6、DRN-----深度强化学习在新闻推荐上的应用
1、摘要:
提出了一种新的深度强化学习框架的新闻推荐。由于新闻特征和用户喜好的动态特性,在线个性化新闻推荐是一个极具挑战性的问题。
虽然已经提出了一些在线推荐模型来解决新闻推荐的动态特性,但是这些方法主要存在三个问题:①只尝试模拟当前的奖励(eg:点击率)②很少考虑使用除了点击 / 不点击标签之外的用户反馈来帮助改进推荐。③ 这些方法往往会向用户推荐类似消息,这可能会导致用户感到厌烦。
基于深度强化学习的推荐框架,该框架可以模拟未来的奖励(点击率)
2、引言:
新闻推荐三个问题:
(1)新闻推荐的动态变化是难以处理的。
(2)用户的兴趣可能随着时间的变化而变化。
(3)创新
强化学习:假定一个智能体(agent),在一个未知的环境中(当前状态state),采取了一个行动(action),然后收获了一个回报(reward),并进入了下一个状态。最终目的是求解一个策略让agent的回报最大化。
因此,本文提出了基于深度强化学习的推荐系统框架来解决上述提到的三个问题:
(1)首先,使用DQN网络来有效建模新闻推荐的动态变化属性,DQN可以将短期回报和长期回报进行有效的模拟。
(2)将用户活跃度作为一种新的反馈信息。
(3)使用Dueling Bandit Gradient Descent 方法来进行有效的探索。
算法的框架如下图所示:
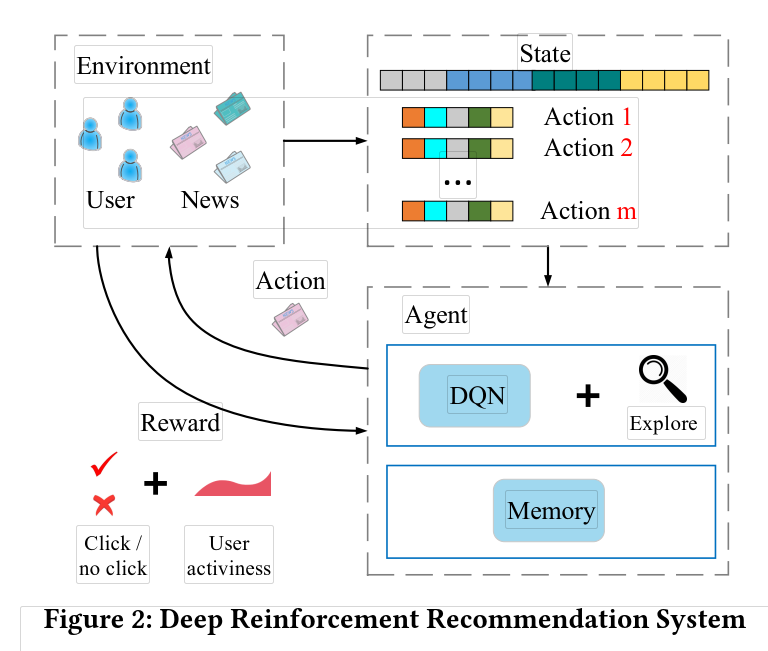
3、问题描述:
当一个用户 u 在时间 t 向推荐系统 G 发送一个新闻请求,系统会利用一个给定的新闻候选集 I 给用户推荐一个 top-k 列表给用户。
4、模型方法:
4.1 整体架构图:
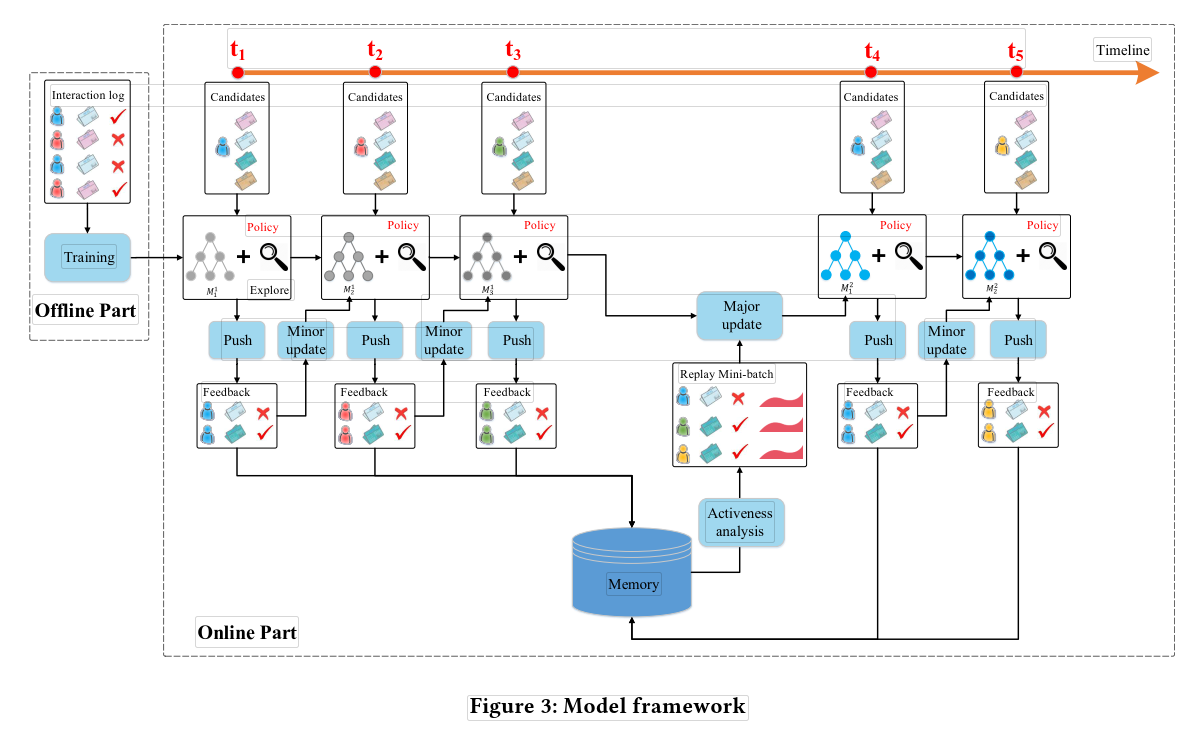
