大数据学习——spark运营案例
iplocation需求
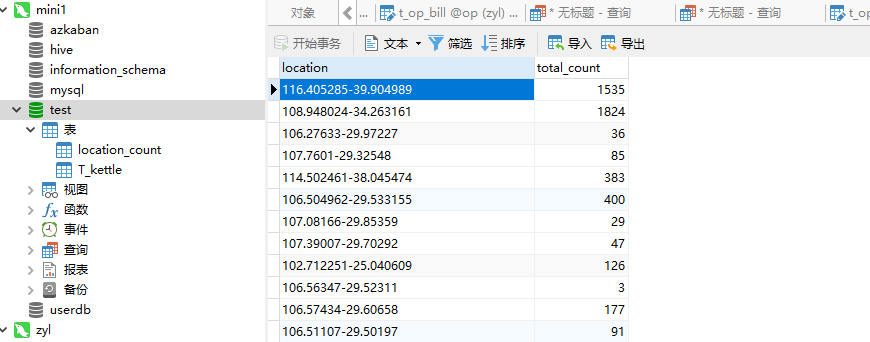
在互联网中,我们经常会见到城市热点图这样的报表数据,例如在百度统计中,会统计今年的热门旅游城市、热门报考学校等,会将这样的信息显示在热点图中。
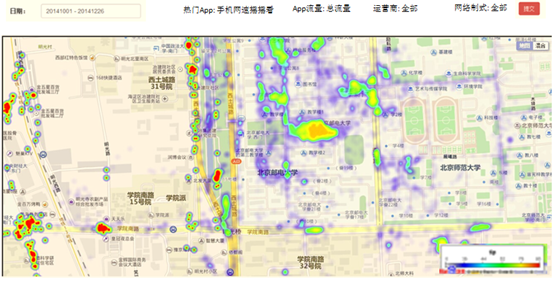
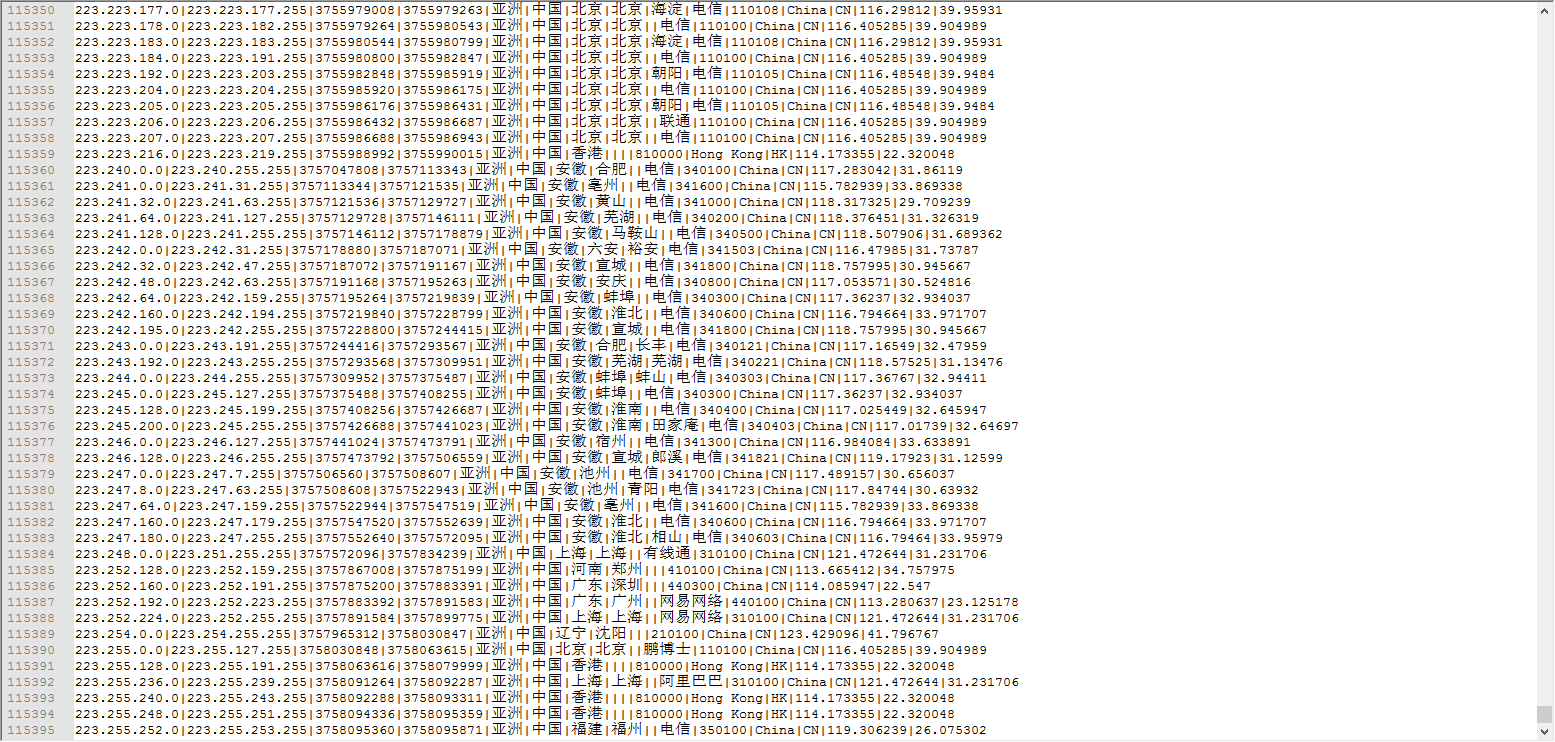
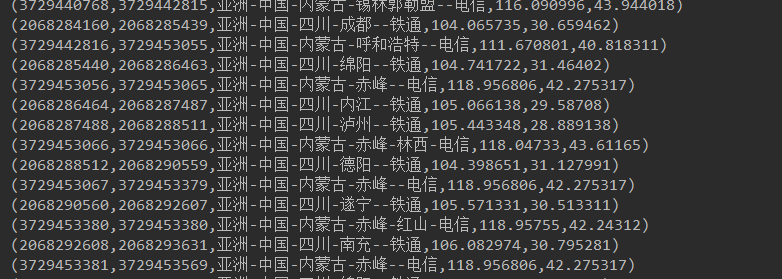
因此,我们需要通过日志信息(运行商或者网站自己生成)和城市ip段信息来判断用户的ip段,统计热点经纬度。
练习数据
链接:https://pan.baidu.com/s/14IA1pzUWEnDK_VCH_LYRLw
提取码:pnwv
package org.apache.spark import org.apache.spark.broadcast.Broadcast
import org.apache.spark.rdd.RDD
import java.io.{BufferedReader, FileInputStream, InputStreamReader}
import java.sql.{Connection, DriverManager, PreparedStatement} import org.apache.spark.{SparkConf, SparkContext} import scala.collection.mutable.ArrayBuffer /**
* Created by Administrator on 2019/6/12.
*/
object IPLocation {
def ip2Long(ip: String): Long = {
//ip转数字口诀
//分金定穴循八卦,toolong插棍左八圈
val split: Array[String] = ip.split("[.]")
var ipNum = 0L
for (i <- split) {
ipNum = i.toLong | ipNum << 8L
}
ipNum
} //二分法查找
def binarySearch(ipNum: Long, value: Array[(String, String, String, String, String)]): Int = {
//上下循环循上下,左移右移寻中间
var start = 0
var end = value.length - 1
while (start <= end) {
val middle = (start + end) / 2
if (ipNum >= value(middle)._1.toLong && ipNum <= value(middle)._2.toLong) {
return middle
}
if (ipNum > value(middle)._2.toLong) {
start = middle
}
if (ipNum < value(middle)._1.toLong) {
end = middle
}
}
-1
} def data2MySQL(iterator: Iterator[(String, Int)]): Unit = {
var conn: Connection = null
var ps: PreparedStatement = null
val sql = "INSERT INTO location_count (location, total_count) VALUES (?, ?)"
