HashMap,你知道多少?
一、前言
- HashMap的内部数据结构是什么?
- HashMap扩容机制时什么?什么时候扩容?
- HashMap其长度有什么特征?为什么是这样?
- HashMap为什么线程不安全?并发的场景会出现什么的情况?
二、源码解读
1、类的继承关系
public class HashMap<K,V> extends AbstractMap<K,V> implements Map<K,V>, Cloneable, Serializable
2、属性解析
2.1、capacity:容量
- DEFAULT_INITIAL_CAPACITY:默认的初始容量-必须是2的幂。为什么呢?先留个疑问在这
/**
* The default initial capacity - MUST be a power of two.
*/
static final int DEFAULT_INITIAL_CAPACITY = 1 << 4; // aka 16
- MAXIMUM_CAPACITY:最大容量为2^30。
2.2 threshold:阈值
/**
* The next size value at which to resize (capacity * load factor).
* @serial
*/
// If table == EMPTY_TABLE then this is the initial capacity at which the
// table will be created when inflated.
int threshold;
2.3 loadFactor:加载因子,默认为0.75
/**
* The load factor used when none specified in constructor.
*/
static final float DEFAULT_LOAD_FACTOR = 0.75f;
2.4 size:键值对长度
/**
* The number of key-value mappings contained in this map.
*/
transient int size;
2.5 modCount:修改内部结构的次数
transient int modCount;
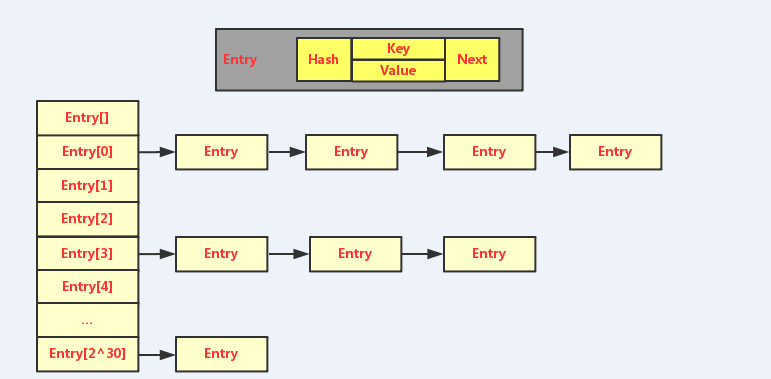
3、底层数据结构
static final Entry<?,?>[] EMPTY_TABLE = {};
/**
* The table, resized as necessary. Length MUST Always be a power of two.
* 这里也强调扩容时,长度必须是2的指数次幂
*/
