自然语言处理(二)——PTB数据集的预处理
参考书
《TensorFlow:实战Google深度学习框架》(第2版)
首先按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: word_deal1.py
@time: 2019/2/20 10:42
@desc: 首先按照词频顺序为每个词汇分配一个编号,然后将词汇表保存到一个独立的vocab文件中。
""" import codecs
import collections
from operator import itemgetter # 训练集数据文件
RAW_DATA = "./simple-examples/data/ptb.train.txt"
# 输出的词汇表文件
VOCAB_OUTPUT = "ptb.vocab" # 统计单词出现的频率
counter = collections.Counter()
with codecs.open(RAW_DATA, "r", "utf-8") as f:
for line in f:
for word in line.strip().split():
counter[word] += 1 # 按照词频顺序对单词进行排序
sorted_word_to_cnt = sorted(counter.items(), key=itemgetter(1), reverse=True)
sorted_words = [x[0] for x in sorted_word_to_cnt] # 稍后我们需要在文本换行处加入句子结束符“<eos>”,这里预先将其加入词汇表。
sorted_words = ["<eos>"] + sorted_words
# 在后面处理机器翻译数据时,出了"<eos>",还需要将"<unk>"和句子起始符"<sos>"加入
# 词汇表,并从词汇表中删除低频词汇。在PTB数据中,因为输入数据已经将低频词汇替换成了
# "<unk>",因此不需要这一步骤。
# sorted_words = ["<unk>", "<sos>", "<eos>"] + sorted_words
# if len(sorted_words) > 10000:
# sorted_words = sorted_words[:10000] with codecs.open(VOCAB_OUTPUT, 'w', 'utf-8') as file_output:
for word in sorted_words:
file_output.write(word + "\n")
运行结果:

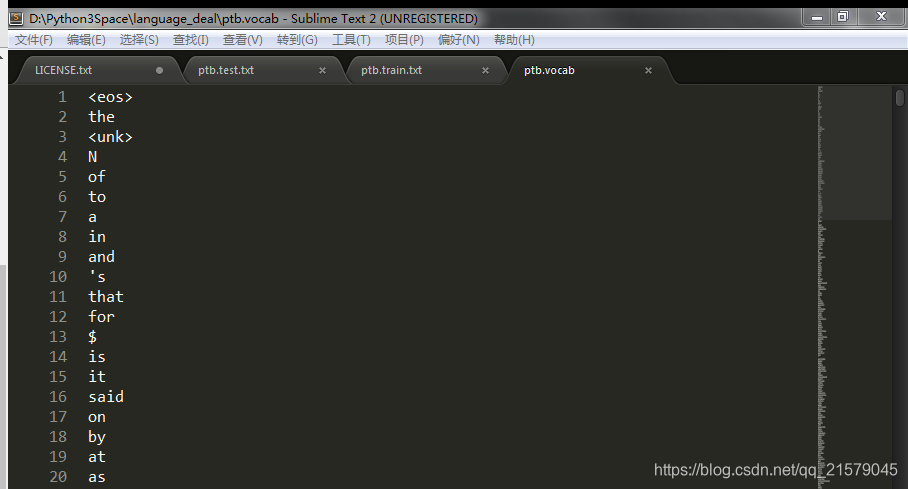
在确定了词汇表之后,再将训练文件、测试文件等都根据词汇文件转化为单词编号。每个单词的编号就是它在词汇文件中的行号。
#!/usr/bin/env python
# -*- coding: UTF-8 -*-
# coding=utf-8 """
@author: Li Tian
@contact: 694317828@qq.com
@software: pycharm
@file: word_deal2.py
@time: 2019/2/20 11:10
@desc: 在确定了词汇表之后,再将训练文件、测试文件等都根据词汇文件转化为单词编号。每个单词的编号就是它在词汇文件中的行号。
""" import codecs
import sys # 原始的训练集数据文件
RAW_DATA = "./simple-examples/data/ptb.train.txt"
# 上面生成的词汇表文件
VOCAB = "ptb.vocab"
# 将单词替换成为单词编号后的输出文件
OUTPUT_DATA = "ptb.train" # 读取词汇表,并建立词汇到单词编号的映射。
with codecs.open(VOCAB, "r", "utf-8") as f_vocab:
vocab = [w.strip() for w in f_vocab.readlines()]
word_to_id = {k: v for (k, v) in zip(vocab, range(len(vocab)))} # 如果出现了被删除的低频词,则替换为"<unk>"。
def get_id(word):
return word_to_id[word] if word in word_to_id else word_to_id["<unk"] fin = codecs.open(RAW_DATA, "r", "utf-8")
fout = codecs.open(OUTPUT_DATA, 'w', 'utf-8')
for line in fin:
# 读取单词并添加<eos>结束符
words = line.strip().split() + ["<eos>"]
# 将每个单词替换为词汇表中的编号
out_line = ' '.join([str(get_id(w)) for w in words]) + '\n'
fout.write(out_line)
fin.close()
fout.close()
运行结果:
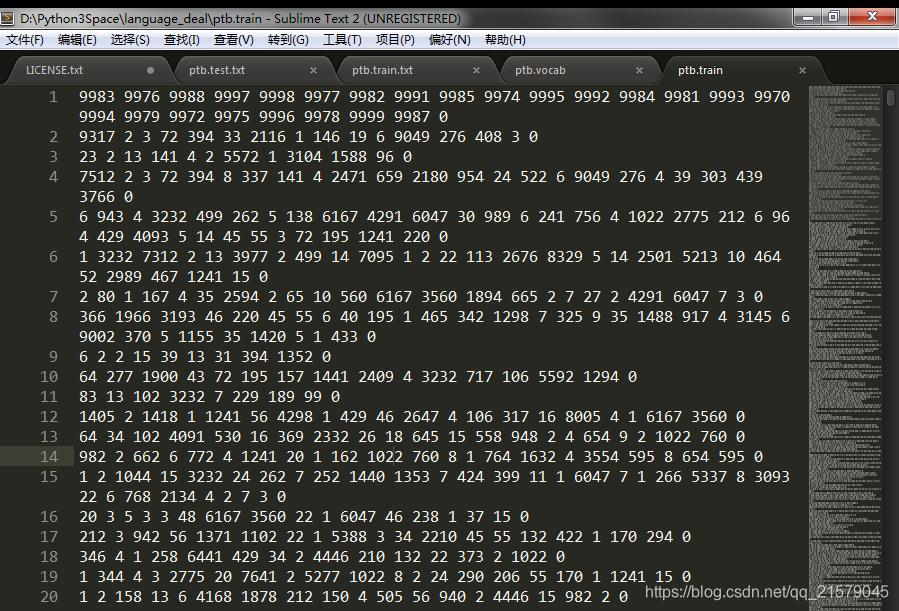
自然语言处理(二)——PTB数据集的预处理的更多相关文章
- c语言学习之基础知识点介绍(二十):预处理指令
一.预处理指令的介绍 预处理命令:在编译之前触发的一系列操作(命令)就叫预处理命令. 特点:以#开头,不要加分号. #include: 文件包含指令 把指定文件的内容复制到相应的位置 #define: ...