try {
conn = DriverManager.getConnection("jdbc:mysql://192.168.74.100:3306/test", "root", "123456")
iterator.foreach(line => {
ps = conn.prepareStatement(sql)
ps.setString(1, line._1)
ps.setInt(2, line._2)
ps.executeUpdate()
})
} catch {
case e: Exception => println(e)
} finally {
if (ps != null)
ps.close()
if (conn != null)
conn.close()
}
} def main(args: Array[String]) {
val conf = new SparkConf().setAppName("iplocation").setMaster("local[5]")
val sc = new SparkContext(conf)
//读取数据(ipstart,ipend,城市基站名,经度,维度)
val jizhanRDD = sc.textFile("E:\\ip.txt").map(_.split("\\|")).map(x => (x(2), x(3), x(4) + "-" + x(5) + "-" + x(6) + "-" + x(7) + "-" + x(8) + "-" + x(9), x(13), x(14)))
// jizhanRDD.foreach(println)
//把RDD转换成数据
val jizhanPartRDDToArray: Array[(String, String, String, String, String)] = jizhanRDD.collect()
//广播变量,一个只读的数据区,是所有的task都能读取的地方,相当于mr的分布式内存
val jizhanRDDToArray: Broadcast[Array[(String, String, String, String, String)]] = sc.broadcast(jizhanPartRDDToArray)
// println(jizhanRDDToArray.value) val IPS = sc.textFile("E:\\20090121000132.394251.http.format").map(_.split("\\|")).map(x => x(1)) //把ip地址转换为Long类型,然后通过二分法去ip段数据中查找,对找到的经纬度做wordcount
//((经度,纬度),1)
val result = IPS.mapPartitions(it => { val value: Array[(String, String, String, String, String)] = jizhanRDDToArray.value
it.map(ip => {
//将ip转换成数字
val ipNum: Long = ip2Long(ip) //拿这个数字去ip段中通过二分法查找,返回ip在ip的Array中的角标
val index: Int = binarySearch(ipNum, value)
//通Array拿出想要的数据
((value(index)._4, value(index)._5), 1)
})
}) //聚合操作
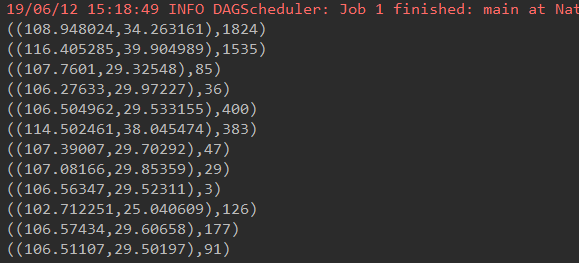
