LRU算法与LRUCache
关于LRU
LRU(Least recently used,最近最少使用)算法是操作系统中一种经典的页面置换算法,当发生缺页中断时,需要将内存的一个或几个页面置换出,LRU指出应该将内存最近最少使用的那些页面换出,依据的是程序的局部性原理,最近经常使用的页面再不久的将来也很有可能被使用,反之最近很少使用的页面未来也不太可能在使用。
其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”。但此算法不能保证过去不常用,将来也不常用。
设计目标
1、实现LRU算法。
2、学以致用,了解算法实际应用场景。
3、封装LRUCache数据结构。
4、实现线程安全与线程不安全两种版本LRUCache。
实际应用LRU
LRU算法非常实用,不仅在操作系统中发挥着很大作用,而且他还是一款缓存淘汰算法。
在做大型软件或网站服务时,如果想要让系统稳定并且能够承受得住千万级用户的高并发访问,就要尽量缩短因日常维护操作(计划)和突发的系统崩溃(非计划)所导致的停机时间,以提高系统和应用的可用性。那么我们必然要采取一些高可用的措施。
有人说互联网用户是用脚投票的,这句话其实也从侧面说明了,用户体验是多么的重要。这就要求在软件架构设计时,不但要注重可靠性、安全性、可扩展性以及可维护性等等的一些指标,更要注重用户的体验,用户体验分很多方面,但是有一点非常重要就是对用户操作的响应一定要快。怎样提高用户访问的响应速度,这就是摆在架构设计中必须要解决的问题。说道提高服务的响应速度就不得不说缓存了。
缓存有三种:数据库缓存、静态缓存和动态缓存。
从系统的层面说,CPU的速度远远高于磁盘IO的速度。所以要想提高响应速度,必须减少磁盘IO的操作,但是有很多信息又是存在数据库当中的,每次查询数据库就是一次IO操作。
在目前主流的memcache和redis中都有LRU算法的身影。在两大中间件中,LRU算法都在他们之中起到缓存回收的作用。关于他们的源码以后打算分析。
静态缓存:一般指 web 类应用中,将图片、js、css、视频、html等静态文件/资源通过磁盘/内存等缓存方式,提高资源响应方式,减少服务器压力/资源开销的一门缓存技术。静态缓存技术:CDN是经典代表之作。静态缓存技术面非常广,涉及的开源技术包含apache、Lighttpd、nginx、varnish、squid等。
动态缓存:用于临时文件交换,缓存是指临时文件交换区,电脑把最常用的文件从存储器里提出来临时放在缓存里,就像把工具和材料搬上工作台一样,这样会比用时现去仓库取更方便。
LRU算法过程
链表+容器实现LRU缓存
传统意义的LRU算法是为每一个Cache对象设置一个计数器,每次Cache命中则给计数器+1,而Cache用完,需要淘汰旧内容,放置新内容时,就查看所有的计数器,并将最少使用的内容替换掉。
它的弊端很明显,如果Cache的数量少,问题不会很大, 但是如果Cache的空间过大,达到10W或者100W以上,一旦需要淘汰,则需要遍历所有计算器,其性能与资源消耗是巨大的。
效率也就非常的慢了。
所以采用双向链表+hash表的数据结构实现,双向链表作为队列存储当前缓存节点,其中从表头到表尾的元素按照最近使用的时间进行排列,放在表头的是最近刚刚被使用过的元素,表尾的最近最少使用的元素;如果仅仅采用双向链表,那么查询某个元素需要 O(n) 的时间,为了加快双向链表中元素的查询速度,采用hash表讲key进行映射,可以在O(1)的时间内找到需要节点。
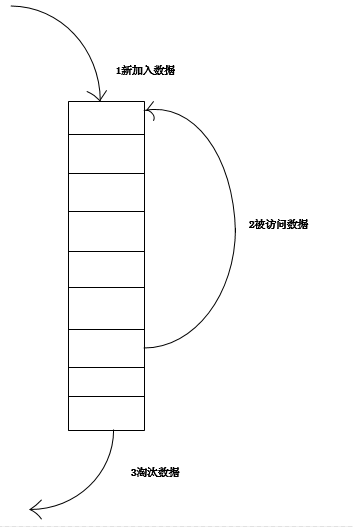
1. 新数据插入到链表头部;
2. 每当缓存命中(即缓存数据被访问),则将数据移到链表头部;
3. 当链表满的时候,将链表尾部的数据丢弃。
【命中率】
命中率=命中数/(命中数+没有命中数), 缓存命中率是判断加速效果好坏的重要因素之一。
当存在热点数据的时候,LRU效率很好,但偶发性、周期性的批量操作会导致LRU命中率急剧下滑,缓存污染的情况比较严重。

原理: 将Cache的所有位置都用双连表连接起来,当一个位置被命中之后,就将通过调整链表的指向,将该位置调整到链表头的位置,新加入的Cache直接加到链表头中。
这样,在多次进行Cache操作后,最近被命中的,就会被向链表头方向移动,而没有命中的,而想链表后面移动,链表尾则表示最近最少使用的Cache。
当需要替换内容时候,链表的最后位置就是最少被命中的位置,我们只需要淘汰链表最后的部分即可。
package com.zuo.lru; import java.util.HashMap; /**
*
* @author zuo
* 线程不安全
* @param <K>
* @param <V>
*/
public class LRUCache<K, V> { private int currentCacheSize; //当前缓存大小
private int CacheCapcity; //缓存上限
private HashMap<K, CacheNode> caches; //缓存表
private CacheNode first;
private CacheNode last; public LRUCache(int size) {
currentCacheSize=0;
this.CacheCapcity=size;
caches=new HashMap<K,CacheNode>(size);
} /**
* 添加
* @param k
* @param v
*/
public void put(K k,V v){
CacheNode node=caches.get(k);
if(node==null){
if(caches.size()>=CacheCapcity){
caches.remove(last.key);
removeLast();
}
node=new CacheNode();
node.key=k;
}
node.value=v;
moveToFirst(node);
caches.put(k, node);
} public Object get(K k){
CacheNode node=caches.get(k);
if(node==null){
return null;
}
moveToFirst(node);
return node.value;
} /**
* 删除
* @param k
* @return
*/
public Object remove(K k){
CacheNode node=caches.get(k);
if(node!=null){
if(node.pre!=null){
node.pre.next=node.next;//前结点的后指针指向当前节点的下一个
}
if(node.next!=null){
node.next.pre=node.pre;//后节点的前指针指向当前结点的上一个
