kafka技术分享02--------kafka入门
kafka技术分享02--------kafka入门
1. 消息系统
所谓的Messaging System就是一组规范,企业利用这组规范在不同的系统之间传递语义准确对的消息,实现松耦合的异步数据传输。简单理解为系统A将消息发送给Messaging System,系统B从Messaging System中获取系统A发送的消息。消息系统主要作用可以概括为四个字:削峰填谷。通过消息系统可以对抗这种上下游消息系统TPS的错配以及瞬时峰值流量。
补充一点:
通常来说,两个进程进行数据流交互的方式一般有三种:
通过数据库:进程1写入数据库;进程2读取数据库
通过服务调用:比如REST或RPC,而HTTP协议通常就作为REST方式的底层通讯协议
通过消息传递的方式:进程1发送消息给名为broker的中间件,然后进程2从该broker中读取消息。消息传输协议属于这种模式
因此,Messageing System必须保证消息的传输格式的语义正确解析无歧义,另外还要对如何传输消息进行设计。对于第一点Kafka使用的是纯二进制的字节序列,对于第二点消息的传输方式大概有两种:
点对点模式:系统A发送的消息只能被系统B所接受,其他任何系统不能读取系统A发送的消息
发布(publish)/订阅(suscribe)模式:可以存在多个消息发布者往同一topic中发送数据,同时可以存在多个消费者对统一topic的数据进行消费。
kafka同时支持者两种消息传输模式。
2.kafka是什么
Kafka既是一个开源的分布式消息系统,又是一个分布式流平台。
kafka在设计之初旨在提供三个方面的特性:
提供一套API实现生产者消费者;
降低网络传输和磁盘存储开销
实现高伸缩性架构
从以上三点可以看出,kafka的设计之初的目的其实是作为一个消息系统,主要作用是承接上下游、串联数据流管道。直到kafka0.10.0.0版本正式推出了流处理组件Kafka Streams,Kafka正式变身为流处理平台。那么kafka streams和其他大数据流处理框架相比的优势主要表现在:
更容易实现端到端的正确性。实现正确性的基石是要求框架能够提供精确一次性处理语义,即处理一条消息有且只有一次影响系统的状态。目前主流的大数据流处理框架都宣称实现了精确一次处理语义,但是有条件的,只能实现框架内的精确一次处理语义,无法实现端到端的精确一次处理语义。而kafka streams的数据流转和计算都在kafka内部,因此能够实现端到端的精确一次处理语义。
他自己对于流式计算的定位。官网上明确标识Kafka Streams是一个搭建实时流处理的客户端库,而非一个完整的功能系统。因此kafka不提供类似于集群调度和弹性部署等开箱即用的运维特性,需要自己选择合适的工具和系统来帮助kafka流处理应用实现此类功能。kafka Streams的定位是中小型公司,数据量没有那么大,使用大数据流处理框架有点浪费。
3. kafka的种类
Apache Kafka。
Apache Kafka是社区版kafka。它的优势在于毫无疑问它是开发人数最多、版本迭代最快的Kafka。他的劣势在于仅仅提供了最基础的组件,对于Kafka Connect,仅仅提供了一种连接器即读写磁盘文件的连接器,而没有于其他系统交互的连接器。另外,Apache Kafka也没有提供任何监控的框架和工具。需要借助于第三方框架(Kafka Manager、kafka eagle、JMXTrans + InfluxDB + Grafana)
Confluent Kafka
Confluent公司基于Apache Kafka创建的商业版Kafka


CDH/HDP Kafka
Cloudera提供的CDH和HortonWorkers提供的HDP是著名的大数据平台,里边集成了目前主流的大数据处理框架,能够帮助用户实现从分布式存储、集群调度、流处理到机器学习、实时数据库等方面的数据处理。CDH和HDP都集成了Apache Kafka。

