Flink架构和调度
1、Flink架构
Flink系统的架构与Spark类似,是一个基于Master-Slave风格的架构,如下图所示:

Flink集群启动时,会启动一个JobManager进程、至少一个TaskManager进程。在Local模式下,会在同一个JVM内部启动一个JobManager进程和TaskManager进程。当Flink程序提交后,会创建一个Client来进行预处理,并转换为一个并行数据流,这是对应着一个Flink Job,从而可以被JobManager和TaskManager执行。在实现上,Flink基于Actor实现了JobManager和TaskManager,所以JobManager与TaskManager之间的信息交换,都是通过事件的方式来进行处理。
如上图所示,Flink系统主要包含如下3个主要的进程:JobManager、TaskManager、Client
1.1 JobManager
JobManager是Flink系统的协调者,它负责接收Flink Job,调度组成Job的多个Task的执行。同时,JobManager还负责收集Job的状态信息,并管理Flink集群中从节点TaskManager。JobManager所负责的各项管理功能,它接收到并处理的事件主要包括:
1.RegisterTaskManager:
在Flink集群启动的时候,TaskManager会向JobManager注册,如果注册成功,则JobManager会向TaskManager回复消息AcknowledgeRegistration。
2.SubmitJob:
Flink程序内部通过Client向JobManager提交Flink Job,其中在消息SubmitJob中以JobGraph形式描述了Job的基本信息。
3.CancelJob
请求取消一个Flink Job的执行,CancelJob消息中包含了Job的ID,如果成功则返回消息CancellationSuccess,失败则返回消息CancellationFailure。
4.UpdateTaskExecutionState
TaskManager会向JobManager请求更新ExecutionGraph中的ExecutionVertex的状态信息,更新成功则返回true。
5.RequestNextInputSplit
运行在TaskManager上面的Task,请求获取下一个要处理的输入Split,成功则返回NextInputSplit。
6.JobStatusChanged
ExecutionGraph向JobManager发送该消息,用来表示Flink Job的状态发生的变化,例如:RUNNING、CANCELING、FINISHED等。
1.2 TaskManager
TaskManager也是一个Actor,它是实际负责执行计算的Worker,在其上执行Flink Job的一组Task。每个TaskManager负责管理其所在节点上的资源信息,如内存、磁盘、网络,在启动的时候将资源的状态向JobManager汇报。TaskManager端可以分成两个阶段:
1) 注册阶段
TaskManager会向JobManager注册,发送RegisterTaskManager消息,等待JobManager返回AcknowledgeRegistration,然后TaskManager就可以进行初始化过程。
2) 可操作阶段
该阶段TaskManager可以接收并处理与Task有关的消息,如SubmitTask、CancelTask、FailTask。如果TaskManager无法连接到JobManager,这是TaskManager就失去了与JobManager的联系,会自动进入“注册阶段”,只有完成注册才能继续处理Task相关的消息。
1.3 Client