}
if(node==first){
first=node.next;
}
if(node==last){
last=node.pre;
}
}
return caches.remove(k);
} /**
* 删除last
*/
private void removeLast(){
if(last!=null){
last=last.pre;
if(last==null){
first=null;
}else{
last.next=null;
}
}
} /**
* 将node移动到头说明使用频率高
* @param node
*/
private void moveToFirst(CacheNode node){
if(first==node){
return;
}
if(node.pre!=null){
node.pre.next=node.next;//前结点的后指针指向当前节点的下一个
}
if(node.next!=null){
node.next.pre=node.pre;//后节点的前指针指向当前结点的上一个
}
if(node==last){
last=last.pre;
}
if(first==null || last==null){
first=last=node;
return;
}
node.next=first;
first.pre=node;
first=node;
first.pre=null;
} /**
* 清空
*/
public void clear(){
first=null;
last=null;
caches.clear();
} @Override
public String toString() {
StringBuilder stringBuilder=new StringBuilder();
CacheNode node=first;
while(node!=null){
stringBuilder.append(String.format("%s:%s ", node.key,node.value));
node=node.next;
}
return stringBuilder.toString();
} /**
* @author zuo
* 双向链表
*/
class CacheNode{
CacheNode pre; //前指针
CacheNode next;//后指针
Object key; //键
Object value; //值
public CacheNode() {
}
} public int getCurrentCacheSize() {
return currentCacheSize;
} public static void main(String[] args) { LRUCache<Integer,String> lru = new LRUCache<Integer,String>(3); lru.put(1, "a"); // 1:a
System.out.println(lru.toString());
lru.put(2, "b"); // 2:b 1:a
System.out.println(lru.toString());
lru.put(3, "c"); // 3:c 2:b 1:a
System.out.println(lru.toString());
lru.put(4, "d"); // 4:d 3:c 2:b
System.out.println(lru.toString());
lru.put(1, "aa"); // 1:aa 4:d 3:c
System.out.println(lru.toString());
lru.put(2, "bb"); // 2:bb 1:aa 4:d
System.out.println(lru.toString());
lru.put(5, "e"); // 5:e 2:bb 1:aa
System.out.println(lru.toString());
lru.get(1); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(11); // 1:aa 5:e 2:bb
System.out.println(lru.toString());
lru.remove(1); //5:e 2:bb
System.out.println(lru.toString());
lru.put(1, "aaa"); //1:aaa 5:e 2:bb
System.out.println(lru.toString());
} }
线程安全与线程不安全
线程安全就是多线程访问时,采用了加锁机制,当一个线程访问该类的某个数据时,进行保护,其他线程不能进行访问直到该线程读取完,其他线程才可使用。不会出现数据不一致或者数据污染。
线程不安全就是不提供数据访问保护,有可能出现多个线程先后更改数据造成所得到的数据是脏数据。
package com.zuo.lru; import java.util.Iterator;
import java.util.LinkedHashMap;
import java.util.Map;
import java.util.Map.Entry; /**
* 线程安全
* @author zuo
*
*/
public class LRUCacheSafe <K,V>{ private final LinkedHashMap<K,V> map; private int currentCacheSize; //当前cache的大小
private int CacheCapcity; //cache最大大小
private int putCount; //put的次数
private int createCount; //create的次数
private int evictionCount; //回收的次数
private int hitCount; //命中的次数
private int missCount; //未命中次数 public LRUCacheSafe(int CacheCapcity){
if(CacheCapcity<=0){
throw new IllegalArgumentException("CacheCapcity <= 0");
}
this.CacheCapcity=CacheCapcity;
//将LinkedHashMap的accessOrder设置为true来实现LRU
this.map=new LinkedHashMap<K,V>(0,0.75f,true);//true 就是基于访问的顺序,get一个元素后,这个元素被加到最后(使用了LRU 最近最少被使用的调度算法)
} public final V get(K key){
if(key==null){