- TensorFlow数据集(二)——数据集的高层操作
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 一个使用数据集进行训练和测试的完整例子. #!/usr/bin/env python # -*- coding: ...
- 吴裕雄--天生自然 pythonTensorFlow自然语言处理:PTB 语言模型
import numpy as np import tensorflow as tf # 1.设置参数. TRAIN_DATA = "F:\TensorFlowGoogle\\201806- ...
- R语言实战读书笔记(二)创建数据集
2.2.2 矩阵 matrix(vector,nrow,ncol,byrow,dimnames,char_vector_rownames,char_vector_colnames) 其中: byrow ...
- AI-sklearn 学习笔记(二)数据集
from sklearn import datasets from sklearn.linear_model import LinearRegression loaded_data = dataset ...
- C#中的深度学习(二):预处理识别硬币的数据集
在文章中,我们将对输入到机器学习模型中的数据集进行预处理. 这里我们将对一个硬币数据集进行预处理,以便以后在监督学习模型中进行训练.在机器学习中预处理数据集通常涉及以下任务: 清理数据--通过对周围数 ...
- LUNA16数据集(三)预处理
在(一)和(二)中简单介绍了LUNA16数据集的组成,以及肺结节的可视化,有了对数据集的基本了解后,还要对数据集进行预处理,计算机视觉中原始数据一般不会直接送入神经网络,这里也是如此. 这篇博客想写已 ...
- 自然语言处理(五)——实现机器翻译Seq2Seq完整经过
参考书 <TensorFlow:实战Google深度学习框架>(第2版) 我只能说这本书太烂了,看完这本书中关于自然语言处理的内容,代码全部敲了一遍,感觉学的很绝望,代码也运行不了. 具体 ...
- 用tensorflow实现自然语言处理——基于循环神经网络的神经语言模型
自然语言处理和图像处理不同,作为人类抽象出来的高级表达形式,它和图像.声音不同,图像和声音十分直觉,比如图像的像素的颜色表达可以直接量化成数字输入到神经网络中,当然如果是经过压缩的格式jpeg等必须还 ...
随机推荐
- js 数据获取
http://www.cnhan.com/shantui/templates/MC500/TP001/js/template.js var qiaoContent="0";//0默 ...
- DuiLib笔记之自定义标题栏以及响应按钮点击事件
在博文DuiLib笔记,基于WindowImplBase的基础模板的基础上,修改皮肤文件如下 <?xml version="1.0" encoding="utf-8 ...
- ABAP 实现Excel 粘贴复制
"设置需要复制的区域 CLEAR gv_range. gs_ole2-row1 = . gs_ole2-col1 = . gs_ole2-row2 = . gs_ole2-col2 = . ...
- LightOJ1213 Fantasy of a Summation —— 快速幂
题目链接:https://vjudge.net/problem/LightOJ-1213 1213 - Fantasy of a Summation PDF (English) Statisti ...
- poj3904 Sky Code —— 唯一分解定理 + 容斥原理 + 组合
题目链接:http://poj.org/problem?id=3904 Sky Code Time Limit: 1000MS Memory Limit: 65536K Total Submiss ...
- codeforces B. Ping-Pong (Easy Version) 解题报告
题目链接:http://codeforces.com/problemset/problem/320/B 题目意思:有两种操作:"1 x y" (x < y) 和 " ...
- kali-linux简单学习(二)
一.SET 社会工程学工具包有一个叫devolution. 启动 setoolkit 里面可以进行一些钓鱼攻击. tabnabbing attack这种方式是完整克隆一个网站挂到SET创建的web服 ...
- java并发之阻塞队列LinkedBlockingQueue与ArrayBlockingQueue
Java中阻塞队列接口BlockingQueue继承自Queue接口,并提供put.take阻塞方法.两个主要的阻塞类实现是ArrayBlockingQueue和LinkedBlockingQueue ...
- ZOJ3201(树形DP)
Tree of Tree Time Limit: 1 Second Memory Limit: 32768 KB You're given a tree with weights of ea ...
- POJ1904(有向图缩点+输入输出挂参考)
King's Quest Time Limit: 15000MS Memory Limit: 65536K Total Submissions: 8311 Accepted: 3017 Cas ...