补充kafka的性能监测工具:
Kafka自己提供了kafka-producer-perf-test和kafka-consumer-perf-test脚本可以做producer和consumer的性能测试。另外LinkedIn开源了一款名为kafka-monitor的端到端系统测试工具,也可以用来测试Kafka集群end-to-end的性能。有些遗憾的是这个工具几乎没什么人维护了。
4. kafka术语
kafka属于分布式消息系统,它的主要功能室提供一套完备的消息发布订阅的解决方案,实现不同系统之间的消息传递。kafka中发布订阅的对象就是topic,可以将topic理解为某一类消息的一个标识。
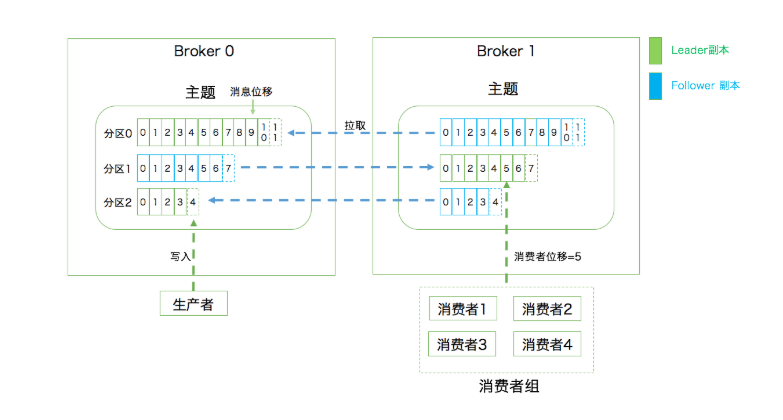
客户端:向主题发布消息的客户端应用程序就称为生产者(Producer),订阅主题的客户端应用程序称之为消费者(Consumer)。生产者、主题和消费者的数量关系不固定,一个生产者可以不断的向一个或多个主题发送消息,一个消费者可以订阅一个或多个主题。
服务端:kafka的服务端由被称为Broker的服务进程组成,给一个kafka集群由多个broker进程组成。Broker主要负责接收和处理客户端的请求,以及对消息进行持久化。虽然一台主机可以运行多个Broker进程,但更为常见的做法是将Broker运行在不同的主机上,实现容灾与高可用。
另外一个实现高可用的方式是副本机制(Replication)。副本机制的基本思想就是将相同的数据拷贝到不同的机器上。kafka定义了两类副本:Leader Replia和Follower Replia。Leader主要是接收处理客户端的请求,Follower主要同步Leader的数据,不能与外界进行交互。
简单一句话就生产者总是想leader发送数据,而消费者总是从leader消费数据。follower就做一件事,请求leader将最新的消息发动给它。Kafka不能推送消息给consumer。Consumer只能不断地轮训去获取消息。从Kafka流向consumer的唯一方式就是通过poll。另外维持一个长连接去轮训的开销通常也没有你想的那么大,特别是Kafka用的是Linux上的epoll,性能还不错,至少比select好。
分区中的所有副本统称为AR(assigned Replica),很所时候follower副本中的消息相对于leader而言会有一定的滞后,这个滞后范围是可以通过参数进行配置的。所有与leader保持一定程度同步(并不一定是完全同步)的副本组成ISR(In-Sync Replica),剩余部分为OSR。所以AR=ISR+OSR。
leader副本负责维护和跟踪所有follower副本的滞后状态,当follower副本滞后太多或失效时,leader副本会将它从ISR中剔除,如果OSR中有follower副本追上leader副本,leader副本会将它从OSR迁移至ISR。默认情况下(可通过参数进行改变),leader副本发生故障,只有ISR集合中的副本才有资格参与leader的选举。
副本机制保证了数据的不丢失,提升容灾能力,但无法解决伸缩性问题(Scalability)。所谓的额伸缩性可以这样理解。倘若一个leader积累了足够多的数据,导致单台Broker无法容纳。Kafka的解决方式就是Partition机制,将一个topic的数据划分为多个分区,分区是有序的,编号从0开始,生产者生产的某一条数据只会发送到某一个分区,每一条消息在分区上的位置成为Offset。其实副本机制是建立在分区机制之上的,一个topic向的所有分区都有一个leader和多个folllower。分区在存储层可以被看做是一个可追加的日志文件,消息在追加到分区日志文件时,会分配一个特定的偏移量。每一条消息发送到broker之前都会根据分区规则选择存储到那个具体分区。分区的数量可以在出题创建的时候指定,也可以在创建主题完之后进行修改实现水平扩展。
消费者组:多个消费者共同组成一个组来消费一组主题。这个主题的某一个分区只会被消费者的某个特定分区所消费,其他消费者实例不能进行消费。之所以引入消费者组,更多的是因为多个消费者同时消费可以提高消费端的TPS。另外这里的消费者实例可以是运行消费者的应用进程,也可以是一个线程。消费者组内的消费者除了瓜分主题消息的功能,还可以互相协作,当某个消费者挂掉,kafka能够自动检测掉,进行分区的重平衡(Rebalance )。另外每一个消费者在消费过程中必然会记录消费到了分区那个位置,成为消费者偏移量(Consumer Offset)
一张图简单概括一下:

kafka的Broker是如何对消息进行持久化的?
kafka使用消息日志(Log)来保存数据,一个日志就是磁盘上一个只支持追加(Append Only)的物理文件,用顺序IO代替随机IO,是kafka实现高吞吐的一个重要手段。不过如果不停地向统一日志文件追加数据,总会耗尽所有磁盘空间,因此kafka必然会定期的删除消息,回收磁盘。kafka是通过日志段(Log Segment)机制进行磁盘回收的。在kafka的底层一个日志又进一步分成多个日志段,消息被追加到当前最新的日志段中,当写满一个日志段后,kafka会自动切分出一个新的日志段,并将老的日志段封存起来。kafka在后台会有定时认为会定期的检查老的日志段是够能够被删除,从而实现磁盘回收的目的。
请思考一下为什么 Kafka 不像 MySQL 那样允许Follower对外提供服务,支持主从读写分离?
主从读写分离主要目的就是缓解leader节点的压力,将读请求负载到多个follower上,提升读操作的性能。这种设计只是一种架构,无优劣之说,只是有自己的适用场景而已,通常适用于读多写少的场景。而对于kafka而言,它是一个消息系统而不是以存储的方式对外提供读服务,通常会涉及到频繁的生产数据和消费数据,并不符合读多写少的应用场景。如果Kafka的分区相对均匀地分散到各个broker上,同样可以达到负载均衡的效果,没必要刻意实现主写从读增加代码实现的复杂程度。
kafka的副本机制采用的是异步消息拉取,因此存在leader和follower的数据一致性问题,如果要实现读写分离,必须要处理好副本lag导致的数据一致性问题。
分布式系统中replica的leader和follower之间如何复制数据保证消息的持久化的问题,我了解的是有3种模式:
1.生产者消息发过来以后,写leader成功后即告知生产者成功,然后异步的将消息同步给其他follower,这种方式效率最高,但可能丢数据;
2.同步等待所有follower都复制成功后通知生产者消息发送成功,这样不会丢数据,但效率不高;
3.折中的办法,同步等待部分follower复制成功,如1个follower复制成功再返回,这样兼顾效率和消息的持久化。
目前Kafka不支持第三种“折中”办法。。。要么只写leader,要么所有follower全部同步。但是,我同意很多分布式系统是可以配置同步follower和异步follower共存的,比如一个同步follower+N-1个异步follower的伪同步。Facebook的MySQL就是这个原理。
5.Kafka的版本号
从官网下载kafka时,会出现如下两种情况。但是无论是哪种情况,Kafka-2.11-2.2.1,其中2.11指的是scala编译器的版本。2.2.1才是kafka的版本。Kafka版本经历了由四位表示到三位表示的转变,1.0.0版本之前采取四位,之后采用3位,无论是四位还是三位,kafka版本构成都是:大版本号(Major version)-小版本号(Minor Version)-修订版本号(Patch)。



Kafka的大版本共经历了从0.7、0.8、0.9、0.10、0.11、1.0、2.0七个版本的演变。
- 0.7 。这个版本仅仅提供了最基础的消息队列的功能,副本机制都没有。
- 0.8 。0.8正式引入了副本机制,至此kafka成为一个真正意义上完备的分布式高可靠的消息队列解决方案。生产者和消费者使用的还是老版本的API,即当你开发生产者和消费者时,你需要指定的zookeeper的地址而不是Broker的地址。

 0.9版本的主要功能改进包括:增加了基础的安全认证和权限功能;用java重写了新版本消费者API;引入了kafka connect组件用于实现高性能的数据抽取;新版本的producer API算基本稳定。但是0.9版本的新版Consumer APIBug超多。
0.9版本的主要功能改进包括:增加了基础的安全认证和权限功能;用java重写了新版本消费者API;引入了kafka connect组件用于实现高性能的数据抽取;新版本的producer API算基本稳定。但是0.9版本的新版Consumer APIBug超多。- 0.10.0.0这个版本是个里程碑式的版本,它引入了Kafka Streams,至此kafka变身为一个分布式流处理平台。