几个关键环节:
push:在每一个时刻,用户发送请求时,agent根据当前的state产生k篇新闻推荐给用户。
Feedback:通过用户对推荐新闻的点击行为得到反馈结果。
minor update:在每个时间点过后,根据用户的信息(state)和推荐的新闻(action)以及得到的反馈(reward),更新参数。
major update:在一段时间后,根据DQN的经验池中存放的历史经验,对模型参数进行更新。
6、DRN-----深度强化学习在新闻推荐上的应用的更多相关文章
- 一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm)
一文读懂 深度强化学习算法 A3C (Actor-Critic Algorithm) 2017-12-25 16:29:19 对于 A3C 算法感觉自己总是一知半解,现将其梳理一下,记录在此,也 ...
- (转) 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文)
本文转自:http://mp.weixin.qq.com/s/aAHbybdbs_GtY8OyU6h5WA 专题 | 深度强化学习综述:从AlphaGo背后的力量到学习资源分享(附论文) 原创 201 ...
- 深度强化学习(Deep Reinforcement Learning)入门:RL base & DQN-DDPG-A3C introduction
转自https://zhuanlan.zhihu.com/p/25239682 过去的一段时间在深度强化学习领域投入了不少精力,工作中也在应用DRL解决业务问题.子曰:温故而知新,在进一步深入研究和应 ...
