centos 6.9 x86 安装搭建hadoop集群环境
又来折腾hadoop了
文件准备:
centos 6.9 x86 minimal版本
163的源 下软件的时候可能会用到
jdk-8u144-linux-i586.tar.gz
ftp工具
putty ssh远程连接linux
hadoop 2.7.3 32 位
准备3个linux操作系统环境
hadoop.master 192.168.168.11
hadoop.slave1 192.168.168.12
hadoop.slave2 192.168.168.13
只用安装一个linux操作系统就行了,然后其他的都可以通过克隆,比较方便
安装了第一个hadoop.master之后,这时不能通过ssh连上去,用通过虚拟机登录进去修改
vi /etc/sysconfig/network-scripts/ifcfg-eth0
大概修改为以下这样:
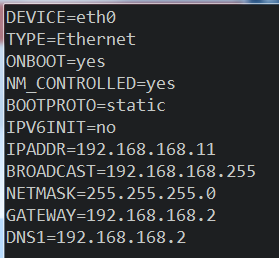
关于虚拟机中设置静态ip的可以参考这个:vmware下为CentOS7设置静态IP
设置完了之后,就可以把这个克隆出另外连个,此时需要再次改一下ip地址。
克隆之后,用ifconfig -a这两个命令看一下有哪些网卡,然后看下/etc/sysconfig/network-scripts/ifcfg-eth0和这个是不是匹配的,如果不匹配重命名成ifconfig -a查出来的,并且修改ifcfg-eth中的device属性值
bringing up interface eth0: Device eth0 dose not seem to be present
设置163的源
#!/bin/sh # 下载163 yum源的文件
curl -O http://mirrors.163.com/.help/CentOS6-Base-163.repo # 备份原来的配置文件
mv /etc/yum.repos.d/CentOS-Base.repo /etc/yum.repos.d/CentOS-Base.repo.backup # 重命名163的配置文件
mv ./CentOS6-Base-163.repo /etc/yum.repos.d/CentOS-Base.repo # 生成缓存
yum clean all
yum makecache
安装Java的脚本,写的很挫
#!/bin/bash DIR=/usr/local/ # 判断java命令是否存在, 如果存在则退出本次java的安装
command -v java >/dev/null 2>&1 && { echo >&2 "系统中已经安装了java, 请确认"; exit 1; } # 判断压缩包是否存在, 如果不存则继续本次的安装
if [ ! -f $1 ]; then
echo "压缩包$1不存在, 请确认"
fi # 解压jdk的压缩包到指定目录
tar zxf $1 -C $DIR # 目测如果/usr/local中有了相同的文件之后, 解压的时候会覆盖 # 获取解压之后目录的名称
unfoldName=`tar tf $1 | head -n 1`
echo $unfoldName JAVA_HOME=$DIR$unfoldName
JAVA_HOME=${JAVA_HOME%?}
echo "看下去掉最后一个字符的效果如何:$JAVA_HOME" CLASSPATH=$JAVA_HOME/lib/ sed -i '/JAVA_HOME/d' /etc/profile echo "JAVA_HOME=$JAVA_HOME" >> /etc/profile
echo 'CLASSPATH=$JAVA_HOME/lib/' >> /etc/profile
echo 'PATH=$PATH:$JAVA_HOME/bin' >> /etc/profile
echo 'export PATH JAVA_HOME CLASSPATH' /etc/profile source /etc/profile
java -version && echo "java安装成功"
反正是可以用了,之前写过但是没有存档,就蛋疼了
1 #!/bin/bash
2 # 配置无密码登录
3 # 以下是ip列表
4 ip_array=("192.168.168.11" "192.168.168.12" "192.168.168.13")
5 host_array=("hadoop.master" "hadoop.slave1" "hadoop.slave2")
6 NUM_OF_HOSTS=3
7 user="root"
8 remote_cmd="rm -rf /root/.ssh > /dev/null; \
9 ssh-keygen -t rsa -P '' -f /root/.ssh/id_rsa > /dev/null; \
10 cat ~/.ssh/id_rsa.pub"
11 port="22"
12 for ip in ${ip_array[*]}
13 do
14 if [ $ip = "192.168.168.11" ]; then
15 rm -rf /root/.ssh
16 ssh-keygen -t rsa -P '' -f /root/.ssh/id_rsa
17 cat ~/.ssh/id_rsa.pub >> /root/.ssh/authorized_keys
18 else
19 ssh -o StrictHostKeyChecking=no -t -p $port $user@$ip "$remote_cmd" >> /root/.ssh/authorized_keys
20 fi
21 done