当用户提交一个Flink程序时,会首先创建一个Client,该Client首先会对用户提交的Flink程序进行预处理,并提交到Flink集群中处理,所以Client需要从用户提交的Flink程序配置中获取JobManager的地址,并建立到JobManager的连接,将Flink Job提交给JobManager。Client会将用户提交的Flink程序组装一个JobGraph, 并且是以JobGraph的形式提交的。一个JobGraph是一个Flink Dataflow,它由多个JobVertex组成的DAG。其中,一个JobGraph包含了一个Flink程序的如下信息:JobID、Job名称、配置信息、一组JobVertex等。
2、Flink调度
2.1 逻辑调度
在JobManager端,会接收到Client提交的JobGraph形式的Flink Job,JobManager会将一个JobGraph转换映射为一个ExecutionGraph,如下图所示:
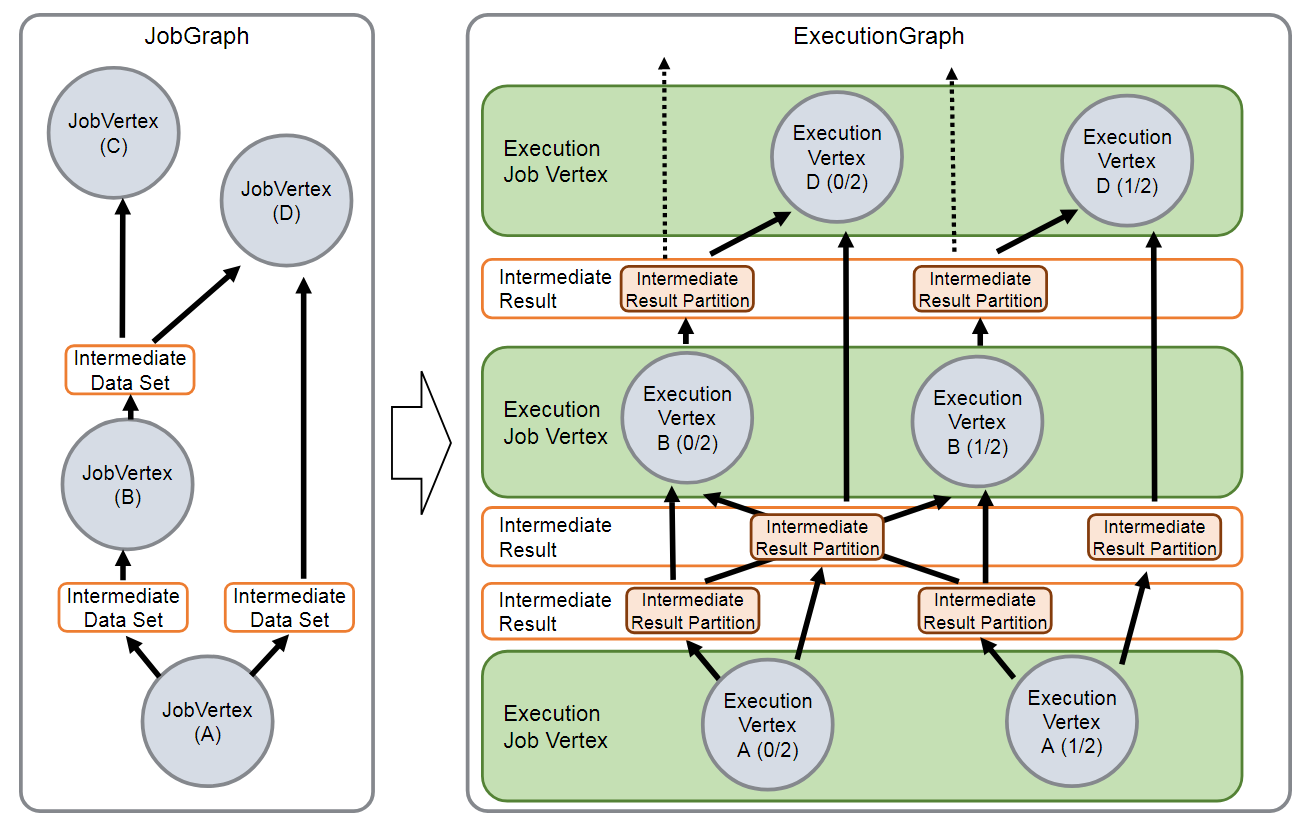
通过上图可以看出:JobGraph是一个Job的用户逻辑视图表示,将一个用户要对数据流进行的处理表示为单个DAG图(对应于JobGraph),DAG图由顶点(JobVertex)和中间结果集(IntermediateDataSet)组成,其中JobVertex表示了对数据流进行的转换操作,比如map、flatMap、filter、keyBy等操作,而IntermediateDataSet是由上游的JobVertex所生成,同时作为下游的JobVertex的输入。
而ExecutionGraph是JobGraph的并行表示,也就是实际JobManager调度一个Job在TaskManager上运行的逻辑视图,它也是一个DAG图,是由ExecutionJobVertex、IntermediateResult(或IntermediateResultPartition)组成,ExecutionJobVertex实际对应于JobGraph图中的JobVertex,只不过在ExecutionJobVertex内部是一种并行表示,由多个并行的ExecutionVertex所组成。另外,这里还有一个重要的概念,就是Execution,它是一个ExecutionVertex的一次运行Attempt,也就是说,一个ExecutionVertex可能对应多个运行状态的Execution,比如,一个ExecutionVertex运行产生了一个失败的Execution,然后还会创建一个新的Execution来运行,这时就对应这个2次运行Attempt。每个Execution通过ExecutionAttemptID来唯一标识,在TaskManager和JobManager之间进行Task状态的交换都是通过ExecutionAttemptID来实现的。
2.2 物理调度

1.左上子图:有2个TaskManager,每个TaskManager有3个Task Slot
左下子图:一个Flink Job,逻辑上包含了1个data source、1个MapFunction、1个ReduceFunction,对应一个JobGraph
2.左下子图:用户提交的Flink Job对各个Operator进行的配置——data source的并行度设置为4,MapFunction的并行度也为4,ReduceFunction的并行度为3,JobManager端对应于ExecutionGraph
3.右上子图:TaskManager 1上,有2个并行的ExecutionVertex组成的DAG图,它们各占用一个Task Slot
4.右下子图:TaskManager 2上,也有2个并行的ExecutionVertex组成的DAG图,它们也各占用一个Task Slot在2个TaskManager上运行的4个Execution是并行执行的
Flink架构和调度的更多相关文章
- flink架构介绍
前言 flink作为基于流的大数据计算引擎,可以说在大数据领域的红人,下面对flink-1.7的架构进行逻辑上的分析并和spark做了一些关键点的对比. 架构 如图1,flink架构分为3个部分,cl ...
