MapReduce架构与生命周期
MapReduce架构与生命周期
概述:MapReduce是hadoop的核心组件之一,可以通过MapReduce很容易在hadoop平台上进行分布式的计算编程。本文组织结果如下:首先对MapReduce架构和基本原理进行概述,其次对整个MapReduce过程的生命周期进行详细讨论。
参考文献:董西城的《Hadoop技术内幕》以及若干论坛文章,无法考证出处。
MapReduce架构和基本原理概述
MapReduce主要分为Map和Reduce两个过程,采用了M/S的设计架构。在1.0系列中,主要角色包括:Client, JobTracke, TaskTracker和Task
Client:用户需要执行的Job在Client进行配置,例如编写MapReduce程序,指定输入输出路径,指定压缩比例等等,配置好后,由客户端提交给JobTracker。每个作业Job会被分成若干个任务Task。
- JobTracker: 主要负责作业的调度和资源的监控,同时也对Client提供接口,使用户可以查看Job运行状态。
- JobTracker需要对Client提交的作业进行初始化并分配给TaskTracker,与TaskTracker通信,协调整个作业。TaskTracker和JobTracker之间的通信与任务的分配是通过心跳机制完成的。TaskTracker会主动向JobTracker询问是否有作业要做,如果自己可以做,那么就会申请到作业任务,这个任务可以使Map也可能是Reduce任务。如果发现任务失败,就会将该任务转移到其他节点上执行。
- TaskTracker:保持JobTracker通信,周期性的通过心跳机制来将本节点上的资源使用情况和任务执行情况报告给JobTracker,同时接受JobTracker发送过来的命令,例如启动任务,终结任务等等。TaskTracker使用slot来等量划分本节点上的资源(CPU,内存),当一个Task得到分配的slot后才能运行。节点上的slot可分为Mapslot和Redcueslot,分别分配给MapTask和ReduceTask。另外,TaskTracker通过slot的分配限制task的并发度。
- Task:Task可以分为MapTask和ReduceTask,分别对应于Map过程和Reduce过程,由TaskTracker启动。根据配置的split的数量来决定MapTask的数目。
在整个MapReduce执行过程中,数据需要经过Mapper,中间过程shuffle,Reducer的处理。
Mapper
Mapper主要执行MapTask,将分配给它的split解析为若干个K-V对作为map函数的输入。例如在Wordcount程序中,K=字符串偏移量,V=一行字符串。然后依次调用map()进行处理,输出仍为K-V对。此时<K=word,V=1>。

中间过程shuffle
中间过程也分为Map端和Reduce端执行
Mapper端
在mapper端,每个Map Task都有一个内存缓冲区,存储着map函数的输出结果,当缓冲区快满的时候需要将缓冲区的数据以一个临时文件的方式存放到磁盘,当整个Map Task结束后再对磁盘中这个Map Task产生的所有临时文件做合并,生成最终的正式输出文件,然后等待reduce task来拉取数据。
Partition
Partitioner根据map函数输出的K-V对以及Reduce Task的数量来决定当前这对Map输出的K-V由哪个Reduce Task来处理。首先对key进行hash运算,再以Reduce task的数量对它取模;取模是为了平均Reduce的处理能力,也可以定制并设置到规定job上。
Spill