22
23 # 把master服务器的authorized_keys、known_hosts复制到Slave服务器的/root/.ssh目录
24 #scp 远程用户名@IP地址:文件的绝对路径 本地Linux系统路径
25
26 for ip in ${ip_array[*]}
27 do
28 if [ $ip != "192.168.168.11" ]; then
29 scp /root/.ssh/authorized_keys $user@$ip:/root/.ssh/authorized_keys
30 fi
31 done
32
33 # 把主机名加入到/etc/hosts中
34 for ip in ${ip_array[*]}
35 do
36 for ((I=0; I<$NUM_OF_HOSTS; ++I))
37 do
38 del_host_map="sed -i '/${ip_array[I]}/d' /etc/hosts"
39 add_host_map="echo \"${ip_array[I]} ${host_array[I]}\" >> /etc/hosts"
40 echo "$del_host_map; $add_host_map"
41 ssh -o StrictHostKeyChecking=no -t -p $port $user@$ip "rm -rf /etc/host; $del_host_map; $add_host_map"
42 done
43 done
44
45 jdk_package=/root/packages/jdk-8u144-linux-i586.tar.gz
46
47 # 安装java
48 for ip in ${ip_array[*]}
49 do
50 if [ $ip != "192.168.168.11" ]; then
51 clear_file="rm -rf /root/packages; rm -rf /root/scritps"
52 ssh -o StrictHostKeyChecking=no -t -p $port $user@$ip "rm -rf /root/packages; rm -rf /root/scritps"
53 scp -r /root/scripts $user@$ip:/root/ > /dev/null
54 scp -r /root/packages $user@$ip:/root/ > /dev/null
55 install_java="rm -rf /packages; chmod -R a+x /root/scripts; /root/scripts/install_java.sh $jdk_package; /root/scripts/install_hadoop.sh"
56 ssh -o StrictHostKeyChecking=no -t -p $port $user@$ip "$install_java"
57 else
58 /root/scripts/install_java.sh
59 /root/scripts/install_hadoop.sh
60 fi
61 done
1 #!/bin/bash
2
3 # hadoop 2.7.4的安装包在/root/packages中
4
5 rm -rf /usr/local/hadoop*
6
7 hadoop_binary=/root/packages/hadoop-2.7.4.tar.gz
8
9 unfoldName=`tar tf $hadoop_binary | head -n 1`
10 DIR=/usr/local/
11
12 tar -zxf /root/packages/hadoop-2.7.4.tar.gz -C $DIR
13
14 echo "hadoop解压完成"
15 HADOOP_HOME=$DIR$unfoldName
16 HADOOP_HOME=${HADOOP_HOME%?} # 去掉最后的分隔符/
17
18 echo "看一下HADOOP_HOME=$HADOOP_HOME"
19 # 在/home/hadoop目录下创建数据存放的文件夹,tmp、hdfs、hdfs/data、hdfs/name
20
21 mkdir $HADOOP_HOME/tmp $HADOOP_HOME/hdfs $HADOOP_HOME/hdfs/data $HADOOP_HOME/hdfs/name
22
23 # 修改/usr/local/hadoop-2.7.4/etc/hadoop/core-site.xml
24 sed -i "/<configuration>/a\\
25 <property>\n\
26 <name>fs.defaultFS</name>\n\
27 <value>hdfs://192.168.168.11:9000</value>\n\
28 </property>\n\
29 <property>\n\
30 <name>hadoop.tmp.dir</name>\n\
31 <value>file:$HADOOP_HOME/tmp</value>\n\
32 </property>\n\
33 <property>\n\
34 <name>io.file.buffer.size</name>\n\
35 <value>131702</value>\n\
36 </property>" $HADOOP_HOME/etc/hadoop/core-site.xml
37
38 # 修改/usr/local/hadoop-2.7.4/etc/hadoop/hdfs-site.xml
39