throw new NullPointerException("key == null");
}
V mapValue;
synchronized (this) {
mapValue=map.get(key);
if(mapValue!=null){
//mapValue 不为空表示命中,hitCount+1 并返回mapValue对象
hitCount++;
return mapValue;
}
missCount++;
}
//如果未命中,则试图创建一个对象,这里create方法放回null,并没有实现创建对象的方法
//如果需要事项创建对象的方法可以重写create方法。因为图片缓存时内存缓存没有命中会去文件缓存或者从网络下载,所以不需要创建。
V createValue=create(key);
if(createValue==null){
return null;
}
//假如创建了新的对象,则继续往下运行
synchronized (this) {
createCount++;
//将createValue加入到map中,并且将原来的key的对象保存到mapValue
mapValue=map.put(key, createValue);
if(mapValue!=null){
//如果mapValue不为空,则撤销上一步的put操作
map.put(key, mapValue);
}else{
//加入新创建的对象之后需要重新计算currentCacheSize大小
currentCacheSize+=safecurrentCacheSizeOf(key, createValue);
}
}
if(mapValue!=null){
entryRemoved(false, key, createValue, mapValue);
return mapValue;
}else{
//每次新加入对象都需要调用trimTocurrentCacheSize方法看是否回收
trimTocurrentCacheSize(CacheCapcity);
return createValue;
}
} /**
* 此方法根据CacheCapcity来调整cache的大小,如果CacheCapcity传入-1,则清空缓存中的的大小
* @param CacheCapcity
*/
private void trimTocurrentCacheSize(int CacheCapcity){
while(true){
K key;
V value;
synchronized (this) {
if(currentCacheSize<0||(map.isEmpty() && currentCacheSize!=0)){
throw new IllegalStateException(getClass().getName()
+ ".currentCacheSizeOf() is reporting inconsistent results!");
}
//如果当前currentCacheSize小于CacheCapcity或者map没有任何对象,则循环结束
if(currentCacheSize<=CacheCapcity || map.isEmpty()){
break;
}
//移除链表头部的元素,并进入下一次循环
Map.Entry<K, V> toEvict =map.entrySet().iterator().next();
key=toEvict.getKey();
value=toEvict.getValue();
map.remove(key);
currentCacheSize-=safecurrentCacheSizeOf(key, value);
evictionCount++;//回收次数++
}
entryRemoved(true, key, value, null);
}
} public final V put(K key,V value){
if(key==null||value==null){
throw new NullPointerException("key == null || value == null");
}
V previous;
synchronized (this) {
putCount++;
currentCacheSize+=safecurrentCacheSizeOf(key, value);//currentCacheSize加上预put对象大小
previous=map.put(key, value);
if(previous!=null){
//如果之前存在键为key的对象,则currentCacheSize应该减去原来对象的大小
currentCacheSize-=safecurrentCacheSizeOf(key, previous);
}
}
if(previous!=null){
entryRemoved(false, key, previous, value);
}
//每次新加入的对象都需要调用trimtocurrentCacheSize方法看是否要回收
trimTocurrentCacheSize(CacheCapcity);
return previous;
} /**
* 从内存缓存中根据key值移除某个对象并返回该对象
* @param key
* @return
*/
public final V remove(K key){
if(key==null){
throw new NullPointerException("key == null");
}
V previous;
synchronized (this) {
previous=map.remove(key);
if(previous!=null){
currentCacheSize-=safecurrentCacheSizeOf(key, previous);
}
}
if(previous!=null){
entryRemoved(false, key, previous, null);
}
return previous;
} /**
* 在高速缓存未命中之后调用以计算对应键的值
* @param key
* @return 如果没有计算值,则返回计算值或NULL
*/
protected V create(K key) {
return null;
} private int safecurrentCacheSizeOf(K key,V value){
int result=currentCacheSizeOf(key, value);
if(result<0){
throw new IllegalStateException("Negative currentCacheSize: " + key + "=" + value);
}
return result;