transient Entry<K,V>[] table = (Entry<K,V>[]) EMPTY_TABLE;
static class Entry<K,V> implements Map.Entry<K,V> {
final K key;
V value;
Entry<K,V> next;
int hash;
}
4、重要函数
4.1 构造函数

public HashMap(int initialCapacity, float loadFactor) {
if (initialCapacity < 0)
throw new IllegalArgumentException("Illegal initial capacity: " +
initialCapacity);
if (initialCapacity > MAXIMUM_CAPACITY)
initialCapacity = MAXIMUM_CAPACITY;
if (loadFactor <= 0 || Float.isNaN(loadFactor))
throw new IllegalArgumentException("Illegal load factor: " +
loadFactor);
this.loadFactor = loadFactor;
threshold = initialCapacity;
// 供子类实现
init();
}
4.2 put()函数
public V put(K key, V value) {
// 1 如果table为空则需要初始化
if (table == EMPTY_TABLE) {
inflateTable(threshold);
}
// 2 如果key为空,则单独处理
if (key == null)
return putForNullKey(value);
// 3 根据key获取hash值
int hash = hash(key);
// 4 根据hash值和长度求取索引值。
int i = indexFor(hash, table.length);
// 5 根据索引值获取数组下的链表进行遍历,判断元素是否存在相同的key
for (Entry<K,V> e = table[i]; e != null; e = e.next) {
Object k;
if (e.hash == hash && ((k = e.key) == key || key.equals(k))) {
// 如果相等,则将新值替换旧值
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
// 6 如果不存在重复的key, 则需要创建新的Entry,然后添加至链表中。
// 先将修改次数加一
modCount++;