对于map()函数的输出数据K-V对,要写入内存缓冲区,该内存缓冲区的作用是批量收集Map结果,减少IO的影响。再写入磁盘文件。将K-V对序列化为字节数组,然后将K-V对以及partition的分组结果写入缓冲区。该缓冲区是有大小默认限制为100M,所以当Map任务输出结果过多时,需要对缓冲进行刷新,将数据写入磁盘。向磁盘写数据的过程称为Spill,意为溢写,由单独的进程完成,不影响Map结果写入的线程操作。为了达到这个目的,通过设置溢写比例spill.percent(默认0.8)来实现,即当缓冲区中数据达到80%,就启动Spill进程,锁定这80%的缓冲,进行溢写过程;与此同时,其他线程可以继续将Map的输出结果写入到剩下20%的缓冲区中,互不影响。
Sort
Spill线程启动后,需要对将要写入磁盘的数据进行处理,对已经序列化为字节的key进行排序。由于Map任务的结果要交给不同Reduce任务来处理,所以需要将交个同一个Reduce任务的数据合并在一起。这个合并过程在写入缓冲区时并未执行,而是由Spill进程在写入到磁盘时进行合并。如果有很多的K-V对需要提交给一个Reduce任务,那么应该将这些K-V进行拼接,减少与partitioner相关的索引记录。<K=word, V=1,V=1,V=1>
Merge
每次Spill进行溢写操作,都会在磁盘上产生一个溢写文件。如果缓冲区不够大或者Map输出结果很大,那么会多次执行溢写文件。所以需要将这些溢写文件归并为一个文件,该过程称为Merge。Merge所做的操作就是将来自不同map task结果中,key相同的K-V归并为组,形成K-[v1,v2,v…]。因为是将多个文件合并为一个文件,所以可能也有相同的Key存在,如果在client端设置过combiner,则会调用他来合并相同的Key。
至此,Map端的工作全部结束,最后这个文件放在TaskTracker能够获取到的本地目录内,每个reduce task不断通过RPC从JobTracker处获取map任务是否完成的信息,如果获知某台Tasktracker上的map任务完成,则shuffle过程后半段开始启动。

Reducer端
在Reduce端的中间过程,就是在reduce执行之前所进行的工作,不断将各个map输出的最终结果进行拉取,然后进行merge操作。
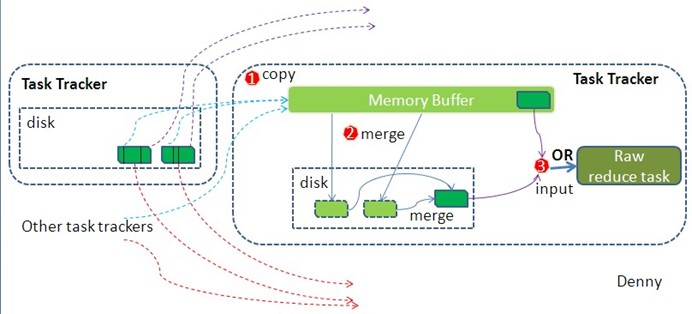
Copy
简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求map task所在的TaskTracker获取map task的输出文件。因为map task早已结束,这些文件就归TaskTracker管理在本地磁盘中。
Merge
这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活,它基于JVM的heap size设置,因为Shuffle阶段Reducer不运行,所以应该把绝大部分的内存都给Shuffle用。这里需要强调的是,merge有三种形式:1)内存到内存 2)内存到磁盘 3)磁盘到磁盘。默认情况下第一种形式不启用。同样的要在内存进行sort操作。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的那个文件。
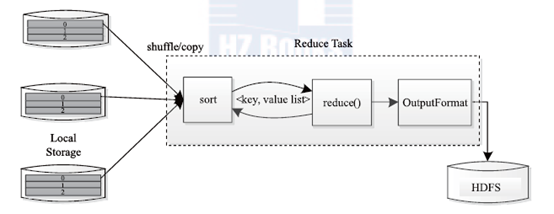
Reducer
Reduce Task 读取中间过程shuffle产生并放在HDFS上的最终文件,不断地调用reduce()函数来处理输入数据,该输入数据格式为<K=word,V=n,V=m…>,最后输出到HDFS上。
MapReduce作业的生命周期
本节对MapReduce作业的处理过程从提交到完成进行概述。作业处理的整个流程包括:
作业提交与初始化→任务调度与监控→运行环境准备→任务的执行→任务结束
- 作业的提交与初始化