} /**
* 用来计算单个对象的大小,这里默认返回1
* @param key
* @param value
* @return
*/
protected int currentCacheSizeOf(K key,V value) {
return 1;
} protected void entryRemoved(boolean evicted,K key,V oldValue,V newValue) {} /**
* 清空内存缓存
*/
public final void evictAll(){
trimTocurrentCacheSize(-1);
} /**
* 当前cache大小
* @return
*/
public synchronized final int currentCacheSize(){
return currentCacheSize;
}
/**
* 命中次数
* @return
*/
public synchronized final int hitCount(){
return hitCount;
}
/**
* 未命中次数
* @return
*/
public synchronized final int missCount(){
return missCount;
}
/**
* create次数
* @return
*/
public synchronized final int createCount(){
return createCount;
}
/**
* put次数
* @return
*/
public synchronized final int putCount(){
return putCount;
}
/**
* 回收次数
* @return
*/
public synchronized final int evictionCount(){
return evictionCount;
}
/**
* 返回一个当前缓存内容的副本
* @return
*/
public synchronized final Map<K, V> snapshot(){
return new LinkedHashMap<K,V>(map);
} @Override
public synchronized final String toString() {
int accesses =hitCount+missCount;
int hitPercent=accesses!=0?(100 * hitCount/accesses):0;//缓存命中率是判断加速效果好坏的重要因素
Iterator<Entry<K, V>> iterator= map.entrySet().iterator();
while(iterator.hasNext())
{
Entry<K, V> entry = iterator.next();
System.out.println(entry.getKey()+":"+entry.getValue());
}
return String.format("LruCache[缓存最大大小=%d,命中次数=%d,未命中次数=%d,命中率=%d%%]",
CacheCapcity, hitCount, missCount, hitPercent);
} public static void main(String[] args) { LRUCacheSafe<Integer,String> lru = new LRUCacheSafe<Integer,String>(3);
System.out.println("--------------------开始使用LRU缓存---------------"); lru.put(1, "7");
System.out.println(lru.toString());
lru.put(2, "0");
System.out.println(lru.toString());
lru.put(3, "1");
System.out.println(lru.toString());
lru.put(4, "2");
System.out.println(lru.toString());
lru.put(1, "0");
System.out.println(lru.toString());
lru.put(2, "3");
System.out.println(lru.toString());
lru.put(5, "0");
System.out.println(lru.toString());
lru.put(6, "4");
System.out.println(lru.toString());
lru.put(7, "2");
System.out.println(lru.toString());
lru.put(8, "3");
System.out.println(lru.toString());
lru.put(9, "0");
System.out.println(lru.toString());
lru.put(10, "3");
System.out.println(lru.toString());
lru.put(11, "2");
System.out.println(lru.toString());
lru.put(12, "1");
System.out.println(lru.toString());
lru.put(13, "2");
System.out.println(lru.toString());
lru.put(14, "0");
System.out.println(lru.toString());
lru.put(15, "1");
System.out.println(lru.toString());
lru.put(16, "7");
System.out.println(lru.toString());
lru.put(17, "0");
System.out.println(lru.toString());
lru.put(18, "1");
System.out.println(lru.toString());
lru.get(1);
lru.get(18);
lru.get(2);
System.out.println(lru.toString());
lru.remove(16);
System.out.println(lru.toString());
} }
LRU算法与LRUCache的更多相关文章
- Android图片缓存之Lru算法
前言: 上篇我们总结了Bitmap的处理,同时对比了各种处理的效率以及对内存占用大小.我们得知一个应用如果使用大量图片就会导致OOM(out of memory),那该如何处理才能近可能的降低oom发 ...