addEntry(hash, key, value, i);
return null;
}
- 第一步:当table还没有初始化时,看下inflateTable()函数做了什么操作。
private void inflateTable(int toSize) {
// Find a power of 2 >= toSize
int capacity = roundUpToPowerOf2(toSize);
// 其中阈值=容量*加载因子,然后再初始化数组。
threshold = (int) Math.min(capacity * loadFactor, MAXIMUM_CAPACITY + 1);
table = new Entry[capacity];
initHashSeedAsNeeded(capacity);
}
- 其中容量是根据toSize取第一个大于它的2的指数次幂的值, 如下,其中highestOneBit函数是返回其最高位的权值,用的最巧的就是(number - 1) << 1 其实就是取number的倍数, 但综合使用却能取得第一个大于等于该值的2的指数次幂。(用的牛逼)
private static int roundUpToPowerOf2(int number) {
// assert number >= 0 : "number must be non-negative";
return number >= MAXIMUM_CAPACITY
? MAXIMUM_CAPACITY
: (number > 1) ? Integer.highestOneBit((number - 1) << 1) : 1;
}
- 接着看put函数的第二步:当key为null时,会取数组下标为0的位置进行链表遍历,如果存在key=null,则替换值并返回。否则进入第六步(注意:索引值依然指定是0)。
private V putForNullKey(V value) {
// 取数组下标为0的链表
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null) {
V oldValue = e.value;
e.value = value;
e.recordAccess(this);
return oldValue;
}
}
modCount++;
// 注意:索引值依然指定是0
addEntry(0, null, value, 0);
return null;
}
- 第三步:根据key的hashCode求取hash值,这又是个神奇的算法,这里不做多解释。
final int hash(Object k) {
int h = hashSeed;
if (0 != h && k instanceof String) {