val resultFinnal: RDD[((String, String), Int)] = result.reduceByKey(_ + _) // resultFinnal.foreach(println)
//将数据存储到数据库
resultFinnal.map(x => (x._1._1 + "-" + x._1._2, x._2)).foreachPartition(data2MySQL _)
sc.stop() } }
PV案例
package org.apache.spark import org.apache.spark.rdd.RDD /**
* Created by Administrator on 2019/6/12.
*/
//PV(Page View)访问量, 即页面浏览量或点击量
object PV {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("pv").setMaster("local[2]")
val sc = new SparkContext(conf)
//读取数据access.log
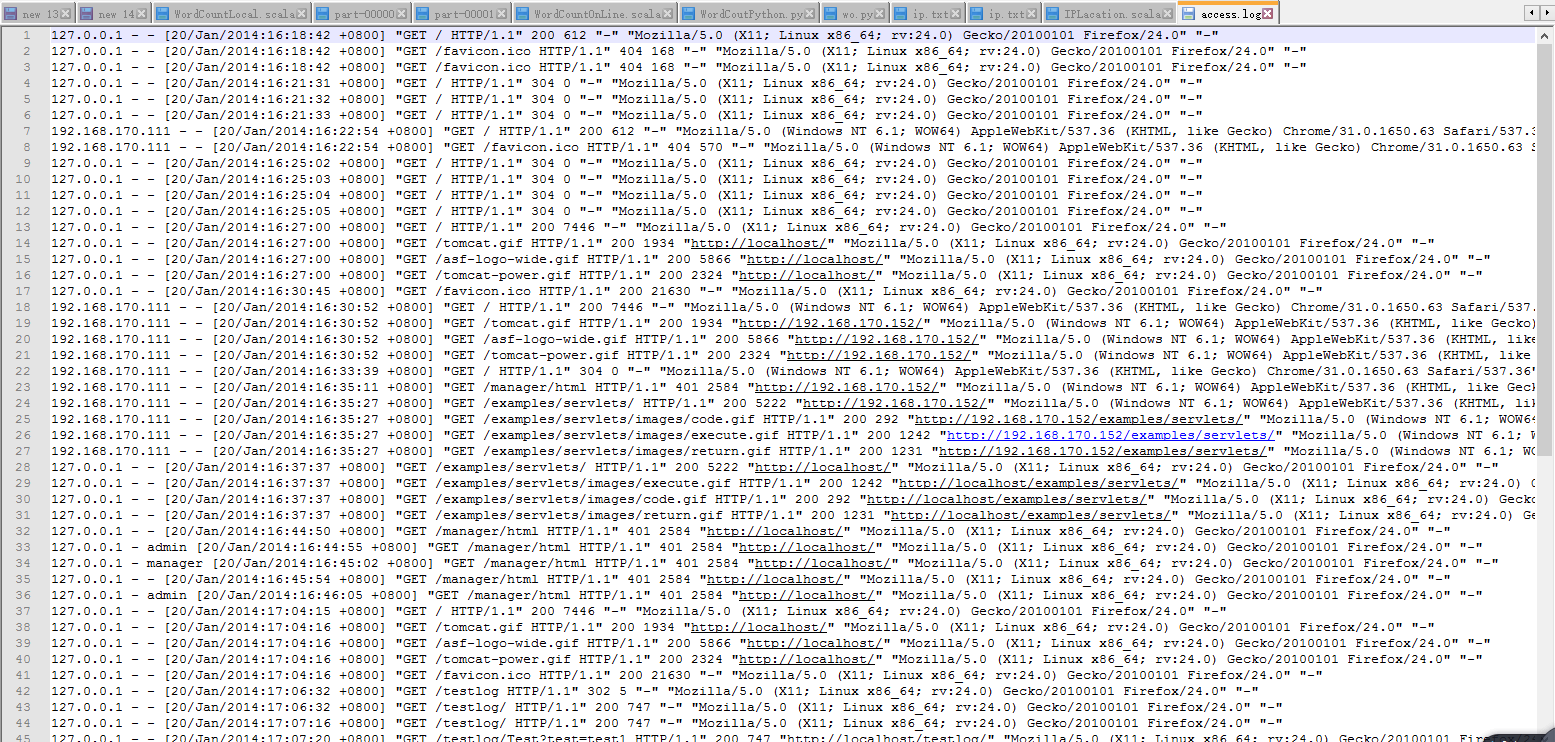
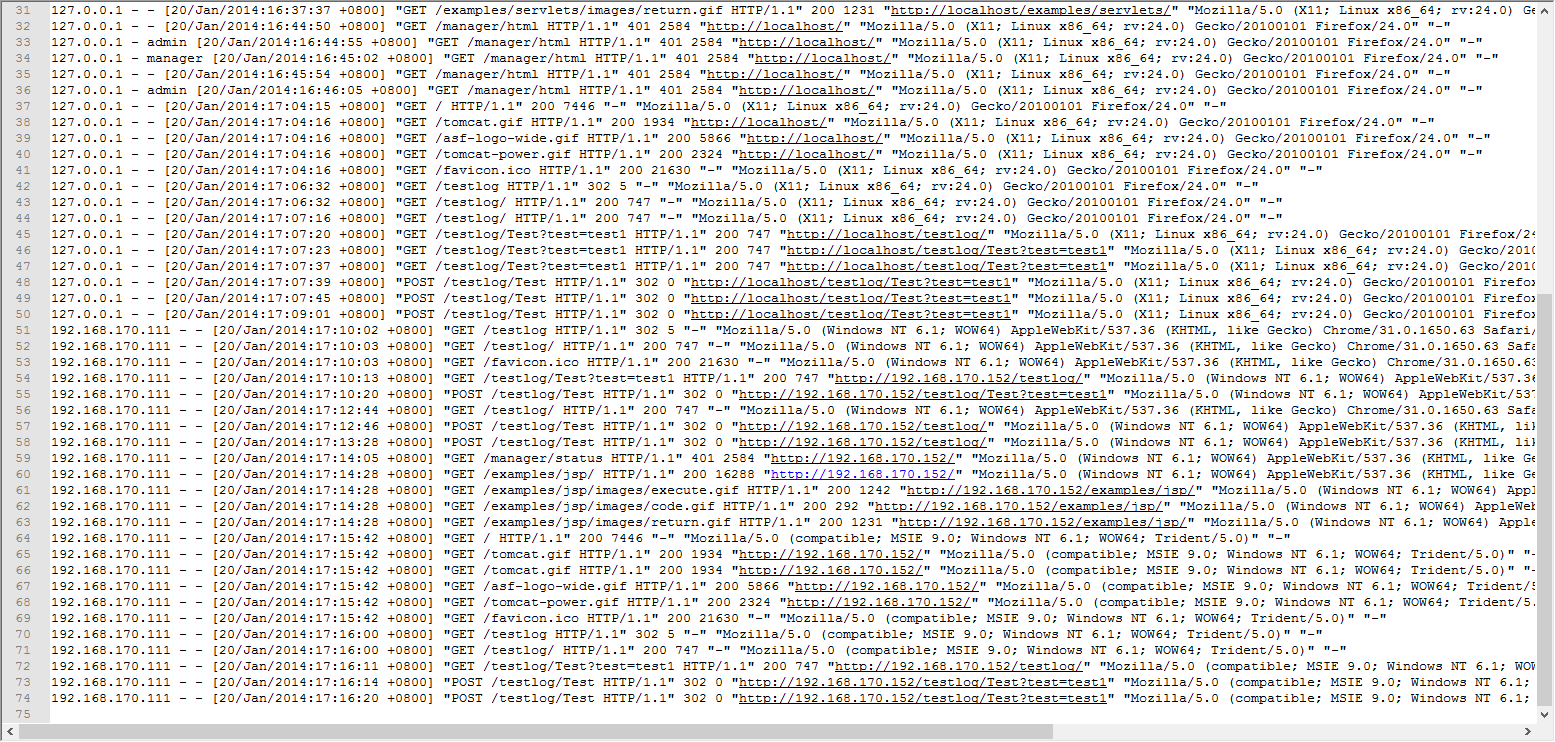
val file: RDD[String] = sc.textFile("e:\\access.log")
//将一行数据作为输入,将()
val pvAndOne: RDD[(String, Int)] = file.map(x => ("pv", 1))
//聚合计算
val result = pvAndOne.reduceByKey(_ + _)
result.foreach(println)
}
}

UV
package org.apache.spark import org.apache.spark.rdd.RDD /**
* Created by Administrator on 2019/6/12.
*/
//UV(Unique Visitor)独立访客,统计1天内访问某站点的用户数(以cookie为依据);访问网站的一台电脑客户端为一个访客
object UV {
def main(args: Array[String]) {
val conf = new SparkConf().setAppName("pv").setMaster("local[2]")
val sc = new SparkContext(conf)
//读取数据access.log
val file: RDD[String] = sc.textFile("e:\\access.log") //要分割file,拿到ip,然后去重
val uvAndOne = file.map(_.split(" ")).map(x => x(0)).distinct().map(x => ("uv", 1)) //聚合
val result = uvAndOne.reduceByKey(_ + _)
result.foreach(println)
}
}
pv uv环比分析
package org.apache.spark import scala.collection.mutable.ArrayBuffer /**
* Created by Administrator on 2019/6/12.
*/
object Pvbi {
// LoggerLevels.setStreamingLogLevels()