- 深度强化学习(DRL)专栏(一)
目录: 1. 引言 专栏知识结构 从AlphaGo看深度强化学习 2. 强化学习基础知识 强化学习问题 马尔科夫决策过程 最优价值函数和贝尔曼方程 3. 有模型的强化学习方法 价值迭代 策略迭代 4. ...
- 深度强化学习(DRL)专栏开篇
2015年,DeepMind团队在Nature杂志上发表了一篇文章名为"Human-level control through deep reinforcement learning&quo ...
- 深度强化学习中稀疏奖励问题Sparse Reward
Sparse Reward 推荐资料 <深度强化学习中稀疏奖励问题研究综述>1 李宏毅深度强化学习Sparse Reward4 强化学习算法在被引入深度神经网络后,对大量样本的需求更加 ...
- 【资料总结】| Deep Reinforcement Learning 深度强化学习
在机器学习中,我们经常会分类为有监督学习和无监督学习,但是尝尝会忽略一个重要的分支,强化学习.有监督学习和无监督学习非常好去区分,学习的目标,有无标签等都是区分标准.如果说监督学习的目标是预测,那么强 ...
- 深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO)
深度学习课程笔记(十四)深度强化学习 --- Proximal Policy Optimization (PPO) 2018-07-17 16:54:51 Reference: https://b ...
- 深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods)
深度学习课程笔记(十三)深度强化学习 --- 策略梯度方法(Policy Gradient Methods) 2018-07-17 16:50:12 Reference:https://www.you ...
随机推荐
- POJ.grids.2980
题目链接:http://bailian.openjudge.cn/practice/2980 解题思路:先将对应位相乘的积累加,最后再来处理进位问题:如 835*49: 先做 835*9: 得到 i ...
- Html5必看:教你如何选择移动APP开发框架
如何选择移动APP开发框架一直是困扰很多新手的难题,今天杭州APP开发小编就和大家一起分享一下HTML5 移动app开发过程中框架该如何选择?当然我们得先从下面几个方面来评估一个框架的优越性,然后再做 ...
- webpack安装,npm WARN optional SKIPPING OPTIONAL DEPENDENCY,npm WARN notsup SKIPPING OPTIONAL DEPENDENCY警告
npm install webpack -g//全局安装webpack 电脑上安装完后: 其中有两个警告: npm WARN optional SKIPPING OPTIONAL DEPENDENCY ...
- P3376 【模板】网络最大流(luogu)
P3376 [模板]网络最大流(luogu) 最大流的dinic算法模板(采取了多种优化) 优化 时间 inline+当前弧+炸点+多路增广 174ms no 当前弧 175ms no 炸点 249 ...
- How Google Backs Up The Internet Along With Exabytes Of Other Data
出处:http://highscalability.com/blog/2014/2/3/how-google-backs-up-the-internet-along-with-exabytes-of- ...
- js 获取对象长度
获取对象的程度,可以这样获取: var myObj = {a:1,b:2,c:3} var arr = Object.keys(myObj);var len = arr.length console ...
- 利用after和before伪类实现chrome浏览器tab选项卡斜边纯css无图制作笔记
<!DOCTYPE html><html lang="en"><head> <meta charset="UTF-8" ...
- 数字签名技术与https
1,非对称加密技术 非对称加密算法需要两个密钥,公开密钥(publickey)和私有密钥(privatekey):公钥和私钥是成对出现的. 非对称加密例子:B想把一段信息传给A,步骤:1)A把公钥传给 ...
- 2015 Multi-University Training Contest 5 hdu 5348 MZL's endless loop
MZL's endless loop Time Limit: 3000/1500 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Oth ...
- android 联系人中,在超大字体下,加入至联系人界面(ConfirmAddDetailActivity)上有字体显示不全的问题
联系人(Contacts)中,在超大字体下.加入至联系人界面 (ConfirmAddDetailActivity)上有字母显示不全,如"j"等 这是android布局比較紧凑引起的 ...