有关elasticsearch分片策略的总结
原先普通索引我的分片策略是: 主分片=节点数,副本=1,这样可以保证业务数据一定的可用性(丢失一个节点数据完整),且书局是均匀的读写请求在各个节点也是均匀的。
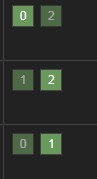
该模式目前看来并不是一个最好的方案,首先对于写请求,请求会优先落到主分片,再由主分片下发到各个副本,默认半数节点同步完返回,主分片=机器数可以保证写请求负载均衡,而1个副本的情况下主分片写成功即可,所以该模式对写还是相对友好。
但是读场景下,由于多个分片分散在不同机器上,请求会从client node发布到各个分片号上取topN汇总,通一个分片号的分片不会出现在一台机器,所以虽然搜索请求还是负载均衡的,但是等于每个机器上都执行了一次搜索,而且有的分片上有目标数据有的没有,也会出现有的机器上执行的快,负载低;有的执行慢负载高。
那么针对读远大于写的这种case,我的方案是:主分片=1,副本=节点数-1。 这样能够保证每个节点一个分片,读请求在任意分片都是可执行的,而且主分片只有一个,意味着搜索请求既可以负载到任一节点执行,同一个请求又不会复制到多个机器执行,就能减少多余的查询开销。
当然了这样做对写就不友好了,首先多个副本,默认的测略是半数完成返回,理论上副本越多读延时越长,而且单个主分片意味着写请求会全都打到在主分片所在机器。不过对于写远小于读的场景应该是可以接受的。还有个问题就是读远大于写,可能会有半数分片没有同步完的执行了读,存在一定的数据不一致,这种可以通过调整weite.consistency为all来解决,只要写性能优先级不高。
所以最后我的结论是:
1.读远大于写的场景,可以减少主分片个数,增加副本数,提升读吞吐率,前提是写的优先级不高。极端情况下单分片多副本可以最大程度提升总的读吞吐。
2.写远大于读的场景,最大程度分配主分片个数,一个机器一个,并最大程度减少副本数(极端情况下集群规模不大且可用性优先级较低时可以不要副本)。
额外多说下,提到分片,segment作为更细粒度的分片,其相关策略可以类比,因为读请求也是要遍历各个segment的,因此读场景下适当减少segment能够减少segment的遍历。而合并segment也是开销比较大的动作,尽量在低峰期处理避免cpu load过高反噬读性能。
有关elasticsearch分片策略的总结的更多相关文章
- Elasticsearch分片、副本与路由(shard replica routing)
本文讲述,如何理解Elasticsearch的分片.副本和路由策略. 1.预备知识 1)分片(shard) Elasticsearch集群允许系统存储的数据量超过单机容量,实现这一目标引入分片策略sh ...
- Elasticsearch分片优化
原文地址:https://qbox.io/blog/optimizing-elasticsearch-how-many-shards-per-index 大多数ElasticSearch用户在创建索引 ...
- 【分库分表】sharding-jdbc—分片策略
一.分片策略 Sharding-JDBC认为对于分片策略存有两种维度: 数据源分片策略(DatabaseShardingStrategy):数据被分配的目标数据源 表分片策略(TableShardin ...
- Elastic-Job-Lite 源码分析 —— 作业分片策略
摘要: 原创出处 http://www.iocoder.cn/Elastic-Job/job-sharding-strategy/ 「芋道源码」欢迎转载,保留摘要,谢谢! 本文基于 Elastic-J ...
- sharding-jdbc 分库分表的 4种分片策略,还蛮简单的
上文<快速入门分库分表中间件 Sharding-JDBC (必修课)>中介绍了 sharding-jdbc 的基础概念,还搭建了一个简单的数据分片案例,但实际开发场景中要远比这复杂的多,我 ...
- Sharding-JDBC分片策略详解(二)
一.分片策略 https://shardingsphere.apache.org/document/current/cn/features/sharding/concept/sharding/ Sha ...
- Elasticsearch 分片集群原理、搭建、与SpringBoot整合
单机es可以用,没毛病,但是有一点我们需要去注意,就是高可用是需要关注的,一般我们可以把es搭建成集群,2台以上就能成为es集群了.集群不仅可以实现高可用,也能实现海量数据存储的横向扩展. 新的阅读体 ...
- 【打分策略】Elasticsearch打分策略详解与explain手把手计算
一.目的 一个搜索引擎使用的时候必定需要排序这个模块,一般情况下在不选择按照某一字段排序的情况下,都是按照打分的高低进行一个默认排序的,所以如果正式使用的话,必须对默认排序的打分策略有一个详细的了解才 ...
- Elasticsearch 分片路由原理指定分片存储查询
Elasticsearch 项目中使用到Es的父子结构.在数据填充之后,查看每个节点的数据分布情况,发现有的节点数据多,有的节点少的情况,在未使用Es父级结构之前,每个节点的数据分布还算平均,如下图: ...
随机推荐
- spring中abstract bean的使用方法
什么是abstract bean?简单来说.就是在java中的继承时候,所要用到的父类. 案例文件结构: 当中Person类为父类.Student类为子类,其详细类为: package com.tes ...
- cocos2d-x的gitignore配置
# Ignore thumbnails created by windows Thumbs.db # Ignore files build by Visual Studio *.obj *.exe * ...
- python为在线漫画站点自制非官方API(未完待续)
接下来将记录我一步一步写一个非官方API的过程,由于一些条件的约束,最后的成品可能非常粗暴简陋 如今介绍要准备的全部工具: 系统:ubuntu 14.04 语言:python 2.7 须要自行安装的库 ...
- JavaScript或者Jqurey把控件id作为參数来调用
1.JavaScript把控件id作为參数调用 <script type="text/javascript"> function xx(pmba) { document ...
- perl的安装
http://www.activestate.com/activeperl/downloads 安装的时候,默认把perl放置到环境变量的PATH中 之后,需要重启电脑,确保环境变量生效 执行perl ...
- 国内物联网平台初探(三) ——QQ物联·智能硬件开放平台
平台定位 将QQ帐号体系.好友关系链.QQ消息通道及音视频服务等核心能力提供给可穿戴设备.智能家居.智能车载.传统硬件等领域的合作伙伴,实现用户与设备.设备与设备.设备与服务之间的联动. 实现用户与设 ...
- [JXOI 2018] 游戏 解题报告 (组合数+埃氏筛)
interlinkage: https://www.luogu.org/problemnew/show/P4562 description: solution: 注意到$l=1$的时候,$t(p)$就 ...
- H3BPM子表的复制
在做一个流程的时候,碰到了下面的表数据直接从上表中获取,并且为不可编辑状态,没有增加和删除行的按钮.一开始使用的是ComputationRule属性,但是有一项是日期空间,没有这个属性,不知道怎么处理 ...
- Java图片的压缩
1.如果在springMvc中,会自带生成MultipartFile文件,将MultipartFile转化为File MultipartFile file1 = file; CommonsMultip ...
- seo在前端网页制作的应用
学习了慕客网上的“SEO在网页制作中的应用‘’,下面来进行小小的学习总结,顺便梳理下知识.所谓学而不思则罔思而不学则殆.下面开始正文. 一.搜索引擎的工作原理 搜索引擎的基本工作原理包括如下三个过程: ...