hr员工数据分析(实战)
hr员工数据分析项目实战
(数据已脱敏)
背景说明
某公司最近公司发生多起重要员工意外离职、部分员工工作缺乏积极性等问题,受hr部门委托,开展数据分析工作。
经与hr部门沟通,确定以下需求:
制定数据仪表盘实时监控人员变动情况(比如能预知员工离职节点),制作员工画像。
原始数据说明:
共两个sql数据,“hr数据”、“员工满意度及绩效考核数据”。其中hr数据中,转过岗的员工有转岗前和转岗后的两条数据;“员工满意度及绩效考核数据”中有测试数据ID为负,职务序列为管理的员工没有满意度数据。
项目实施:
1.数据获取&数据集制作
原始数据情况介绍:原始数据为两个sql文件,“员工绩效及满意度数据”、“hr数据”。而且根据业务方的介绍“员工绩效及满意度数据”中存在ID为负值的测试数据,“hr数据”中转过岗位(从其他岗位转管理的员工有两条记录。这里首先需要将数据导入mysql workbench对其进行清洗和转换。
基于数据介绍可知,需要对转过岗的人保留新岗位记录(删除转岗之前的数据),并新加一列标注每位员工是否转过岗
# 第一步 转过岗的人只保留新岗位记录
# MySql运行在safe-updates模式下,该模式会导致非主键条件下无法执行update或者delete命令,
# 执行命令SET SQL_SAFE_UPDATES = 0
DELETE FROM `hr数据`
WHERE `ID` IN (
SELECT a.`ID`
from(
SELECT `ID`
FROM `hr数据`
GROUP BY `ID`
HAVING COUNT(`ID`) > 1
)AS a
) AND `职务序列` != '管理'; # 第二步 新加一列标注每位员工是否转过岗
SELECT
*,
CASE
WHEN `ID` IN (
SELECT`ID`
FROM`hr数据`
GROUP BY `ID`
HAVING COUNT(`ID`) > 1
) AND `职务序列` = '管理' THEN 1
ELSE 0
END AS `是否转岗过`
FROM `hr数据` # 第三步 表格合并+只导出id为正值的数据 SELECT
a.*,
b.`员工满意度`,
b.`最后一次绩效评估`
FROM
`hr数据` AS a
LEFT JOIN `员工绩效及满意度数据` AS b
ON a.`ID` = b.`ID`
WHERE b.`ID`>0;
# 将以上结果以csv文件导出
得到的csv文件(样例)如下:

2 R语言读取数据
2.1处理缺失值
setwd("D:/R/practise/biysheji/三节课_结课设计")
hr_data <- read.csv("aikeseng_hr_data.csv",header = T,stringsAsFactors = F)
#summary(hr_data)
# 发现变量员工满意度有缺失值,需要处理
hr_data$员工满意度[is.na(hr_data$员工满意度)] <- mean(hr_data$员工满意度,na.rm=T) #这里用简单的缺失值办法 将该变量均值,填充缺失值
summary(hr_data)
head(hr_data$离职)
通过四分位数来看补全的缺失值与其他数差异不大,基本可用。
3 对数据做进一步清理
3.1 转换数据类型
将数据集里的与分类有关的变量改为因子型
new_data <- hr_data
new_data$离职 <- factor(new_data$离职)
new_data$过去5年是否有升职 <- factor(new_data$过去5年是否有升职)
new_data$职务序列 <- factor(new_data$职务序列)
new_data$薪资水平 <- factor(new_data$薪资水平)
summary(new_data)
3.2创建新的特征变量
创建特征变量1:平均每天工作时间,依据劳动法计算每月平均上班时间为21.75天
```{R}
new_data <- transform(new_data,平均日工作时间= new_data$平均每月工作小时/21.75)
```
创建特征变量2:排序,员工满意度、最后一次绩效评估、平均每日工作时间等皆可排序。
员工满意度排名
```{R}
library(dplyr) # 加载数据处理专用包dplyr
new_data <- new_data %>%
mutate('员工满意度排名'=rank(desc(new_data$员工满意度))) %>%