val conf = new SparkConf().setAppName("pv").setMaster("local[7]")
val sc = new SparkContext(conf)
val PVArr = ArrayBuffer[(String, Int)]()
val UVArr = ArrayBuffer[(String, Int)]() def main(args: Array[String]) {
computePVOneDay("e:\\access/tts7access20140824.log")
computePVOneDay("e:\\access/tts7access20140825.log")
computePVOneDay("e:\\access/tts7access20140826.log")
computePVOneDay("e:\\access/tts7access20140827.log")
computePVOneDay("e:\\access/tts7access20140828.log")
computePVOneDay("e:\\access/tts7access20140829.log")
computePVOneDay("e:\\access/tts7access20140830.log")
println(PVArr)
computeUVOneDay("e:\\access/tts7access20140824.log")
computeUVOneDay("e:\\access/tts7access20140825.log")
computeUVOneDay("e:\\access/tts7access20140826.log")
computeUVOneDay("e:\\access/tts7access20140827.log")
computeUVOneDay("e:\\access/tts7access20140828.log")
computeUVOneDay("e:\\access/tts7access20140829.log")
computeUVOneDay("e:\\access/tts7access20140830.log")
println(UVArr)
} def computePVOneDay(filePath: String): Unit = {
val file = sc.textFile(filePath)
val pvTupleOne = file.map(x => ("pv", 1)).reduceByKey(_ + _)
val collect: Array[(String, Int)] = pvTupleOne.collect()
PVArr.+=(collect(0))
} def computeUVOneDay(filePath: String): Unit = {
val rdd1 = sc.textFile(filePath)
val rdd3 = rdd1.map(x => x.split(" ")(0)).distinct
val rdd4 = rdd3.map(x => ("uv", 1))
val rdd5 = rdd4.reduceByKey(_ + _)
val collect: Array[(String, Int)] = rdd5.collect()
UVArr.+=(collect(0))
}
}


TopK
package org.apache.spark import org.apache.spark.rdd.RDD /**
* Created by Administrator on 2019/6/12.