return sun.misc.Hashing.stringHash32((String) k);
}
h ^= k.hashCode();
// This function ensures that hashCodes that differ only by
// constant multiples at each bit position have a bounded
// number of collisions (approximately 8 at default load factor).
h ^= (h >>> 20) ^ (h >>> 12);
return h ^ (h >>> 7) ^ (h >>> 4);
}
- 第四步:根据hash值和底层数组的长度计算索引下标。因为数组的长度是2的幂,所以h & (length-1)运算其实就是h与(length-1)的取模运算。不得不服啊,将计算运用的如此高效。
static int indexFor(int h, int length) {
// assert Integer.bitCount(length) == 1 : "length must be a non-zero power of 2";
return h & (length-1);
}

- 第五步是验证是否有重复key,如果有则替换新值然后返回,源码很详细了就不再做解释了。
- 第六步:是将值添加到entry数组中,详细看下addEntry()函数。首先根据size和阈值判断是否需要扩容(进行两倍扩容),如果需要扩容则先扩容重新计算索引,则创建新的元素添加至数组。
void addEntry(int hash, K key, V value, int bucketIndex) {
// 如果长度大于阈值,则需要进行扩容
if ((size >= threshold) && (null != table[bucketIndex])) {
// 进行2倍扩容
resize(2 * table.length);
hash = (null != key) ? hash(key) : 0;
// 扩容之后因为长度变化了,需要重新计算下索引值。
bucketIndex = indexFor(hash, table.length);
}
// 然后进行添加元素
createEntry(hash, key, value, bucketIndex);
}
void createEntry(int hash, K key, V value, int bucketIndex) {
Entry<K,V> e = table[bucketIndex];
// 往表头插入
table[bucketIndex] = new Entry<>(hash, key, value, e);