as.data.frame
head(new_data)
```
最后一次绩效评估排名
```{R}
new_data <- new_data %>%
mutate('最后一次绩效评估排名'=rank(desc(new_data$最后一次绩效评估))) %>%
as.data.frame
head(new_data)
```
平均每日工作时间排名
```{R}
new_data <- new_data %>%
mutate('平均日工作时间排名'=rank(desc(new_data$平均日工作时间))) %>%
as.data.frame
head(new_data)
```
4 数据探索
4.1 公司不同职务人员流失情况
```{R}
library(ggplot2)
ggplot(new_data,aes(x=职务序列,fill=离职))+
geom_bar(position = "dodge")+
scale_fill_manual(values=c("#58FA82","#FF0000"))+
xlab("公司各岗位人员流失情况")
```
4.2 员工满意度分布情况
```{R}
ggplot(new_data,aes(x=员工满意度))+
geom_histogram()+
xlab("员工满意度分布密度图")
ggplot(new_data,aes(x=员工满意度,colour=职务序列))+
geom_density()
quantile(new_data$员工满意度)
mean(new_data$员工满意度)
ggplot(new_data,aes(x=职务序列,y=员工满意度))+
geom_boxplot()+
xlab("各部门员工满意度分布")
```
根据上述结果,员工满意度平均分为0.612分,中值为0.62,根据直方图可见大部分员工满意分在0.5分以上;根据密度图,不同职务打分接近,管理类员工满意度成正态分布与补充的平均值有关;根据各部门员工满意度分布图,财务部门平均分略低于其他部门,进一步的情况待后续观察。
4.4最后一次绩效评估分布
```{R}
ggplot(new_data,aes(x=最后一次绩效评估))+
geom_histogram()+
xlab("员工最后一次绩效评估分布图")
```
从整体看最后一次绩效评估分数集中在0.5分以上。
4.5 不同工作年限员工流失情况
```{R}
ggplot(new_data,aes(x=在公司工作年限,fill=离职))+
geom_bar(position = "dodge")+
scale_fill_manual(values=c("#58FA82","#FF0000"))+
xlab("公司不同工作年限员工离职情况")
```
根据上述条形图,可见工作2——5年的员工离职率相对较高,尤其是工作4年和工作三年的员工。而工作6年及以上的员工比较稳定。
5.员工画像分析
mydata <- read.csv(file="D:/R/practise/biysheji/三节课_结课设计/aikeseng_hr_data.csv")
mydata$薪资水平 <- as.integer(factor(mydata$薪资水平,levels=c('low','medium','high'),ordered=TRUE))
mydata$员工满意度[is.na(mydata$员工满意度)] <- mean(mydata$员工满意度,na.rm=T)
# 确定聚类数量(K=?)
cost.df <- data.frame()
for(k in 1:10){
kmeans.fit <- kmeans(x=scale(mydata[,c("过去5年是否有升职","薪资水平","在公司工作年限","工作事故","员工满意度")]),centers=k)
cost.df <- rbind(cost.df,cbind(k,kmeans.fit$tot.withinss))
}
names(cost.df) <- c("k","d2")
# 画图
ggplot(cost.df,aes(k,d2)) +
geom_point()+
xlab("聚类数目")+
ylab("到聚类中心的距离平方和(cost)") # 运行k—means模型
set.seed(10) # 确定随机数生成函数的初始数