- Flink入门(二)——Flink架构介绍
1.基本组件栈 了解Spark的朋友会发现Flink的架构和Spark是非常类似的,在整个软件架构体系中,同样遵循着分层的架构设计理念,在降低系统耦合度的同时,也为上层用户构建Flink应用提供了丰富 ...
- Flink架构,源码及debug
序 工作中用Flink做批量和流式处理有段时间了,感觉只看Flink文档是对Flink ProgramRuntime的细节描述不是很多, 程序员还是看代码最简单和有效.所以想写点东西,记录一下,如果能 ...
- 3、flink架构,资源和资源组
一.flink架构 1.1.集群模型和角色 如上图所示:当 Flink 集群启动后,首先会启动一个 JobManger 和一个或多个的 TaskManager.由 Client 提交任务给 JobMa ...
- Flink架构分析之Standalone模式启动流程
概述 FLIP6 对Flink架构进行了改进,引入了Dispatcher组件集成了所有任务共享的一些组件:SubmittedJobGraphStore,LibraryCacheManager等,为了保 ...
- Flink架构、原理与部署测试
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Flink架构、原理与部署测试(转)
Apache Flink是一个面向分布式数据流处理和批量数据处理的开源计算平台,它能够基于同一个Flink运行时,提供支持流处理和批处理两种类型应用的功能. 现有的开源计算方案,会把流处理和批处理作为 ...
- Flink架构分析之资源分配
Task Slot Flink中每个真正执行任务的TaskManager都是一个JVM进程,其在多线程环境中执行一个或者多个子任务.为了控制一个JVM同时能运行的任务数量,flink引入了ta ...
- Flink架构(五)- 检查点,保存点,与状态恢复
检查点,保存点,与状态恢复 Flink是一个分布式数据处理系统,这种场景下,它需要处理各种异常,例如进程终止.机器故障.网络中断等.因为tasks在本地维护它们的state,Flink必须确保在出现故 ...
随机推荐
- 万兴神剪手 Wondershare Filmora v9.2.11.6 简体中文版
目录 1. 介绍 2. 简体中文9.2.1.10汉化版下载 3. 安装和激活说明 1. 介绍 万兴神剪手 Filmora 是一款界面简洁时尚.功能强大的视频编辑软件,它是深圳万兴科技公司近年来的代表作 ...
- PyCharm专业版下载安装
目录 1. 推荐阅读 2. PyCharm专业版 (目录) 1. 推荐阅读 Python基础入门一文通 | Python2 与Python3及VSCode下载和安装.PyCharm安装.Python在 ...
- 2.SpringBoot整合Mybatis(一对一)
前言: 上一篇整合springboot和mybatis的项目的建立,以及单表的简单的增删改查.这里是上一篇blog的地址:https://www.cnblogs.com/wx60079/p/11461 ...
- 018-zabbix_api
Zabbix API 简介 Zabbix API 开始扮演着越来越重要的角色,尤其是在集成第三方软件和自动化日常任务时. 很难想象管理数千台服务器而没有自动化是多么的困难. Zabbix API 为批 ...
- java面试02——基础
1. JDK . JRE 和JVM有什么区别? JDK:Java Development Kit 的简称,Java 开发工具包,提供了 Java 的开发环境和运行环境. JRE:Java Runtim ...
- Linux日常之命令sed
一. 命令sed简介 利用命令sed能够同时处理多个文件多行的内容,可以不对原文件改动,仅把匹配的内容显示在屏幕上,也可以对原文件进行改动,但是不会在屏幕上返回结果,若想查看改动后的文件,可以使用命令 ...
- mysql如何查询一个字段在哪几张表中
SELECT TABLE_SCHEMA,TABLE_NAME FROM information_schema.`COLUMNS` WHERE COLUMN_NAME = 'xxx' ; xxx替换成需 ...
- linux上开启和分析mysql慢查询日志
本人qq群也有许多的技术文档,希望可以为你提供一些帮助(非技术的勿加). QQ群: 281442983 (点击链接加入群:http://jq.qq.com/?_wv=1027&k=29Lo ...
- java数据结构--array与ArrayList的区别
ArrayList 内部是由一个array 实现的. 如果你知道array 和 ArrayList 的相似点和不同点,就可以选择什么时候用array 或者使用ArrayList , array 提供 ...
- Redis实战(十七)Redis各个版本新特性
序言 Redis1.0 Redis2.0 Redis3.0 Redis4.0 Redis5.0 资料