用户需要执行的作业在客户端进行配置,例如编写MapReduce程序,指定输入输出路径,指定压缩比例等等,配置好后,由客户端提交给JobTracker。用户提交作业后,首先由JobClient 实例将作业相关信息(比如将程序jar 包、作业配置文件、分片元信息文件等)上传到HDFS上,其中,分片元信息文件记录了每个输入分片的逻辑位置信息。然后JobClient通过RPC 通知JobTracker。JobTracker 收到新作业提交请求后,由作业调度模块对作业进行初始化:为作业创建一个JobInProgress 对象以跟踪作业运行状况,而JobInProgress 则会为每个Task 创建一个TaskInProgress 对象以跟踪每个任务的运行状态,TaskInProgress 可能需要管理多个"Task Attempt"
- 任务调度与监控
TaskTracker 周期性地通过Heartbeat 向JobTracker 汇报本节点的资源使用情况,一旦出现空闲资源,JobTracker 会按照一定的策略选择一个合适的任务使用该空闲资源,这由任务调度器完成。任务调度器是一个可插拔的独立模块,且为双层架构,即首先选择作业,然后从该作业中选择任务,其中,选择任务时需要重点考虑数据本地性。此外,JobTracker 跟踪作业的整个运行过程,并为作业的成功运行提供全方位的保障。首先,当TaskTracker 或者Task 失败时,转移计算任务;其次,当某个Task 执行进度远落后于同一作业的其他Task 时,为之启动一个相同Task,并选取计算快的Task 结果作为最终结果。
- 任务运行环境准备
运行环境准备包括JVM 启动和资源隔离, 均由TaskTracker 实现。TaskTracker 为每个Task 启动一个独立的JVM 以避免不同Task 在运行过程中相互影响;同时,TaskTracker 使用了操作系统进程实现资源隔离以防止Task 滥用资源。
- 任务的执行
TaskTracker 为Task 准备好运行环境后,便会启动Task。在运行过程中,每个Task 的最新进度首先由Task 通过RPC 汇报给TaskTracker,再由TaskTracker汇报给JobTracker。
- 任务结束
JobTracker在接受到最后一个任务运行完成后,会将任务标志为成功。此时会做删除中间结果等善后处理工作。
本文简单讨论总结了MapReduce的架构和作业的生命周期,如果有错误之处,还望指正。
MapReduce架构与生命周期的更多相关文章
- 深入剖析PHP7内核源码(一)- PHP架构与生命周期
PHP7 为什么这么快? 全新的zval 更节约的空间,栈上分配内存 zend_string 存储字符串的Hash值,数组查询的时候不需要进行Hash计算 在HashTable桶内直接存数据,减少了内 ...
- Elastic 使用索引生命周期管理实现热温冷架构
Elastic: 使用索引生命周期管理实现热温冷架构 索引生命周期管理 (ILM) 是在 Elasticsearch 6.6(公测版)首次引入并在 6.7 版正式推出的一项功能.ILM 是 Elast ...
- IOS学习1——IOS应用程序的生命周期及基本架构
一.应用程序的状态和多任务 有时系统会从app一种状态切换另一种状态来响应系统发生的事件.例如,当用户按下home键.电话打入.或其他中断发生时,当前运行的应用程序会切换状态来响应.应用程序的状态有以 ...
- ASP.NET Core Web API下事件驱动型架构的实现(二):事件处理器中对象生命周期的管理
在上文中,我介绍了事件驱动型架构的一种简单的实现,并演示了一个完整的事件派发.订阅和处理的流程.这种实现太简单了,百十行代码就展示了一个基本工作原理.然而,要将这样的解决方案运用到实际生产环境,还有很 ...
- Jetpack 架构组件 Lifecycle 生命周期 MD
Markdown版本笔记 我的GitHub首页 我的博客 我的微信 我的邮箱 MyAndroidBlogs baiqiantao baiqiantao bqt20094 baiqiantao@sina ...