- 缓存淘汰算法--LRU算法
1. LRU1.1. 原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是"如果数据最近被访问过,那么将来被访问的几率也 ...
- LinkedHashMap 和 LRU算法实现
个人觉得LinkedHashMap 存在的意义就是为了实现 LRU 算法. public class LinkedHashMap<K,V> extends HashMap<K,V&g ...
- 简单LRU算法实现缓存
最简单的LRU算法实现,就是利用jdk的LinkedHashMap,覆写其中的removeEldestEntry(Map.Entry)方法即可,如下所示: java 代码 import java.ut ...
- LRU算法的设计
一道LeetCode OJ上的题目,要求设计一个LRU(Least Recently Used)算法,题目描述如下: Design and implement a data structure for ...
- LRU算法总结
LRU算法总结 无论是哪一层次的缓存都面临一个同样的问题:当容量有限的缓存的空闲空间全部用完后,又有新的内容需要添加进缓存时,如何挑选并舍弃原有的部分内容,从而腾出空间放入这些新的内容.解决这个问题的 ...
- 【算法】—— LRU算法
LRU原理 LRU(Least recently used,最近最少使用)算法根据数据的历史访问记录来进行淘汰数据,其核心思想是“如果数据最近被访问过,那么将来被访问的几率也更高”. 实现1 最常见的 ...
- GuavaCache学习笔记一:自定义LRU算法的缓存实现
前言 今天在看GuavaCache缓存相关的源码,这里想到先自己手动实现一个LRU算法.于是乎便想到LinkedHashMap和LinkedList+HashMap, 这里仅仅是作为简单的复习一下. ...
- LRU 算法
LRU算法 很多Cache都支持LRU(Least Recently Used)算法,LRU算法的设计原则是:如果一个数据在最近一段时间没有被访问到,那么在将来它被访问的可能性也很小.也就是说,当限定 ...
随机推荐
- node.js流复制文件
转自:http://segmentfault.com/a/1190000000519006 nodejs的fs模块并没有提供一个copy的方法,但我们可以很容易的实现一个,比如: var source ...
- Hello World Spring MVC
1, Setup Development Environment 1.1, Java SDK | ~ @ yvan-mac (yvan) | => java -version java vers ...
- 利用PBFunc在Powerbuilder中进行图片格式转换
利用PBFunc的n_pbfunc_image对象可以方便的进行图片格式的转换与大小转换 支持相互转换的格式有以下几种: FORMAT_BMP //bmp格式FORMAT_GIF //gif格式FO ...
- C语言-统计数字、字母、特殊字符
Action() { //统计字符019aBcd8***,4,4,3 int i,z,t; char *str="019aBcd8***"; fun_Count(str,i,z,t ...
- Visual Studio icon 含义
图片摘自:https://msdn.microsoft.com/en-us/library/y47ychfe.aspx
- Unity 移动键Q的三种用法 For Mac,Windows类同
拖动整个场景:三指 (任何模式下)ALT+三指:旋转当前镜头 (任何模式下)双指前后滑动:缩放镜头 ps1:Q键移动的游戏场景,W移动的是游戏对象 ps2:三指 = 左键拖动
- HDU 1575 Tr A( 简单矩阵快速幂 )
链接:传送门 思路:简单矩阵快速幂,算完 A^k 后再求一遍主对角线上的和取个模 /********************************************************** ...
- 51nod 1301 集合异或和(DP)
因为当\(A<B\)时,会存在在二进制下的一位,满足这一位B的这一位是\(1\),\(A\)的这一位是\(0\). 我们枚举最大的这一位.设为\(x\)吧. 设计状态.\(dp[i][j][1/ ...
- hdu 1693 插头dp入门
hdu1693 Eat the Trees 题意 在\(n*m\)的矩阵中,有些格子有树,没有树的格子不能到达,找一条或多条回路,吃完所有的树,求有多少种方法. 解法 这是一道插头dp的入门题,只需要 ...
- GROUP BY 与聚合函数 使用注意点
表的设计: 表里面的内容: 一:在不使用聚合函数的时候,group by 子句中必须包含所有的列,否则会报错,如下 select name,MON from [测试.] group by name 会 ...