kmeans_cluster <- kmeans(scale(mydata[,c("薪资水平","在公司工作年限","员工满意度","过去5年是否有升职","工作事故")]),5)
mydata$新标签 <- as.factor(kmeans_cluster$cluster)
# 画图
library(ggplot2)
ggplot(mydata,aes(薪资水平,在公司工作年限,员工满意度,过去5年是否有升职,工作事故,color=新标签)) + geom_point()
ggplot(mydata,aes(在公司工作年限,员工满意度,过去5年是否有升职,工作事故,薪资水平,color=新标签)) + geom_point()
ggplot(mydata,aes(员工满意度,过去5年是否有升职,工作事故,薪资水平,在公司工作年限,color=新标签)) + geom_point()
ggplot(mydata,aes(过去5年是否有升职,工作事故,薪资水平,在公司工作年限,员工满意度,color=新标签)) + geom_point()
ggplot(mydata,aes(工作事故,薪资水平,在公司工作年限,员工满意度,过去5年是否有升职,color=新标签)) + geom_point()
#ggplot(mydata,aes(员工满意度,薪资水平,在公司工作年限,color=新标签)) + geom_point()
#library(ggpairs)
#ggpairs(mydata[,c("薪资水平","在公司工作年限","员工满意度")], aes(colour = mydata$新标签, alpha = 0.4)) # 计算每个聚类下的员工数量、平均工作年限、员工平均满意度、平均工作事故、平均薪资
library(dplyr)
mydata %>%
group_by(新标签)%>%
dplyr::summarise(员工数量=length(ID),平均工作年限=mean(在公司工作年限),员工平均满意度=mean(员工满意度),平均工作事故=mean(工作事故),平均薪资=mean(薪资水平))

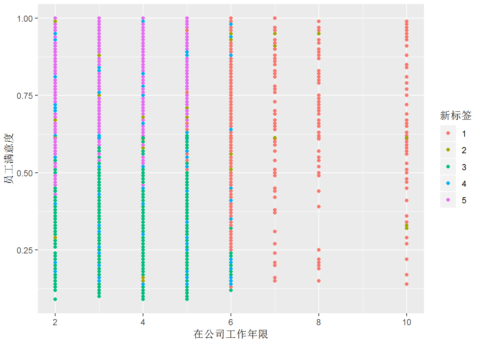
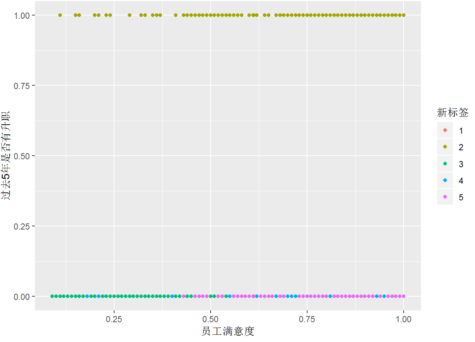

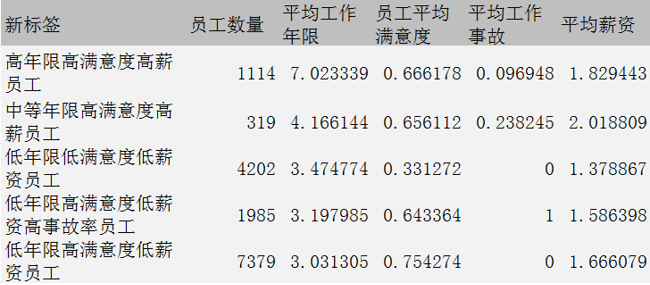
根据聚类结果可以将全部员工分成五大类:
高年限高满意度高薪员工 ;
中等年限高满意度高薪员工 ;
低年限低满意度低薪资员工;
低年限高满意度低薪资高事故率员工;
低年限高满意度低薪资员工
根据聚类结果发现以下问题:
第四类员工群体,即低工龄低薪员工 工作失误率高,这部分员工占总数的1/7,
值得我们关注, 建议增加这部分员工的培训,优化薪资待遇及奖惩措施。
实时监控系统——power bi仪表盘
https://app.powerbi.com/view?r=eyJrIjoiNDJiZjJhNTctOWZjZi00MmQ2LWI1OGYtMzk5OTM4NDM3YTVkIiwidCI6ImE0NmQwMTZhLTA1NTQtNGE0Yy05OTM5LTgxMWQwM2U0Yzk1YyIsImMiOjEwfQ%3D%3D
hr员工数据分析(实战)的更多相关文章
- Python数据分析实战
Python数据分析实战(高清版)PDF 百度网盘 链接:https://pan.baidu.com/s/1nlHM1IW8MYg3z79TUwIsWg 提取码:ux8t 复制这段内容后打开百度网盘手 ...
- Python数据分析实战视频教程【小蚊子数据分析实战课程】
点击了解更多Python课程>>> Python数据分析实战视频教程[小蚊子数据分析实战课程] [课程概述] Python数据分析实战' 适用人群:适合需提升竞争力.提升工作效率.喜 ...
- 【python数据分析实战】电影票房数据分析(一)数据采集
目录 1.获取url 2.开始采集 3.存入mysql 本文是爬虫及可视化的练习项目,目标是爬取猫眼票房的全部数据并做可视化分析. 1.获取url 我们先打开猫眼票房http://piaofang.m ...
- 【python数据分析实战】电影票房数据分析(二)数据可视化
目录 图1 每年的月票房走势图 图2 年票房总值.上映影片总数及观影人次 图3 单片总票房及日均票房 图4 单片票房及上映月份关系图 在上一部分<[python数据分析实战]电影票房数据分析(一 ...