*/
object TopK {
def main(args: Array[String]) {
//创建配置,设置app的name
val conf = new SparkConf().setAppName("topk").setMaster("local[2]")
//创建sparkcontext,将conf传进来
val sc = new SparkContext(conf)
//读取数据access.log
val file: RDD[String] = sc.textFile("e:\\access.log")
//将一行数据作为输入,将()
val refUrlAndOne: RDD[(String, Int)] = file.map(_.split(" ")).map(x => x(10)).map((_, 1)) //聚合
val result: Array[(String, Int)] = refUrlAndOne.reduceByKey(_ + _).sortBy(_._2, false).take(3) println(result.toList)
}
}

mobile_location案例
需要的数据
链接:https://pan.baidu.com/s/1JbGxnrgxcy05LFUmVo8AUQ
提取码:h7io
package org.apache.spark
import org.apache.spark.rdd.RDD
import scala.collection.mutable.Map
object MobileLocation {
def main(args: Array[String]) {
//本地运行
val conf = new SparkConf().setAppName("UserLocation").setMaster("local[5]")
val sc = new SparkContext(conf)
//todo:过滤出工作时间(读取基站用户信息:18688888888,20160327081200,CC0710CC94ECC657A8561DE549D940E0,1)
val officetime = sc.textFile("e:\\ce\\*.log")
.map(_.split(",")).filter(x => (x(1).substring(8, 14) >= "080000" && (x(1).substring(8, 14) <= "180000")))
//todo:过滤出家庭时间(读取基站用户信息:18688888888,20160327081200,CC0710CC94ECC657A8561DE549D940E0,1)
val hometime = sc.textFile("e:\\ce\\*.log")
.map(_.split(",")).filter(x => (x(1).substring(8, 14) > "180000" && (x(1).substring(8, 14) <= "240000")))
//todo:读取基站信息:9F36407EAD0629FC166F14DDE7970F68,116.304864,40.050645,6
val rdd20 = sc.textFile("e:\\ce\\loc_info.txt")
.map(_.split(",")).map(x => (x(0), (x(1), x(2))))
//todo:计算多余的时间次数
val map1Result = computeCount(officetime)
val map2Result = computeCount(hometime)
val mapBro1 = sc.broadcast(map1Result)
val mapBro2 = sc.broadcast(map2Result)
//todo:计算工作时间
computeOfficeTime(officetime, rdd20, "c://out/officetime", mapBro1.value)
//todo:计算家庭时间
computeHomeTime(hometime, rdd20, "c://out/hometime", mapBro2.value)
sc.stop()
}
/**
* 计算多余的时间次数
*
* 1、将“电话_基站ID_年月日"按key进行分组,如果value的大小为2,那么证明在同一天同一时间段(8-18或者20-24)同时出现两次,那么这样的数据需要记录,减去多余的时间
* 2、以“电话_基站ID”作为key,将共同出现的次数为2的累加,作为value,存到map中,
* 例如:
* 13888888888_8_20160808100923_1和13888888888_8_20160808170923_0表示在13888888888在同一天20160808的8-18点的时间段,在基站8出现入站和出站
* 那么,这样的数据对于用户13888888888在8基站就出现了重复数据,需要针对key为13888888888_8的value加1
* 因为我们计算的是几个月的数据,那么,其他天数也会出现这种情况,累加到13888888888_8这个key中
*/
def computeCount(rdd1: RDD[Array[String]]): Map[String, Int] = {
var map = Map(("init", 0))
//todo:groupBy:按照"电话_基站ID_年月日"分组,将符合同一组的数据聚在一起
for ((k, v) <- rdd1.groupBy(x => x(0) + "_" + x(2) + "_" + x(1).substring(0, 8)).collect()) {
val tmp = map.getOrElse(k.substring(0, k.length() - 9), 0)
if (v.size % 2 == 0) {
//todo:以“电话_基站ID”作为key,将共同出现的次数作为value,存到map中
map += (k.substring(0, k.length() - 9) -> (tmp + v.size / 2))
}
}
map
}
/**
* 计算在家的时间
*/
def computeHomeTime(rdd1: RDD[Array[String]], rdd2: RDD[(String, (String, String))], outDir: String, map: Map[String, Int]) {
//todo:(手机号_基站ID,时间)算法:24-x 或者 x-20
