大数据笔记(二十八)——执行Spark任务、开发Spark WordCount程序
一、执行Spark任务: 客户端
1、Spark Submit工具:提交Spark的任务(jar文件)
(*)spark提供的用于提交Spark任务工具
(*)example:/root/training/spark-2.1.0-bin-hadoop2.7/examples/jars/spark-examples_2.11-2.1.0.jar
(*)SparkPi.scala 例子:蒙特卡罗求PI
bin/spark-submit --master spark://bigdata11:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 100
Pi is roughly 3.1419547141954713
bin/spark-submit --master spark://bigdata11:7077 --class org.apache.spark.examples.SparkPi examples/jars/spark-examples_2.11-2.1.0.jar 300
Pi is roughly 3.141877971395932
2、Spark Shell 工具:交互式命令行工具、作为一个Application运行
两种模式:(1)本地模式
在spark解压目录/bin下执行:./spark-shell
日志:
创建一个文件hellospark.txt
读文件:

(2)集群模式
bin/spark-shell --master spark://bigdata11:7077
日志:
Spark context available as 'sc' (master = spark://bigdata11:7077, app id = app-20180209210815-0002).
对象:Spark context available as 'sc'
Spark session available as 'spark' ---> 在Spark 2.0后,新提供
是一个统一的访问接口:Spark Core、Spark SQL、Spark Streaming
sc.textFile("hdfs://bigdata11:9000/input/data.txt") 通过sc对象读取HDFS的文件
.flatMap(_.split(" ")) 分词操作、压平
.map((_,1)) 每个单词记一次数
.reduceByKey(_+_) 按照key进行reduce,再将value进行累加
.saveAsTextFile("hdfs://bigdata11:9000/output/spark/day0209/wc")
多说一句:
.reduceByKey(_+_)
完整
.reduceByKey((a,b) => a+b)
3、开发WordCount程序
http://spark.apache.org/docs/2.1.0/api/scala/index.html#org.apache.spark.package
(1)Scala版本: 在IDEA中
package mydemo /*
提交
bin/spark-submit --master spark://bigdata11:7077 --class mydemo.MyWordCount /root/temp/MyWordCount.jar hdfs://bigdata11:9000/input/data.txt hdfs://bigdata11:9000/output/spark/day0209/wc1
*/ import org.apache.spark.{SparkConf, SparkContext} //开发一个Scala版本的WordCount
object MyWordCount {
def main(args: Array[String]): Unit = {
//创建一个Config
val conf = new SparkConf().setAppName("MyScalaWordCount") //核心创建SparkContext对象
val sc = new SparkContext(conf) //使用sc对象执行相应的算子(函数)
sc.textFile(args(0))
.flatMap(_.split(" "))
.map((_,1))
.reduceByKey(_+_)
.saveAsTextFile(args(1)) //停止SparkContext对象
sc.stop() }
}
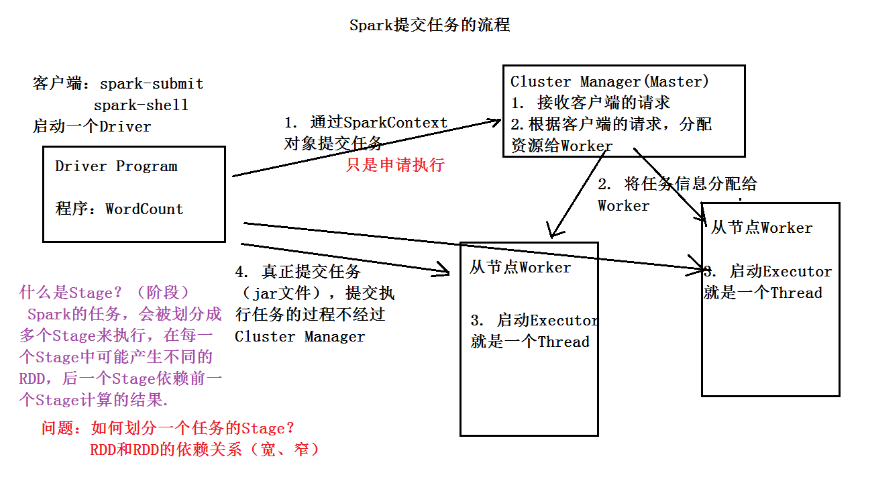
分析WordCount程序执行的过程

Spark 提交任务的流程
大数据笔记(二十八)——执行Spark任务、开发Spark WordCount程序的更多相关文章
- 大数据笔记(十八)——Pig的自定义函数
Pig的自定义函数有三种: 1.自定义过滤函数:相当于where条件 2.自定义运算函数: 3.自定义加载函数:使用load语句加载数据,生成一个bag 默认:一行解析成一个Tuple 需要MR的ja ...