- 0.11.0.0提供了两个新的功能:提供了幂等性的Producer API和事务API,另一个是对kafka的消息格式进行了重构。


- 1.0和2.0两个版本的更新主要体现在Kafka Streams上,而且两个版本的API变化挺大。
kafka技术分享02--------kafka入门的更多相关文章
- kafka技术分享01--------why we study kafka?
kafka技术分享01--------why we study kafka? 作为一名大数据工程师,我们所面对的大多数是数据密集型的应用,而非计算密集型的应用.对于数据密集型的应用,如何解决数据激 ...
- 【转】apache kafka技术分享系列(目录索引)
转自: http://blog.csdn.net/lizhitao/article/details/39499283 估计大神会不定期更新,所以还是访问这个链接看最新的目录list比较好 apa ...
- apache kafka技术分享系列(目录索引)--转载
原文地址:http://blog.csdn.net/lizhitao/article/details/39499283 kafka开发与管理: 1)apache kafka消息服务 2)kafak安装 ...
- apache kafka技术分享系列(目录索引)
https://blog.csdn.net/lizhitao/article/details/39499283 https://blog.csdn.net/lizhitao
- 《KAFKA官方文档》入门指南(转)
1.入门指南 1.1简介 Apache的Kafka™是一个分布式流平台(a distributed streaming platform).这到底意味着什么? 我们认为,一个流处理平台应该具有三个关键 ...
- Kafka 技术文档
Kafka 技术文档 目录 1 Kafka创建背景 2 Kafka简介 3 Kafka好处 3.1 解耦 3.2 冗余 3.3 扩展性 3.4 灵活性 & 峰值处理能力 3.5 可恢复性 ...
- Erlang 编写 Kafka 客户端之最简单入门
Erlang 编写 Kafka 客户端之最简单入门 费劲周折,终于测通了 erlang 向kafka 发送消息,使用了ekaf 库,参考: An advanced but simple to use, ...
- AY的Dapper研究学习-基本入门-C#开发-aaronyang技术分享
原文:AY的Dapper研究学习-基本入门-C#开发-aaronyang技术分享 ====================www.ayjs.net 杨洋 wpfui.com ...
- Kafka(一)【概述、入门、架构原理】
目录 一.Kafka概述 1.1 定义 二.Kafka快速入门 2.1 安装部署 2.2 配置文件解析 2.3Kafka群起脚本 2.4 topic(增删改查) 2.5 生产和消费者命令行操作 三.K ...
随机推荐
- 转:跟我一起写Makefile (PDF重制版)
原文地址:http://seisman.info/how-to-write-makefile.html 其它一些问题 不妨看一下:http://blog.csdn.net/huyansoft/art ...
- c++ override 关键字
描述:override保留字表示当前函数重写了基类的虚函数. 目的:1.在函数比较多的情况下可以提示读者某个函数重写了基类虚函数(表示这个虚函数是从基类继承,不是派生类自己定义的):2.强制编译器检查 ...
- Android的初步探索之Context类
最近一直在学安卓,但由于JAVA的能力有限,学起应用开发来很吃力,众多错综复杂的类和界面组件弄的人焦头烂额,往往不知从何下手.... 各种名字冗长的方法和常量,没有任何界面编程的经验真是蛋疼死了.总是 ...
- 《Scrum实战》第1次课课后任务
1.必做任务:从知行角度总结T平台 从知行角度总结T平台 头(知识,学习) 做得好的 宣贯会 引入敏捷思想 敏捷宣言 敏捷原则 质量风险前移原则 引入最佳实践 包括了XP的大部分实践 不足 项目管理框 ...
- 光学字符识别OCR-8 综合评估
数据验证 尽管在测试环境下模型工作良好,但是实践是检验真理的唯一标准.在本节中,我们通过自己的模型,与京东的测试数据进行比较验证. 衡量OCR系统的好坏有两部分内容:(1)是否成功地圈 ...
- 自己做一款简易的chrome扩展--清除页面广告
大家肯定有这样的经历,浏览网页的时候,左右两端广告,诸如“屠龙宝刀,点击就送”,以及最近火的不行的林子聪37传奇霸业什么“霸业面具,霸业吊坠”的魔性广告总是充斥我们的眼球. 当然有现成的扩展程序或者插 ...
- Oralce重做日志(Redo Log)
1.简介 Oracle引入重做日志的目的:数据库的恢复. Oracle相关进程:重做日志写进程(LGWR). 重做日志性质:联机日志文件,oracle服务器运行时需要管理它们. 相关数据字典:v$lo ...
- JS手风琴特效
<!DOCTYPE html><html> <head> <meta charset="UTF-8"> <title>& ...
- [python工具][1]sublime安装与配置
http://www.cnblogs.com/wind128/p/4409422.html 1 官网下载版本 http://www.sublimetext.com/3 选择 Windows - al ...
- 区别Transform、Transition、Animation
另一篇参考文章:http://www.7755.me/Article/CSS3/39/ 近来上班之外就是研究研究CSS动画,下面是第一阶段总结.话说为加强记忆,实则想抛砖引玉! 标题直译一下就是: ...