size++;
}
void resize(int newCapacity) {
Entry[] oldTable = table;
int oldCapacity = oldTable.length;
// 两倍容量与最大容量取最小
if (oldCapacity == MAXIMUM_CAPACITY) {
threshold = Integer.MAX_VALUE;
return;
}
// 创建新数组
Entry[] newTable = new Entry[newCapacity];
// 拷贝数组(重新计算索引下标)
transfer(newTable, initHashSeedAsNeeded(newCapacity));
table = newTable;
// 重新计算阈值
threshold = (int)Math.min(newCapacity * loadFactor, MAXIMUM_CAPACITY + 1);
}
void transfer(Entry[] newTable, boolean rehash) {
int newCapacity = newTable.length;
for (Entry<K,V> e : table) {
while(null != e) {
// 定一个next
Entry<K,V> next = e.next;
if (rehash) {
e.hash = null == e.key ? 0 : hash(e.key);
}
// 重新计算索引下标。
int i = indexFor(e.hash, newCapacity);
// 头插法,
e.next = newTable[i];
newTable[i] = e;
// 接着下个节点继续遍历
e = next;
}
}
}
通过上面分析,其实put函数还是简单的,不是很绕。那么能从其中找到开头的第二和第三个问题的答案吗?下面总结下顺便回答下这两个问题:
- 能使元素均匀分布,增大空间利用率。put值时需要根据key的hash值与长度进行取模运算得到索引下标,如果是2的幂,那么length一定是偶数,则length-1一定是奇数,那么它对应的二进制的最后一位一定是1,所以它能保证h&(length-1)既能到奇数也能得到偶数,这样保证了散列的均匀性。相反如果不是2的幂,那么length-1可能是偶数,这样h&(length-1)得到的都是偶数,就会浪费一半的空间了。
- 运算效率高效。位运算比%运算高效。
- 加载因子越小,优点:存储的冲突机会减少;缺点:扩容次数越多(消耗性能就越大)、同时浪费空间较大(很多空间还没用,就开始扩容了)
- 加载因子越大,有点:扩容次数较少,空间利用率高;缺点:冲突几率就变大了、链表(后面介绍)长度会变长,查找的效率降低。