40 hadoop_data=$HADOOP_HOME/hdfs/data
41 hadoop_name=$HADOOP_HOME/hdfs/name
42
43 sed -i "/<configuration>/a\\
44 <property>\n\
45 <name>dfs.namenode.name.dir</name>\n\
46 <value>file:${hadoop_name}</value>\n\
47 </property>\n\
48 <property>\n\
49 <name>dfs.datanode.data.dir</name>\n\
50 <value>file:${hadoop_data}</value>\n\
51 </property>\n\
52 <!-- 设置副本 -->\n\
53 <property>\n\
54 <name>dfs.replication</name>\n\
55 <value>2</value>\n\
56 </property>\n\
57 <property>\n\
58 <name>dfs.permissions</name>\n\
59 <value>false</value>\n\
60 </property>" $HADOOP_HOME/etc/hadoop/hdfs-site.xml
61
62
63 cp $HADOOP_HOME/etc/hadoop/mapred-site.xml.template $HADOOP_HOME/etc/hadoop/mapred-site.xml
64
65 # 修改mapred-site.xml
66
67 sed -i "/<configuration>/a\\
68 <property>\n\
69 <name>mapreduce.framework.name</name>\n\
70 <value>yarn</value>\n\
71 </property>" $HADOOP_HOME/etc/hadoop/mapred-site.xml
72
73 # 修改yarn-site.xml
74
75 sed -i "/<configuration>/a\\
76 <property>\n\
77 <name>yarn.nodemanager.aux-services</name>\n\
78 <value>mapreduce_shuffle</value>\n\
79 </property>\n\
80 <property>\n\
81 <name>yarn.log-aggregation-enable</name>\n\
82 <value>true</value>\n\
83 </property>\n\
84 <property>\n\
85 <description>The hostname of the RM.</description>\n\
86 <name>yarn.resourcemanager.hostname</name>\n\
87 <value>192.168.168.11</value>\n\
88 </property>" $HADOOP_HOME/etc/hadoop/yarn-site.xml
89
90
91 # 修改slave
92 echo "192.168.168.11" > $HADOOP_HOME/etc/hadoop/slaves
93 echo "192.168.168.12" >> $HADOOP_HOME/etc/hadoop/slaves
94 echo "192.168.168.13" >> $HADOOP_HOME/etc/hadoop/slaves
95
96 # 修改hadoop-env.sh
97 java_home=/usr/local/`ls /usr/local | grep "jdk1"`
98 echo "java_home=$java_home"
99 sed -i -e 's!^export JAVA_HOME.*$!'"export JAVA_HOME=$java_home"'!' $HADOOP_HOME/etc/hadoop/hadoop-env.sh
100 echo "修改hadoop env的java_home"
101 # 修改yarn-env.sh
102 sed -i '# export JAVA_HOME=/a\'"export JAVA_HOME=$java_home" $HADOOP_HOME/etc/hadoop/yarn-env.sh
103
104
105 service iptables stop
106 chkconfig iptables off
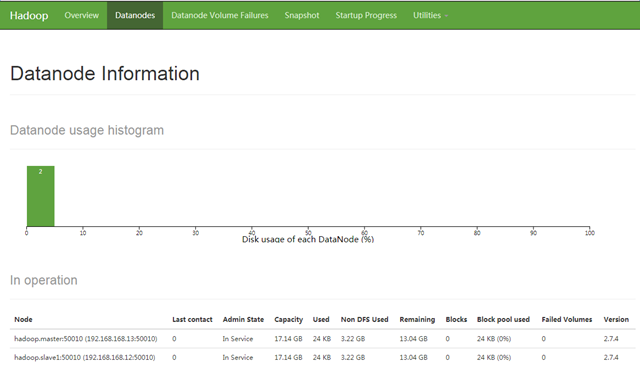
有了这几个脚本,跑hadoop再也不难了,哈哈
遇到的问题
解决hadoop中 bin/hadoop fs -ls ls: `.': No such file or directory问题
出现这样的问题确实很苦恼。。。使用的是2.7版本。。一般论坛上的都是1.x的教程,搞死人
在现在的2.x版本上的使用bin/hadoop fs -ls /就有用
应该使用绝对路径就不会有问题。。。。mkdir也是一样的。。具体原因不知,我使用相对路径会出现错误。。。。
centos 6.9 x86 安装搭建hadoop集群环境的更多相关文章
- 在搭建Hadoop集群环境时遇到的一些问题
最近在学习搭建hadoop集群环境,在搭建的过程中遇到很多问题,在这里做一些记录.1. SSH相关的问题 问题一: ssh: connect to host localhost port 22: Co ...