val rdd3 = rdd1.map(x => ((x(0) + "_" + x(2), if (x(3).toInt == 1) 24 - Integer.parseInt(x(1).substring(8, 14)) / 10000
else Integer.parseInt(x(1).substring(8, 14)) / 10000 - 20)))
//todo:手机号_基站ID,总时间
val rdd4 = rdd3.reduceByKey(_ + _).map {
case (telPhone_zhanId, totalTime) => {
(telPhone_zhanId, totalTime - (Math.abs(map.getOrElse(telPhone_zhanId, 0)) * 4))
}
}
//todo:按照总时间排序(手机号_基站ID,总时间<倒叙>)
val rdd5 = rdd4.sortBy(_._2, false)
//todo:分割成:手机号,(基站ID,总时间)
val rdd6 = rdd5.map {
case (telphone_zhanId, totalTime) => (telphone_zhanId.split("_")(0), (telphone_zhanId.split("_")(1), totalTime))
}
//todo:找到时间的最大值:(手机号,compactBuffer((基站ID,总时间1),(基站ID,总时间2)))
val rdd7 = rdd6.groupByKey.map {
case (telphone, buffer) => (telphone, buffer.head)
}.map {
case (telphone, (zhanId, totalTime)) => (telphone, zhanId, totalTime)
}
//todo:join都获取基站的经纬度
val rdd8 = rdd7.map {
case (telphon, zhanId, time) => (zhanId, (telphon, time))
}.join(rdd2).map {
//todo:(a,(1,2))
case (zhanId, ((telphon, time), (jingdu, weidu))) => (telphon, zhanId, jingdu, weidu)
}
rdd8.foreach(println)
//rdd8.saveAsTextFile(outDir)
}
/**
* 计算工作的时间
*/
def computeOfficeTime(rdd1: RDD[Array[String]], rdd2: RDD[(String, (String, String))], outDir: String, map: Map[String, Int]) {
//todo:(手机号_基站ID,时间) 算法:18-x 或者 x-8
val rdd3 = rdd1.map(x => ((x(0) + "_" + x(2), if (x(3).toInt == 1) 18 - Integer.parseInt(x(1).substring(8, 14)) / 10000
else Integer.parseInt(x(1).substring(8, 14)) / 10000 - 8)))
//todo:手机号_基站ID,总时间
val rdd4 = rdd3.reduceByKey(_ + _).map {
case (telPhone_zhanId, totalTime) => {
(telPhone_zhanId, totalTime - (Math.abs(map.getOrElse(telPhone_zhanId, 0)) * 10))
}
}
//todo:按照总时间排序(手机号_基站ID,总时间<倒叙>)
val rdd5 = rdd4.sortBy(_._2, false)
//todo:分割成:手机号,(基站ID,总时间)
val rdd6 = rdd5.map {
case (telphone_zhanId, totalTime) => (telphone_zhanId.split("_")(0), (telphone_zhanId.split("_")(1), totalTime))
}
//todo:找到时间的最大值:(手机号,compactBuffer((基站ID,总时间1),(基站ID,总时间2)))
val rdd7 = rdd6.groupByKey.map {
case (telphone, buffer) => (telphone, buffer.head)
}.map {
case (telphone, (zhanId, totalTime)) => (telphone, zhanId, totalTime)
}
//todo:join都获取基站的经纬度
val rdd8 = rdd7.map {
case (telphon, zhanId, time) => (zhanId, (telphon, time))
}.join(rdd2).map {
case (zhanId, ((telphon, time), (jingdu, weidu))) => (telphon, zhanId, jingdu, weidu)
}
rdd8.foreach(println)
//rdd8.saveAsTextFile(outDir)
}
}
大数据学习——spark运营案例的更多相关文章
- 大数据学习——spark笔记
变量的定义 val a: Int = 1 var b = 2 方法和函数 区别:函数可以作为参数传递给方法 方法: def test(arg: Int): Int=>Int ={ 方法体 } v ...
- 大数据学习——spark学习
计算圆周率 [root@mini1 bin]# ./run-example SparkPi [root@mini1 bin]# ./run-example SparkPi [root@mini1 bi ...
- 大数据学习——spark安装
一主多从 1 上传压缩包 2 解压 -bin-hadoop2..tgz 删除安装包 -bin-hadoop2..tgz 重命名 mv spark-1.6.2-bin-hadoop2.6/ spark ...
- 大数据学习系列之六 ----- Hadoop+Spark环境搭建
引言 在上一篇中 大数据学习系列之五 ----- Hive整合HBase图文详解 : http://www.panchengming.com/2017/12/18/pancm62/ 中使用Hive整合 ...