4.3、get()函数
public V get(Object key) {
if (key == null)
return getForNullKey();
Entry<K,V> entry = getEntry(key);
return null == entry ? null : entry.getValue();
}
第一步:如果key为空,则直接从table[0]所对应的链表中查找(应该还记得put的时候为null的key放在哪)。
private V getForNullKey() {
if (size == 0) {
return null;
}
for (Entry<K,V> e = table[0]; e != null; e = e.next) {
if (e.key == null)
return e.value;
}
return null;
}
final Entry<K,V> getEntry(Object key) {
if (size == 0) {
return null;
}
int hash = (key == null) ? 0 : hash(key);
for (Entry<K,V> e = table[indexFor(hash, table.length)];
e != null;
e = e.next) {
Object k;
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
return e;
}
return null;
}
三、并发场景中使用HashMap会怎么样?
1、肯定不能保证数据的安全性,因为内部方法没有一个是线程安全的。
2、有时会出现死锁情况。为什么呢?下面列个场景简单分析下:
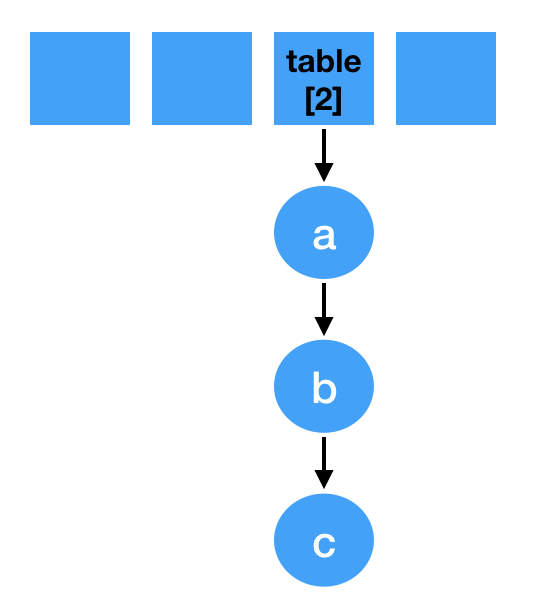
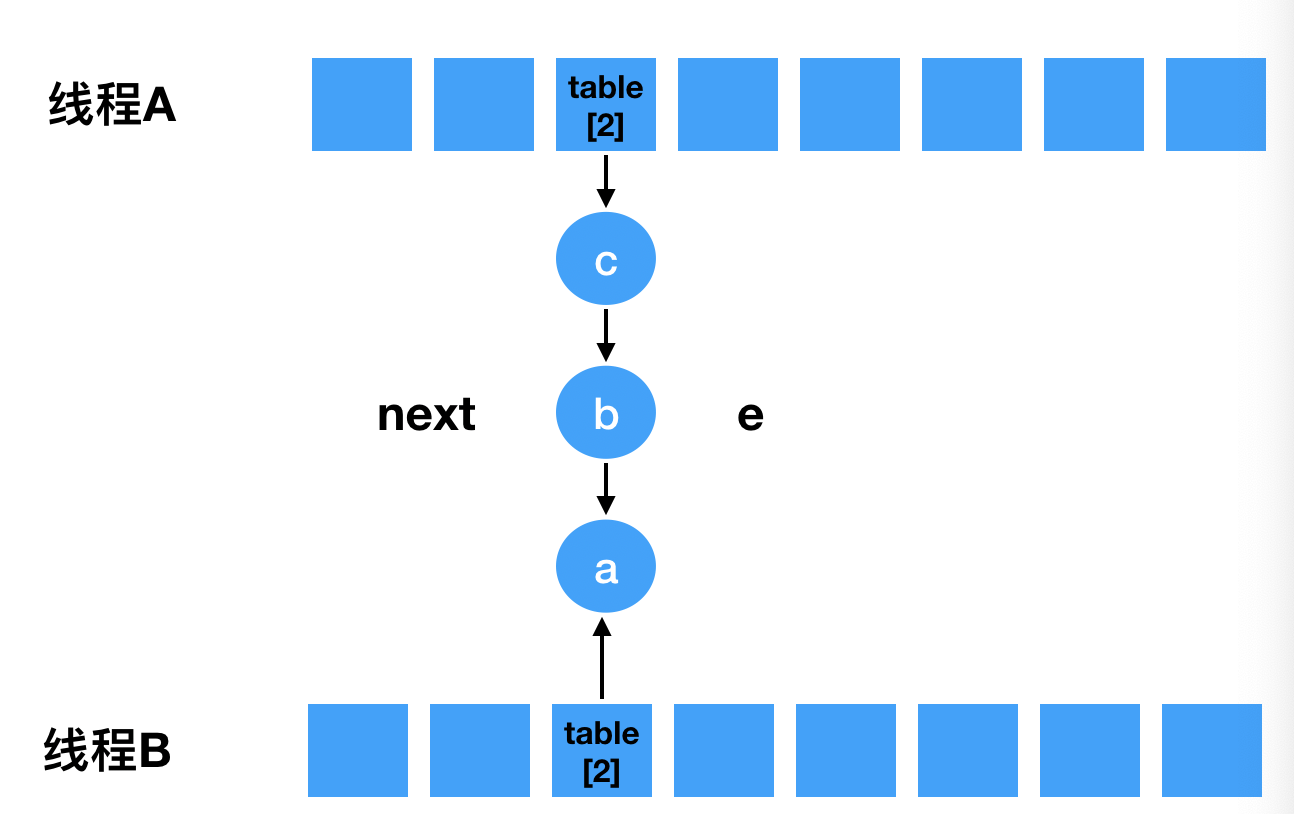
- 假设当前容量为4, 有三个元素(a, b, c)都在table[2]下的链表中,另一个元素(d)在table[3]下。如图
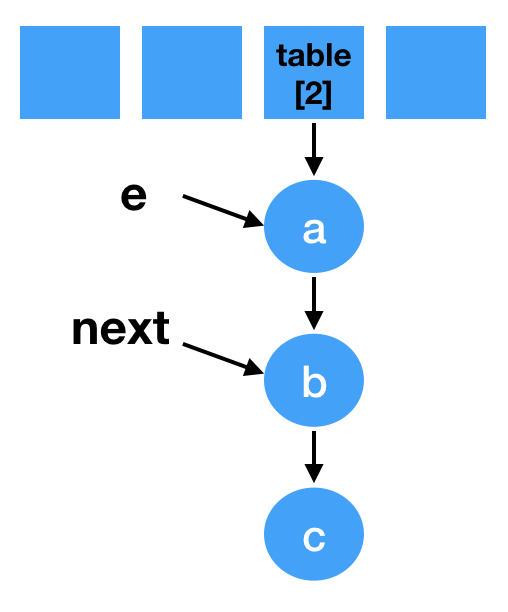
- 假设此时有A,B两个线程都要往map中put一个元素则都需要扩容,当遍历到table[2]时,假设线程B先进入循环体的第一步:e 指向a, next指向b, 如图:
Entry<K,V> next = e.next;
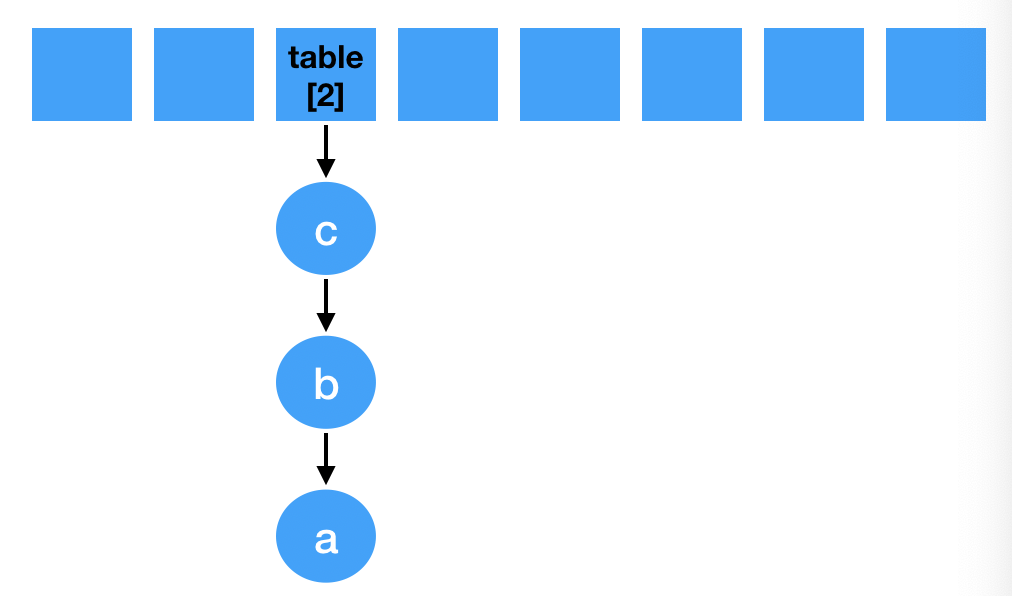
- 此时线程B让出时间片,让A线程一直执行完扩容操作,最终落位同样也是落位到table[2],其链表元素已经倒序了。如图:
- A线程让出时间片,B线程操作:接着循环继续执行,执行到循环末尾的时候,table[2] 指向a, 同时 e 和 next 都是指向b,如图:
// 同理落位到2
int i = indexFor(e.hash, newCapacity);
e.next = newTable[i];
// 指向a
newTable[i] = e;
e = next;
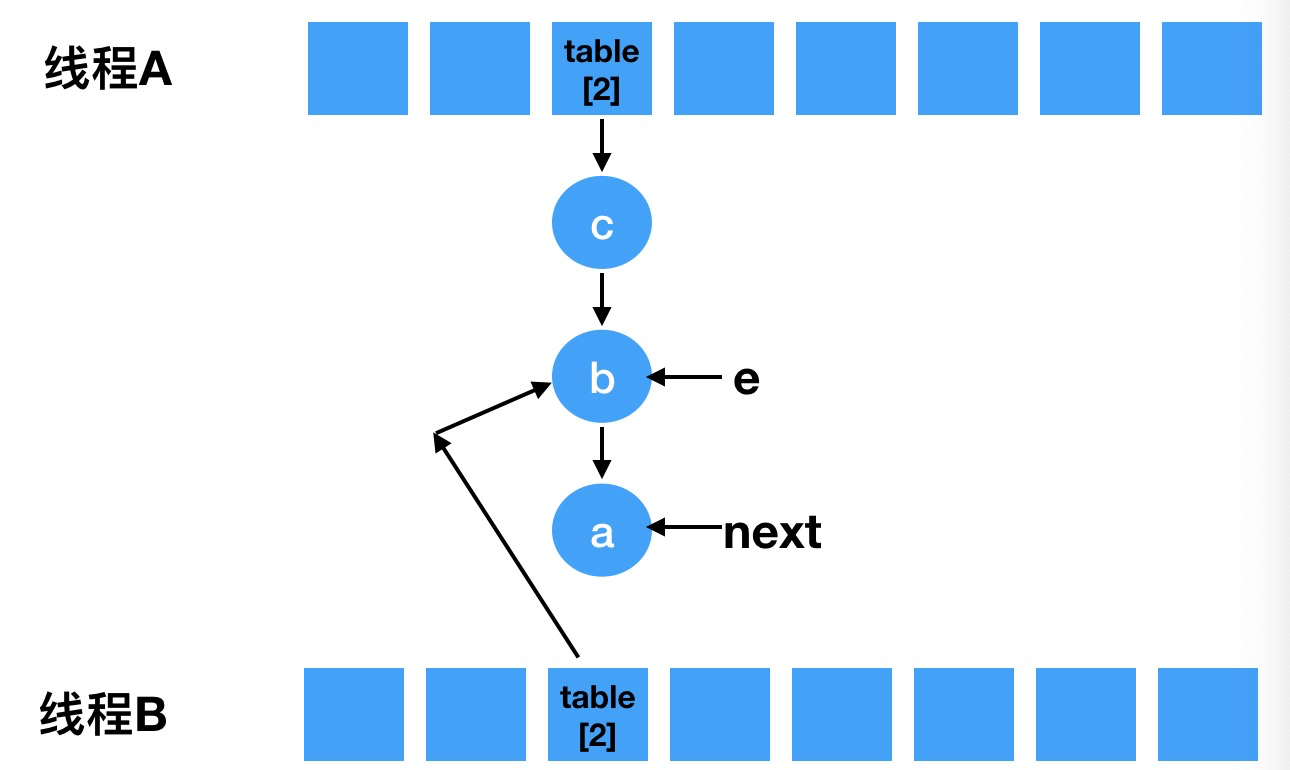
- 接着第二轮循环, e = b, next = a, 进行第二轮循环后的结果是e = next 且 table[2] 指向b元素,b元素再指向a元素,如图:
- 接着第三轮循环, e = a, a的下个元素为null, 所以next = null,但是当执行到下面这步就改变形式了,e.next 又指向了b,此时a和b已经出现了环形。因为next = null,所以终止了循环。
e.next = newTable[i];
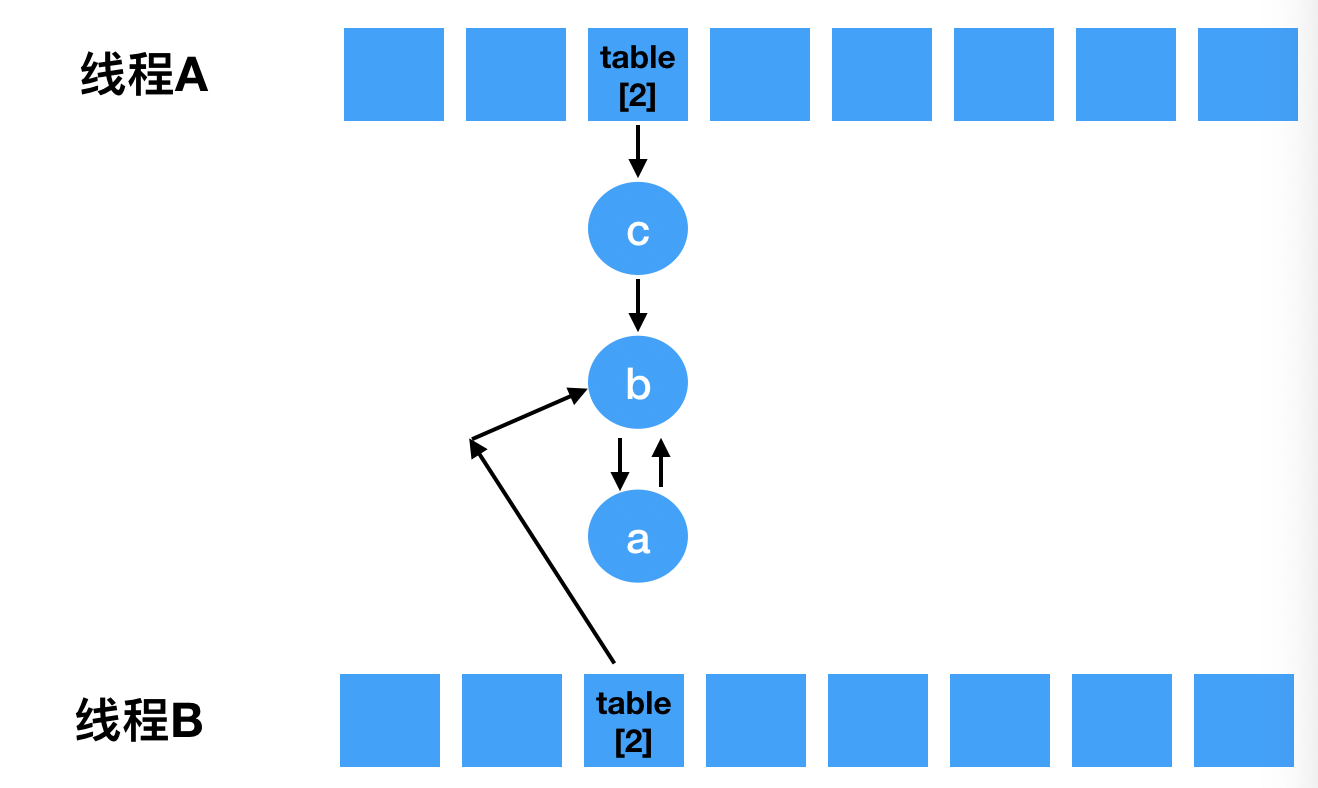
- 此时,问题还没有直接产生。当调用get()函数查找一个不存在的Key,而这个Key的Hash结果恰好等于3的时候,由于位置3带有环形链表,所以程序将会进入死循环!(上面图形均忽略四个元素和要插入元素的规划)
四、怎样合理使用HashMap?
- 1、创建HashMap时,指定足够大的容量,减少扩容次数。最好为:需要存的实际个数/除以加载因子。可以使用guava包中的Maps.newHashMapWithExpectedSize()方法。
- 2、不要在并发场景中使用HashMap,如硬要使用通过Collections工具类创建线程安全的map,如:Collections.synchronizedMap(new HashMap<String, Object>());
HashMap,你知道多少?的更多相关文章
- HashMap与TreeMap源码分析
1. 引言 在红黑树--算法导论(15)中学习了红黑树的原理.本来打算自己来试着实现一下,然而在看了JDK(1.8.0)TreeMap的源码后恍然发现原来它就是利用红黑树实现的(很惭愧学了Ja ...
- HashMap的工作原理
HashMap的工作原理 HashMap的工作原理是近年来常见的Java面试题.几乎每个Java程序员都知道HashMap,都知道哪里要用HashMap,知道HashTable和HashMap之间 ...
- 计算机程序的思维逻辑 (40) - 剖析HashMap
前面两节介绍了ArrayList和LinkedList,它们的一个共同特点是,查找元素的效率都比较低,都需要逐个进行比较,本节介绍HashMap,它的查找效率则要高的多,HashMap是什么?怎么用? ...