- SpringMVC内容略多 有用 熟悉基于JSP和Servlet的Java Web开发,对Servlet和JSP的工作原理和生命周期有深入了解,熟练的使用JSTL和EL编写无脚本动态页面,有使用监听器、过滤器等Web组件以及MVC架构模式进行Java Web项目开发的经验。
熟悉基于JSP和Servlet的Java Web开发,对Servlet和JSP的工作原理和生命周期有深入了解,熟练的使用JSTL和EL编写无脚本动态页面,有使用监听器.过滤器等Web组件以及MVC架构 ...
- 浅读tomcat架构设计之tomcat生命周期(2)
浅读tomcat架构设计和tomcat启动过程(1) https://www.cnblogs.com/piaomiaohongchen/p/14977272.html tomcat通过org.apac ...
- React生命周期和响应式原理(Fiber架构)
注意:只有类组件才有生命周期钩子函数,函数组件没有生命周期钩子函数. 生命周期 装载阶段:constructor() render() componentDidMount() 更新阶段:render( ...
- Unity应用架构设计(3)——构建View和ViewModel的生命周期
对于一个View而言,本质上是一个MonoBehaviour.它本身就具备生命周期这个概念,比如,Awake,Start,Update,OnDestory等.这些是非常好的方法,可以让开发者在各个阶段 ...
随机推荐
- 作业08之《MVC实现用户权限》
1. 赋给用户一个userid,在用户角色表将用户和角色关联起来,在角色权限表中将角色和权限对应起来,权限表中存储的是左边菜单栏的名称. 2. 在判断权限时,通过用户的userid,获取其角色id,然 ...
- (转)Bootstrap 之 Metronic 模板的学习之路 - (4)源码分析之脚本部分
https://segmentfault.com/a/1190000006709967 上篇我们将 body 标签主体部分进行了简单总览,下面看看最后的脚本部门. 页面结尾部分(Javascripts ...
- python tips:类的专有属性
实例通常能够调用类的属性,但是有些属性是类专有的,实例无法调用. 实例调用方法时查找属性时,首先在自己的__dict__中找,找不到去类中找,在类中能够找到的属性都位于dir(cls)中,如果类的某些 ...
- jsp+servlet 导出Excel表格
1.项目的目录结构 2.创建一个用户类,下面会通过查询数据库把数据封装成用户实例列表 package csh.entity; /** * @author 悦文 * @create 2018-10-24 ...
- SUSE 11 SP3 搭建weblogic服务
环境的搭建和业务需求相关,仅供参考 环境: SUSE 11 SP3 安装步骤 创建一个weblogic组 创建一个用户名为weblogic的用户, 创建相关目录 上传jdk,脚本等 安装 创建用户及其 ...
- eas左树右表基础资料界面引用为左树右表F7的简单方法
age: /** * 加载配件F7(左树右表) * @param F7Filed 要加载的F7控件 * @param ctx 界面上下文 * @单据 ...
- codeforces 467C George and Job(简单dp,看了题解抄一遍)
题目 参考了网页:http://www.xue163.com/exploit/180/1802901.html //看了题解,抄了一遍,眼熟一下,增加一点熟练度 //dp[i][j]表示是前i个数选出 ...
- 软件工程1916|W(福州大学)_助教博客】团队Beta冲刺作业(第9次)成绩公示
1. 作业链接: 项目Beta冲刺(团队) 2. 评分准则: 本次作业包括现场Beta答辩评分(映射总分为100分)+团队互评分数(总分40分)+博客分(总分130分)+贡献度得分,其中博客分由以下部 ...
- qbxt 考前集训 Day1
立方数(cubic) Time Limit:1000ms Memory Limit:128MB 题目描述 LYK定义了一个数叫“立方数”,若一个数可以被写作是一个正整数的3次方,则这个数就是立方数 ...
- Ubuntu Server下docker实战 02: docker进阶配置
在上一篇文章里<Ubuntu Server下docker实战 01: 安装docker>,我们已经把docker安装起来了,并运行了一个hello-world 这一篇,我们继续讲进阶配置. ...