mysql 添加数据如果数据存在就更新ON DUPLICATE KEY UPDATE和REPLACE INTO
#下面建立game表,设置name值为唯一索引。
CREATE TABLE `game` (
`id` int(11) NOT NULL AUTO_INCREMENT,
`name` varchar(20) CHARACTER SET utf8 NOT NULL,
`type_id` tinyint(4) NOT NULL DEFAULT '0',
`attr` varchar(20) NOT NULL,
`type_extends` varchar(20) NOT NULL,
PRIMARY KEY (`id`),
UNIQUE KEY `name` (`name`) USING BTREE
) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4

对于ON DUPLICATE KEY UPDATE语句:
MySQL手册:如果您指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY KEY中出现重复值,则执行旧行UPDATE。
这里的意思是说要设置记录不存在就添加存在就更新,必须在添加这个记录的时候唯一索引和主键发生相同才能触发。
#当我们试图插入一条已经存在的唯一索引name值记录,提示:[Err] 1062 - Duplicate entry '游戏4' for key 'name'
INSERT INTO game SET `name`='游戏4',`type_id`='5',`attr`='无敌游戏',`type_extends`='5'
#下面是使用ON DUPLICATE KEY UPDATE,如果插入记录的时候存在唯一索引和主键重复的记录,那么就执行更新操作
INSERT INTO game SET `name`='游戏4',`type_id`='5',`attr`='无敌游戏',`type_extends`='5'
ON DUPLICATE KEY UPDATE `type_id`='5',`attr`='无敌游戏',`type_extends`='5'
对于使用ON DUPLICATE KEY UPDATE子句如果记录不存在执行添加那么影响行数是一行,如果存在进行更新,如果更新发现没有变化那么影响行数为0,否则影响行数是两行。
对于REPLACE INTO语句
MSQL手册:REPLACE的运行与INSERT很相像。只有一点除外,如果表中的一个旧记录与一个用于PRIMARY KEY或一个UNIQUE索引的新记录具有相同的值,则在新记录被插入之前,旧记录被删除。
注意,除非表有一个PRIMARY KEY或UNIQUE索引,否则,使用一个REPLACE语句没有意义。该语句会与INSERT相同,因为没有索引被用于确定是否新行复制了其它的行。
意思是说,对于REPLACE INTO语句如果发现存在记录那么先将记录删除在插入新记录。
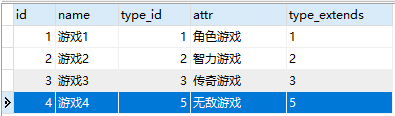
表中原有记录是:
#运行语句:
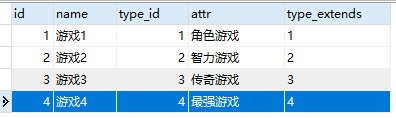
REPLACE INTO game SET `name`='游戏4',attr='最强的游戏2',type_extends='最强的游戏2_4'
这里的id是设置自动增长主键,这里有两处特别的地方,1是自动增长的id变大了,2是type_id变成0了
在MySQL手册:所有列的值均取自在REPLACE语句中被指定的值。所有缺失的列被设置为各自的默认值,这和INSERT一样。您不能从当前行中引用值,也不能在新行中使用值。如果您使用一个例如“SET col_name = col_name + 1”的赋值,则对位于右侧的列名称的引用会被作为DEFAULT(col_name)处理。因此,该赋值相当于SET col_name = DEFAULT(col_name) + 1。
这里意思是说在REPLACE语句中没有设置的列会被设置成默认值,这里的type_id的默认值是0所以这里被设置成0了,这里也很好理解,因为REPLACE语句是先删除后插入了,而新插入数据如果没有设置值那么就是默认值了。所以下面的语句得到的结果也是不是预期的结果:
#这里的语句得到的结果type_id为1,因为type_id默认值为0。这里的type_id=type_id+1相当于type_id=DEFAULT(type_id) +1
REPLACE INTO game SET `name`='游戏4',type_id=type_id+1,attr='最强的游戏2',type_extends='最强的游戏2_4'
对于REPLACE INTO语句如果记录不存在那么执行添加影响行数为一行,否则执行删除后添加影响行数为两行。
对于存在记录就修改,不存在就添加记录的处理ON DUPLICATE KEY UPDATE和REPLACE INTO语句的区别:
ON DUPLICATE KEY UPDATE语句:是根据主键或者唯一索引判断是否存在记录,如果存在记录那么通过UPDATE子句更新记录内容,只更新UPDATE子句中设置的字段,对于没有设置的字段保持原状,因为是修改语句所以不会对自动增长字段做变化。
语句的返回值有:
0:发现有相同的唯一索引或者主键的记录,执行更新语句,但是更新语句中的字段内容和现有的字段内容一致执行结果没有发生变化;
1:发现没有相同的唯一索引或者主键的记录,直接执行插入语句;
2:发现有相同的唯一索引或者主键的记录,执行更新语句,并且更新语句中的字段内容和现有的字段内容一致执行结果发生变化;
REPLACE INTO语句:是根据主键或者唯一索引判断是否存在记录,如果存在记录那么就删除记录然后将当前语句中的字段内容执行INSERT。因为是删除后再INSERT,所以对自动增长字段做变化。
语句的返回值有:
1:发现没有相同的唯一索引或者主键的记录,直接执行插入语句;
2:发现有相同的唯一索引或者主键的记录,先删除指定语句再进行INSERT语句,这里要注意在执行INSERT的时候如果在REPLACE INTO语句中没有设置的字段那么就会是以默认值填充;
对于ON DUPLICATE KEY UPDATE语句在MySQL手册中有这样一句:
在一个INSERT … ON DUPLICATE KEY UPDATE …语句中,你可以在UPDATE 子句中使用 VALUES(col_name)函数,用来访问来自该语句的INSERT 部分的列值。换言之,UPDATE 子句中的 VALUES(col_name) 访问需要被插入的col_name 的值,并不会发生重复键冲突。
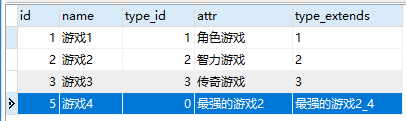
原表中数据:

INSERT INTO game SET `name`='游戏4',`type_id`='4',`attr`='无敌游戏',`type_extends`='无敌游戏_4'
ON DUPLICATE KEY UPDATE `type_extends`=CONCAT(VALUES(attr),'_',VALUES(type_id))
结果数据:

mysql 添加数据如果数据存在就更新ON DUPLICATE KEY UPDATE和REPLACE INTO的更多相关文章
- MySQL插入更新_ON DUPLICATE KEY UPDATE
前提:操作的表具有主键或唯一索引 INSERT INTO:表中不存在对应的记录,则插入:若存在对应的记录,则报错: INSERT INTO IGNORE:表中不存在对应的记录,则插入:若存在对应的记录 ...
- mysql ON DUPLICATE KEY UPDATE、REPLACE INTO
INSERT INTO ON DUPLICATE KEY UPDATE 与 REPLACE INTO,两个命令可以处理重复键值问题,在实际上它之间有什么区别呢?前提条件是这个表必须有一个唯一索引或主键 ...
- mysql插入数据时 insert IGNORE、ON DUPLICATE KEY UPDATE、replace into
转: mysql insert时几个操作DELAYED .IGNORE.ON DUPLICATE KEY UPDATE的区别 博客分类: mysql基础应用 mysql insert时几个操作DE ...
- mysql 插入更新判断 ON DUPLICATE KEY UPDATE 和 REPLACE INTO
平时我们在设计数据库表的时候总会设计 unique 或者 给表加上 primary key 的限制条件.此时 插入数据的时候 ,经常会有这样的情况:我们想向数据库插入一条记录: 若数据表中存在以相同主 ...
- mysql:on duplicate key update与replace into
在往表里面插入数据的时候,经常需要:a.先判断数据是否存在于库里面:b.不存在则插入:c.存在则更新 一.replace into 前提:数据库里面必须有主键或唯一索引,不然replace into ...
- MySQL_插入更新 ON DUPLICATE KEY UPDATE
平时我们在设计数据库表的时候总会设计 unique 或者 给表加上 primary key 的限制条件. 此时 插入数据的时候 ,经常会有这样的情况: 我们想向数据库插入一条记录: 若数据表中存在以 ...
- mysql ON DUPLICATE KEY UPDATE 与 REPLACE INTO 的区别
#mysql ON DUPLICATE KEY UPDATE 如果在INSERT语句末尾指定了ON DUPLICATE KEY UPDATE,并且插入行后会导致在一个UNIQUE索引或PRIMARY ...
- MySQL-插入更新 ON DUPLICATE KEY UPDATE
向数据库中插入一条记录,若该数据的主键值(UNIQUE KEY)已经在表中存在,则执行后面的 UPDATE 操作.否则执行前面的 INSERT 操作. 测试表结构 CREATE TABLE `flum ...
- MySql中4种批量更新的方法update table2,table1,批量更新用insert into ...on duplicate key update, 慎用replace into.
mysql 批量更新记录 MySql中4种批量更新的方法最近在完成MySql项目集成的情况下,需要增加批量更新的功能,根据网上的资料整理了一下,很好用,都测试过,可以直接使用. mysql 批量更新共 ...
随机推荐
- linux 查看系统版本号(转)
一.查看Linux内核版本命令(两种方法): 1.cat /proc/version [root@localhost ~]# cat /proc/versionLinux version 2.6.18 ...
- 2016 CCPC-Final
A.The Third Cup is Free #include <bits/stdc++.h> using namespace std; typedef long long ll; in ...
- JavaScript进阶 - 第9章 DOM对象,控制HTML元素
第9章 DOM对象,控制HTML元素 9-1 认识DOM 文档对象模型DOM(Document Object Model)定义访问和处理HTML文档的标准方法.DOM 将HTML文档呈现为带有元素.属 ...
- jquery获取文档高度和窗口高度汇总
jquery获取窗口高度和窗口高度,$(document).height().$(window).height() $(document).height():整个网页的文档高度 $(window).h ...
- easyui---panel(面板)
panel笔记: EASYUI panel: class:easyui-panel,带有title 打开:onclick="javascript:$('#c').panel('open')& ...
- hdu2177----取(2堆)石子游戏
威佐夫博弈博弈论 直接模拟即可 值得一提的是这道题几乎网上所有题解都没有考虑只从小堆取得情况 所以在类似 19 20这种数据出现时,他们都是错误的 只输出了 1 2 而没有 12 20 #includ ...
- Ubuntu安装Python2+Python3
sudo apt-get install python2.7 python2.7-dev sudo apt-get install python3 命令: python 默认执行python2 pyt ...
- T-SQL多个小计+合计,分类汇总
select then '合计' else cast(姓名 as varchar) end 姓名, then '姓名小计' else cast(学期 as varchar) end 学期, case ...
- python Fuction 方法的调用
def display():#无参数 print("No") return # display() def callfun():#调用 print("2") d ...
- 切记切记:Spring配置文件中,Component-scan无法扫描到的类中的自动装配对象无法被调用,报空指针错误。
Spring单例注入,单例对象可设置成Spring元件. 只有Spring的元件中@Autowired才有用,在普通类中@Autowired虽然不会编译报错,但运行时会报空指针错误.