- 大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 图文详解
引言 在之前的大数据学习系列中,搭建了Hadoop+Spark+HBase+Hive 环境以及一些测试.其实要说的话,我开始学习大数据的时候,搭建的就是集群,并不是单机模式和伪分布式.至于为什么先写单 ...
- 大数据学习系列之九---- Hive整合Spark和HBase以及相关测试
前言 在之前的大数据学习系列之七 ----- Hadoop+Spark+Zookeeper+HBase+Hive集群搭建 中介绍了集群的环境搭建,但是在使用hive进行数据查询的时候会非常的慢,因为h ...
- 大数据学习day29-----spark09-------1. 练习: 统计店铺按月份的销售额和累计到该月的总销售额(SQL, DSL,RDD) 2. 分组topN的实现(row_number(), rank(), dense_rank()方法的区别)3. spark自定义函数-UDF
1. 练习 数据: (1)需求1:统计有过连续3天以上销售的店铺有哪些,并且计算出连续三天以上的销售额 第一步:将每天的金额求和(同一天可能会有多个订单) SELECT sid,dt,SUM(mone ...
- 大数据学习路线,来qun里分享干货,
一.Linux lucene: 全文检索引擎的架构 solr: 基于lucene的全文搜索服务器,实现了可配置.可扩展并对查询性能进行了优化,并且提供了一个完善的功能管理界面. 推荐一个大数据学习群 ...
- 大数据学习day26----hive01----1hive的简介 2 hive的安装(hive的两种连接方式,后台启动,标准输出,错误输出)3. 数据库的基本操作 4. 建表(内部表和外部表的创建以及应用场景,数据导入,学生、分数sql练习)5.分区表 6加载数据的方式
1. hive的简介(具体见文档) Hive是分析处理结构化数据的工具 本质:将hive sql转化成MapReduce程序或者spark程序 Hive处理的数据一般存储在HDFS上,其分析数据底 ...
随机推荐
- 剑指offer课外两道习题解法
1.定义一个函数,删除字符串中所有重复出现的字符,例如输入“google”,删除重复的字符之后的结果为“gole”. 解题思路:像这种求字符串的重复字符,并且去掉重复字符,我们一般可以用哈希 ...
- requests模块下载视频 显示进度和网速
requests 下载视频 import os,time import requests def downloadFile(name, url): headers = {'Proxy-Connecti ...
- 一键部署WordPress开源内容管理系统
https://market.azure.cn/Vhd/Show?vhdId=9857&version=10889 产品详情 产品介绍WordPress是一款个人博客系统,并逐步演化成一款内容 ...
- 自定义标签jsp2格式
在写自定义标签时候是不是感觉很烦啊,其实人家也是这样认为的,于是我们的jsp新的标准对标签进行了更改,使我们用起来更简单.到底哪里简单呢?看看代码再说咯: 还是老规矩,先上一个标签的逻辑类: 1. p ...
- 数据分析R&Python-Rpy2包环境配置
Rpy2环境配置 最近想将R整合到以flask为后端框架的web系统中,在服务器端做数据统计分析.需要将R语言整合到Python中,发现Python中的Rpy2可以调用R语言,所以花了一些时间配置了一 ...
- [CV笔记]图像特征提取三大法宝:HOG特征,LBP特征,Haar特征
(一)HOG特征 1.HOG特征: 方向梯度直方图(Histogram of Oriented Gradient, HOG)特征是一种在计算机视觉和图像处理中用来进行物体检测的特征描述子.它通过计算和 ...
- 【转】iOS开发里的Bundle是个啥玩意?!
初学iOS开发的同学,不管是自己写的,还是粘贴的代码,或多或少都写过下面的代码 [[NSBundle mainBundle] pathForResource:@"someFileName&q ...
- ubuntu下安装eclipse<转>
转载自http://my.oschina.net/u/1407116/blog/227084 http://my.oschina.net/u/1407116/blog/227087 一 JD ...
- python_93_面向对象实例2
class Role: def __init__(self,name,role,weapon,life_value=100,money=15000): '构造函数:实例化时做一些类的初始化工作' se ...
- ovx openVirtex的阅读文档
由于flowvisor只有4个版本, 最新更新都是2013年的, 跟底层ovs版本不跟进, 最近斯坦福post一个 ovx, 猜测是flowvisor的加强版, 所以看一下文档说明 文档详见http: ...