- Spark集群环境搭建——Hadoop集群环境搭建
Spark其实是Hadoop生态圈的一部分,需要用到Hadoop的HDFS.YARN等组件. 为了方便我们的使用,Spark官方已经为我们将Hadoop与scala组件集成到spark里的安装包,解压 ...
- 从VMware虚拟机安装到hadoop集群环境配置详细说明(第一期)
http://blog.csdn.net/whaoxysh/article/details/17755555 虚拟机安装 我安装的虚拟机版本是VMware Workstation 8.04,自己电脑上 ...
- ubuntu16.04搭建hadoop集群环境
1. 系统环境Oracle VM VirtualBoxUbuntu 16.04Hadoop 2.7.4Java 1.8.0_111 master:192.168.19.128slave1:192.16 ...
- CentOS7 安装Hadoop集群环境
先按照上一篇安装与配置好CentOS以及zookeeper http://www.cnblogs.com/dopeter/p/4609276.html 本章介绍在CentOS搭建Hadoop集群环境 ...
- 使用Windows Azure的VM安装和配置CDH搭建Hadoop集群
本文主要内容是使用Windows Azure的VIRTUAL MACHINES和NETWORKS服务安装CDH (Cloudera Distribution Including Apache Hado ...
- hadoop集群环境搭建之zookeeper集群的安装部署
关于hadoop集群搭建有一些准备工作要做,具体请参照hadoop集群环境搭建准备工作 (我成功的按照这个步骤部署成功了,经实际验证,该方法可行) 一.安装zookeeper 1 将zookeeper ...
- hadoop集群环境搭建之安装配置hadoop集群
在安装hadoop集群之前,需要先进行zookeeper的安装,请参照hadoop集群环境搭建之zookeeper集群的安装部署 1 将hadoop安装包解压到 /itcast/ (如果没有这个目录 ...
- 使用yum安装CDH Hadoop集群
使用yum安装CDH Hadoop集群 2013.04.06 Update: 2014.07.21 添加 lzo 的安装 2014.05.20 修改cdh4为cdh5进行安装. 2014.10.22 ...
随机推荐
- div两侧的boder断开 消失 奇怪
原文发布时间为:2009-11-06 -- 来源于本人的百度文章 [由搬家工具导入] 解决方法: 设定外层DIV的宽度即可,如 width:99% ========================== ...
- 完美CSS文档的8个最佳实践
在css的世界,文档没有被得到充分的利用.由于文档对终端用户不可见,因此它的价值常常被忽视.另外,如果你第一次为css编写文档,可能很难确定哪些内容值得记录,以及如何能够高效完成编写. 然而,为C ...
- 前端知识点总结——CSS
1.CSS的概述 1.什么是CSS? CSS:Cascading Style Sheets层叠样式表,级联样式表(简称:样式表) 2.作用 设置HTML网页元素的样式 3.HTML与CSS的关系 HT ...
- hdu 3549 Flow Problem 最大流 Dinic
题目链接 题意 裸的最大流. 学习参考 http://www.cnblogs.com/SYCstudio/p/7260613.html Code #include <bits/stdc++.h& ...
- LeetCode总结【转】
转自:http://blog.csdn.net/lanxu_yy/article/details/17848219 版权声明:本文为博主原创文章,未经博主允许不得转载. 最近完成了www.leetco ...
- Spring Boot学习——统一异常处理
本随笔记录使用Spring Boot统一处理异常. 本文实例是从数据库中根据ID查询学生信息,要求学生的年龄在14——20岁之间.小于14岁,提示“你可能在上初中”:大于20岁,提示“呢可能在上大学” ...
- sublime 中设置pylint
http://www.360doc.com/content/14/1110/11/15077656_424004081.shtml 安装 pylinter 插件 详见 sublime 插件安装 配 ...
- poj 2892(二分+树状数组)
Tunnel Warfare Time Limit: 1000MS Memory Limit: 131072K Total Submissions: 7749 Accepted: 3195 D ...
- MVC 二级联动 可以试试
后台代码,获取数据如下: /// <summary> 2 /// 获取省份 3 /// </summary> 4 public JsonResult GetProvinceli ...
- 给定n个数字,问能否使这些数字相加得到h【折半查找/DFS】
A Math game Time Limit: 2000/1000MS (Java/Others) Memory Limit: 256000/128000KB (Java/Others) Submit ...