- 大数据笔记(十二)——使用MRUnit进行单元测试
package demo.wc; import java.util.ArrayList; import java.util.List; import org.apache.hadoop.io.IntW ...
- Java基础学习笔记二十八 管家婆综合项目
本项目为JAVA基础综合项目,主要包括: 熟练View层.Service层.Dao层之间的方法相互调用操作.熟练dbutils操作数据库表完成增删改查. 项目功能分析 查询账务 多条件组合查询账务 添 ...
- 大数据笔记(十五)——Hive的体系结构与安装配置、数据模型
一.常见的数据分析引擎 Hive:Hive是一个翻译器,一个基于Hadoop之上的数据仓库,把SQL语句翻译成一个 MapReduce程序.可以看成是Hive到MapReduce的映射器. Hive ...
- 大数据笔记(十)——Shuffle与MapReduce编程案例(A)
一.什么是Shuffle yarn-site.xml文件配置的时候有这个参数:yarn.nodemanage.aux-services:mapreduce_shuffle 因为mapreduce程序运 ...
- angular学习笔记(二十八-附2)-$http,$resource中的promise对象
下面这种promise的用法,我从第一篇$http笔记到$resource笔记中,一直都有用到: HttpREST.factory('cardResource',function($resource) ...
- Java学习笔记二十八:Java中的接口
Java中的接口 一:Java的接口: 接口(英文:Interface),在JAVA编程语言中是一个抽象类型,是抽象方法的集合,接口通常以interface来声明.一个类通过继承接口的方式,从而来继承 ...
- 论文阅读笔记二十八:You Only Look Once: Unified,Real-Time Object Detection(YOLO v1 CVPR2015)
论文源址:https://arxiv.org/abs/1506.02640 tensorflow代码:https://github.com/nilboy/tensorflow-yolo 摘要 该文提出 ...
- 大数据笔记(十九)——数据采集引擎Sqoop和Flume安装测试详解
一.Sqoop数据采集引擎 采集关系型数据库中的数据 用在离线计算的应用中 强调:批量 (1)数据交换引擎: RDBMS <---> Sqoop <---> HDFS.HBas ...
- 大数据笔记(十六)——Hive的客户端及自定义函数
一.Hive的Java客户端 JDBC工具类:JDBCUtils.java package demo.jdbc; import java.sql.DriverManager; import java. ...
随机推荐
- 初步学习jquery学习笔记(五)
jquery学习笔记五 jquery遍历 什么是遍历? 从某个标签开始,按照某种规则移动,直到找到目标标签为止 标签树 <div> <ul> <li> <sp ...
- php文件上传php.ini配置参数
php文件上传服务器端配置参数 file_uploads = On,支持HTTP上传uoload_tmp_dir = ,临时文件保存目录upload_max_filesize = 2M,允许上传文件的 ...
- 一种在获取互斥锁陷入阻塞时可以被中断的 lock
经过上篇的实例 线程在陷入阻塞时,在sychronized获取互斥锁陷入阻塞时,我们是无法进行中断的,javase5中提供了一种解决的办法 ReentrantLock ,我们常常用到的是它的lock( ...
- vim学习(二)之模式
vim模式 基本上 vi/vim 共分为三种模式,分别是命令模式(Command mode),输入模式(Insert mode)和底线命令模式(Last line mode). 命令模式: 用户刚刚启 ...
- jstl用法 简介
<c:choose> <c:when test="${salary <= 0}"> 太惨了. </c:when> <c:when t ...
- 什么是file_sort?如何避免file_sort
阿里巴巴编码规范有这么一例 [推荐]如果有order by场景,请注意利用索引的有序性. order by最后的字段是组合索引的一部分,并且放在索引组合顺序的最后,避免出现file_sort的情况,影 ...
- Centos7安装Python3的方法[转]
Centos7安装Python3的方法 由于centos7原本就安装了Python2,而且这个Python2不能被删除,因为有很多系统命令,比如yum都要用到. [root@VM_105_217_ ...
- 学习-Pytest(三)setup/teardown
1. 用例运行级别 模块级(setup_module/teardown_module)开始于模块始末,全局的 函数级(setup_function/teardown_function)只对函数用例生效 ...
- 四、Signalr手持令牌验证
一.JWT 服务端在respose中设置好cookie,浏览器发请求都会自动带上,不需要做额外设置 但是如果客户端是非浏览器,或者要兼容多种客户端,这个方法就不行了 Js端 @{ Layout = n ...
- git 命令解析
git 补丁 Git 提供了两种补丁方案: (1)用 git diff 生成的UNIX标准补丁.diff文件:.diff文件只是记录文件改变的内容,不带有commit记录信息,多个commit可以 ...