- 《MySQL数据分析实战》八句箴言前四句解析
大家好,我是jacky朱元禄,很高兴继续跟大家学习<MySQL数据分析实战>,从本节课程开始,jacky将从SQL语句入手,给大家解析八句箴言: 不管三七二十一,先把数据show来看: 数 ...
- MySQL数据分析实战-朱元禄-专题视频课程
MySQL数据分析实战-496人已学习 课程介绍 本套课程由知名数据分析博主jacky老师录制,深入浅出讲解MySQL数据分析,从实战角度出发,帮助大家制胜职场!课程收益 1.学会 ...
- 《数据分析实战:基于EXCEL和SPSS系列工具的实践》一1.4 数据分析的流程
本节书摘来华章计算机<数据分析实战:基于EXCEL和SPSS系列工具的实践>一书中的第1章 ,第1.4节,纪贺元 著 更多章节内容可以访问云栖社区"华章计算机"公众号查 ...
- 万字长文,Python数据分析实战,使用Pandas进行数据分析
文章目录 很多人学习python,不知道从何学起.很多人学习python,掌握了基本语法过后,不知道在哪里寻找案例上手.很多已经做案例的人,却不知道如何去学习更加高深的知识.那么针对这三类人,我给大家 ...
- Python数据分析实战-Boston Public Schools GEO数据分析-Part1
项目目标: Boston Public Schools Geo数据是来自于Boston地区的公共学校的数据,具体描述了学校的坐标,名字,类型等.基于此数据,我们可以学习一些基本的Python数据分析的 ...
随机推荐
- Web防止button按钮点击多次
BtnPass.Attributes.Add("onclick", "javascript:if(document.getElementById('IsSubmited' ...
- 约数定理(two)
筛约数个数和 理论基础: 1.对n质因数分解,n=p1^k1 * p2^k2 * p3^k3 …… 则n的约数个数为(k1+1)*(k2+1)*(k3+1)…… 2.线性筛素数时,用i和素数pj来筛掉 ...
- 【bzoj1096】[ZJOI2007]仓库建设
*题目描述: L公司有N个工厂,由高到底分布在一座山上.如图所示,工厂1在山顶,工厂N在山脚.由于这座山处于高原内陆地区(干燥少雨),L公司一般把产品直接堆放在露天,以节省费用.突然有一天,L公司的总 ...
- clientX、pageX、offsetX、screenX的区别
这几个属性的区别说难不难,可是很容易搞混,很长一段时间没用,发现又忘记区别了,记不清哪个是哪个!真的很抓狂! 区别: clientX.clientY: 相对于浏览器窗口可视区域的X,Y坐标(窗口坐标) ...
- mac 外接屏幕切换操作
mac 屏幕小,可外接合适的屏幕扩展.接好屏幕后: 在 mac 系统变化中看到显示器字样, 点击排列,可以看到一个白色的条状色块,即为主屏幕.(镜像显示不能选中) 在 mac 怎么打开一个应用,在其中 ...
- APIO2019解题报告
「APIO 2019」奇怪装置 题目描述 有无限个二元组,每个二元组为\(((t+\left\lfloor\frac{t}{B} \right\rfloor)\%A,t \% B)\),给出一些区间, ...
- es的脑裂
一个正常es集群中只有一个主节点,主节点负责管理整个集群,集群的所有节点都会选择同一个节点作为主节点:所以无论访问那个节点都可以查看集群的状态信息. 而脑裂问题的出现就是因为从节点在选择主节点上出现分 ...
- C++新旧类型转换小记
旧式类型转换可应对一切转换,不管合不合理,有没有风险,你让我转我就转给你,后果自负. 新式类型转换比较安全,主要体现在父子类之间的运行时转换 dynamic_cast上,若转换失败则返回空指针,而旧式 ...
- Tarjan算法整理
众所周知,tarjan是个非常nb的人,他发明了很多nb的算法,tarjan算法就是其中一个,它常用于求解强连通分量,割点和桥等.虽然具体实现的细节不太一样,但是大体思路是差不多的.先来说一下大体思路 ...
- 疑难杂症——bash: /dev/null: Permission denied
描述 在使用 Devstack 的时候需要时常切换用户su stack,此时会触发错误: root@mickeyfan-dev:~# su stack bash: /dev/null: Permiss ...