865 -写在前面 本篇博客主要是爬虫伪装技术的应 ...
- python中urllib, urllib2,urllib3, httplib,httplib2, request的区别
permike原文python中urllib, urllib2,urllib3, httplib,httplib2, request的区别 若只使用python3.X, 下面可以不看了, 记住有个ur ...
- 第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解
第三百三十节,web爬虫讲解2—urllib库爬虫—实战爬取搜狗微信公众号—抓包软件安装Fiddler4讲解 封装模块 #!/usr/bin/env python # -*- coding: utf- ...
- 第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理—用户代理和ip代理结合应用
第三百二十九节,web爬虫讲解2—urllib库爬虫—ip代理 使用IP代理 ProxyHandler()格式化IP,第一个参数,请求目标可能是http或者https,对应设置build_opener ...
- 第三百二十七节,web爬虫讲解2—urllib库爬虫—基础使用—超时设置—自动模拟http请求
第三百二十七节,web爬虫讲解2—urllib库爬虫 利用python系统自带的urllib库写简单爬虫 urlopen()获取一个URL的html源码read()读出html源码内容decode(& ...
随机推荐
- vijos 1288 箱子游戏 计算几何
背景 hzy是箱子迷,他很喜欢摆放箱子,这次他邀请zdq,skoier一起来玩game... 描述 地板上有一个正方形的大箱子和许多三角型的小箱子.所有的小箱子都在大箱子里面,同时,一些三角形的小箱子 ...
- JAVA中反射机制六(java.lang.reflect包)
一.简介 java.lang.reflect包提供了用于获取类和对象的反射信息的类和接口.反射API允许对程序访问有关加载类的字段,方法和构造函数的信息进行编程访问.它允许在安全限制内使用反射的字段, ...
- ① 设计模式的艺术-07.适配器(Adapter)模式
什么是适配器模式? 将一个类的接口转换成客户希望的另外一个接口.Adapter模式使得原本由于接口不兼容而不能一起工作的那些类可以在一起工作. 模式中的角色 目标接口(Target):客户所期待的接口 ...
- bootstrap带图标的按钮与图标做连接
bootstrap通过引入bootstrap的JS与css文件,给元素添加class属性即可. 使用图标只需要加入一个span,class属性设置为对应的图标属性即可.图标对应的class属性可以参考 ...
- Linux中等待队列的实现
1. 等待队列数据结构 等待队列由双向链表实现,其元素包括指向进程描述符的指针.每个等待队列都有一个等待队列头(wait queue head),等待队列头是一个类型为wait_quequ ...
- 前端nginx时,让后端tomcat记录真实IP【转】
对于nginx+tomcat这种架构,如果后端tomcat配置保持默认,那么tomcat的访问日志里,记录的就是前端nginx的IP地址,而不是真实的访问IP.因此,需要对nginx.tomcat做如 ...
- xshell连接Ubuntu虚拟机
Ubuntu系统 1,安装ssh sudo apt-get install openssh-server 2,启动ssh进程 /etc/init.d/ssh start 3,查看进程信息 ps -e ...
- ASP.NET中的状态保持
1.ASP.NET中的状态保持解决方案 2.常用的状态报保持方式 view state ASP.Net的.aspx页面特有,页面级的,就是在页面上的一个隐藏域中保存客户端单独使用的数据的一种方式(b ...
- [ python ] 全局和局部作用域变量的引用
全局与局部变量的引用 (a)locals(b)globals 这里还需要在补充2个关键字一起比较学习,关键字:(c)nonlocal(d)global locals 和 globals locals: ...
- web.xml中的dispatchservlet后,js,css,甚至gif都不能正常显示
这个可以说是很多初学Springmvc的人都会碰到一个令人头痛的问题 那就是为什么我配置好web.xml中的dispatchservlet后,js,css,甚至gif都不能正常显示了 我们来看看我们配 ...