- Java集合专题总结(1):HashMap 和 HashTable 源码学习和面试总结
2017年的秋招彻底结束了,感觉Java上面的最常见的集合相关的问题就是hash--系列和一些常用并发集合和队列,堆等结合算法一起考察,不完全统计,本人经历:先后百度.唯品会.58同城.新浪微博.趣分 ...
- 学习Redis你必须了解的数据结构——HashMap实现
本文版权归博客园和作者吴双本人共同所有,转载和爬虫请注明原文链接博客园蜗牛 cnblogs.com\tdws . 首先提供一种获取hashCode的方法,是一种比较受欢迎的方式,该方法参照了一位园友的 ...
- HashMap与HashTable的区别
HashMap和HashSet的区别是Java面试中最常被问到的问题.如果没有涉及到Collection框架以及多线程的面试,可以说是不完整.而Collection框架的问题不涉及到HashSet和H ...
- JDK1.8 HashMap 源码分析
一.概述 以键值对的形式存储,是基于Map接口的实现,可以接收null的键值,不保证有序(比如插入顺序),存储着Entry(hash, key, value, next)对象. 二.示例 public ...
- HashMap 源码解析
HashMap简介: HashMap在日常的开发中应用的非常之广泛,它是基于Hash表,实现了Map接口,以键值对(key-value)形式进行数据存储,HashMap在数据结构上使用的是数组+链表. ...
- java面试题——HashMap和Hashtable 的区别
一.HashMap 和Hashtable 的区别 我们先看2个类的定义 public class Hashtable extends Dictionary implements Map, Clonea ...
- 再谈HashMap
HashMap是一个高效通用的数据结构,它在每一个Java程序中都随处可见.先来介绍些基础知识.你可能也知 道,HashMap使用key的hashCode()和equals()方法来将值划分到不同的桶 ...
随机推荐
- 火狐浏览器安装VULTR笔记
1.购买一台vultr服务器, 支持支付宝扫码支付,直接美刀转人民币实时结算:优先选日本的,然后美国的; 购买服务器步骤: Server Location: Tokyo Japan Server Ty ...
- HDU3466(01背包变种)
Proud Merchants Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/65536 K (Java/Others) ...
- 【旧文章搬运】深入分析Win7的对象引用跟踪机制
原文发表于百度空间及看雪论坛,2010-09-12 看雪论坛地址:https://bbs.pediy.com/thread-120296.htm============================ ...
- eclipse项目从编程到打jar包到编写BashShell执行
eclipse项目从编程到打jar包到编写BashShell执行 一.创建Java项目,并编写项目(带额外jar包) 二.打jar包 三.编写BashShell执行 其中一以及二可以参考我的博客 Ec ...
- CF-805C
C. Find Amir time limit per test 1 second memory limit per test 256 megabytes input standard input o ...
- 3-C++程序的结构1.3
类的友元 一个类之外的函数,又与该类有特殊关系! 友元关系提供了不同类或对象的成员函数之间.类的成员函数与一般函数之间进行数据共享的机制.通俗地说,友元关系就是一个类主动声明那些其他类或函数是它的朋友 ...
- UVaLive 3905 Meteor (扫描线)
题意:给定上一个矩形照相机和 n 个流星,问你照相机最多能拍到多少个流星. 析:直接看,似乎很难解决,我们换一个思路,我们认为流星的轨迹就没有用的,我们可以记录每个流星每个流星在照相机中出现的时间段, ...
- POJ - 3126 Prime Path 素数筛选+BFS
Prime Path The ministers of the cabinet were quite upset by the message from the Chief of Security s ...
- 区间sum 和为k的连续区间-前缀和
区间sum 描述 有一个长度为n的正整数序列a1--an,candy想知道任意区间[L,R]的和,你能告诉他吗? 输入 第一行一个正整数n(0<n<=1e6),第二行为长度为n的正整数序列 ...
- C#backgroundWorker用法
1.在 WinForms 中,有时要执行耗时的操作,在该操作未完成之前操作用户界面,会导致用户界面停止响应.解决的方法就是新开一个线程,把耗时的操作放到线程中执行,这样就可以在用户界面上进行其它操作. ...