利用 Skywalking 搭建 APM(应用性能管理)— 安装与配置
1.什么是 Skywalking
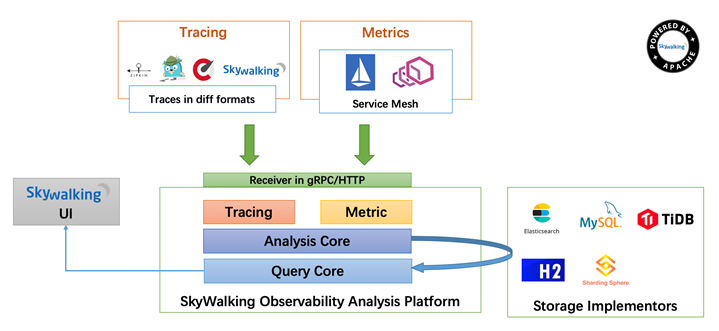
Skywalking 是一个APM系统,即应用性能监控系统,为微服务架构和云原生架构系统设计。它通过探针自动收集所需的指标,并进行分布式追踪。通过这些调用链路以及指标,Skywalking APM会感知应用间关系和服务间关系,并进行相应的指标统计。目前支持链路追踪和监控应用组件如下,基本涵盖主流框架和容器,如国产PRC Dubbo和motan等,国际化的spring boot,spring cloud都支持了
skywalaking 分为三部分:
- skywalking-collector:链路数据归集器,数据可以落地 Elasticsearch,单机也可以落地H2,不推荐,H2仅作为临时演示用
- skywalking-web:web可视化平台,用来展示落地的数据
- skywalking-agent:探针,用来收集和发送数据到归集器
3.Skywalking 的版本选择
Skywalking 目前的支持版本有 5.0.0-GA 、6.0.0-GA 和 6.1.0 版本,各个版本支持的 Elasticsearch 版本不同,对应的版本如下:
|
Skywalking 版本 |
JDK 版本 |
Elasticsearch 版本 |
下载地址 |
|
5.0.0-GA |
jdk8+ |
5.x |
|
|
6.0.0-GA |
jdk8+ |
6.x |
|
|
6.1.0 |
jdk8+ |
6.x |
如果下载地址无效,可以到 Skywalking 的官网地址下载,http://skywalking.apache.org/
4.Skywalking 的下载安装
由于我本地系统是 Centos 7 ,本地环境安装的 Elasticsearch 是 6.7.2 版本,因此我可以选择 6.0.0-GA 或 6.1.0 版本,我这里选择的是 6.1.0 版本,下载 Skywalking 很简单,只需要执行 wget 命令,如下:
$> wget http://mirror.bit.edu.cn/apache/skywalking/6.1.0/apache-skywalking-apm-6.1.0.tar.gz
下载完成后,我们进行解压到 /opt 目录下
$> tar -xvf apache-skywalking-apm-6.1.0.tar.gz -C /opt
解压完成后,接下来需要进行 Skywalking 的相关配置
4.1 Skywalking collector 配置
collector 链路数据归集器,主要用于数据落地,我这里需要配置落地数据为 Elasticsearch 6.7.2,collector 配置文件为 /opt/apache-skywalking-apm-6.1.0/config/application.yml,配置单点的 collector 配置如下:
cluster:
standalone:
core:
default:
# Mixed: Receive agent data, Level 1 aggregate, Level 2 aggregate
# Receiver: Receive agent data, Level 1 aggregate
# Aggregator: Level 2 aggregate
role: ${SW_CORE_ROLE:Mixed} # Mixed/Receiver/Aggregator
# rest 服务地址和端口
restHost: ${SW_CORE_REST_HOST:localhost}
restPort: ${SW_CORE_REST_PORT:12800}
restContextPath: ${SW_CORE_REST_CONTEXT_PATH:/}
# gRPC 服务地址和端口
gRPCHost: ${SW_CORE_GRPC_HOST:localhost}
gRPCPort: ${SW_CORE_GRPC_PORT:11800}
downsampling:
- Hour
- Day
- Month
# 设置度量数据的超时。超时过期后,度量数据将自动删除.
# 单位分钟
recordDataTTL: ${SW_CORE_RECORD_DATA_TTL:90}
# 单位分钟
minuteMetricsDataTTL: ${SW_CORE_MINUTE_METRIC_DATA_TTL:90}
# 单位小时
hourMetricsDataTTL: ${SW_CORE_HOUR_METRIC_DATA_TTL:36}
# 单位天
dayMetricsDataTTL: ${SW_CORE_DAY_METRIC_DATA_TTL:45}
# 单位月
monthMetricsDataTTL: ${SW_CORE_MONTH_METRIC_DATA_TTL:18}
storage:
elasticsearch:
# elasticsearch 的集群名称
nameSpace: ${SW_NAMESPACE:"local-ES"}
# elasticsearch 集群节点的地址及端口
clusterNodes: ${SW_STORAGE_ES_CLUSTER_NODES:192.168.2.10:9200}
# elasticsearch 的用户名和密码
user: ${SW_ES_USER:""}
password: ${SW_ES_PASSWORD:""}
# 设置 elasticsearch 索引分片数量
indexShardsNumber: ${SW_STORAGE_ES_INDEX_SHARDS_NUMBER:2}
# 设置 elasticsearch 索引副本数
indexReplicasNumber: ${SW_STORAGE_ES_INDEX_REPLICAS_NUMBER:0}
# 批量处理配置
个请求执行一次批量
bulkActions: ${SW_STORAGE_ES_BULK_ACTIONS:2000}
# 每 20mb 刷新一次内存块
bulkSize: ${SW_STORAGE_ES_BULK_SIZE:20}
秒刷新一次堆
flushInterval: ${SW_STORAGE_ES_FLUSH_INTERVAL:10}
# 并发请求的数量
concurrentRequests: ${SW_STORAGE_ES_CONCURRENT_REQUESTS:2}
# elasticsearch 查询的最大数量
metadataQueryMaxSize: ${SW_STORAGE_ES_QUERY_MAX_SIZE:5000}
# elasticsearch 查询段最大数量
segmentQueryMaxSize: ${SW_STORAGE_ES_QUERY_SEGMENT_SIZE:200}
4.2 Skywalking webApp 配置
Skywalking 的 WebApp 主要是用来展示落地的数据,因此只需要配置 Web 的端口及获取数据的 collector 的IP和端口,webApp 配置文件地址为 /opt/apache-skywalking-apm-6.1.0/webapp/webapp.yml 配置如下:
server:
collector:
path: /graphql
ribbon:
# 指向所有后端collector 的 restHost:restPort 配置,多个使用 , 分隔
listOfServers: localhost:12800
security:
user:
# username
admin:
# password
password: admin
4.3 Skywalking Agent 配置
Skywalking 的 Agent 主要用于收集和发送数据到 collector ,因此需要进行配置 Skywalking collector 的地址,Agent 的配置文件地址为 /opt/apache-skywalking-apm-6.1.0/agent/config/agent.config,配置如下:
# 设置Agent命名空间
agent.namespace=${SW_AGENT_NAMESPACE:default-namespace}
# 设置服务名称,会在 Skywalking UI 上显示的名称
agent.service_name=${SW_AGENT_NAME:Your_ApplicationName}
# 每 3秒采集的样本跟踪比例,如果是负数则表示 100%采集
agent.sample_n_per_3_secs=${SW_AGENT_SAMPLE:-1}
# 启用 Debug ,如果为 true 则将把所有检测到的类文件保存在"/debug"文件夹中
# agent.is_open_debugging_class = ${SW_AGENT_OPEN_DEBUG:true}
# 后端的 collector 端口及地址
collector.backend_service=${SW_AGENT_COLLECTOR_BACKEND_SERVICES:192.168.2.215:11800}
# 日志级别
logging.level=${SW_LOGGING_LEVEL:DEBUG}
5 示例项目
创建一个 spring boot 项目,增加一个简单的 RestConstroller 控制器,提供一个 rest 服务,代码如下:
@RestController
public class HelloWorldController{
@RequestMapping(path={"/","/index"},produces=MediaType.APPLICATION_JSON_UTF8_VALUE)
public Map<String,Object> index(){
Map<String,Object> map=new LinkedHashMap<>();
map.put("A","a");
map.put("b",newBigDecimal("1.2"));
return map;
}
}
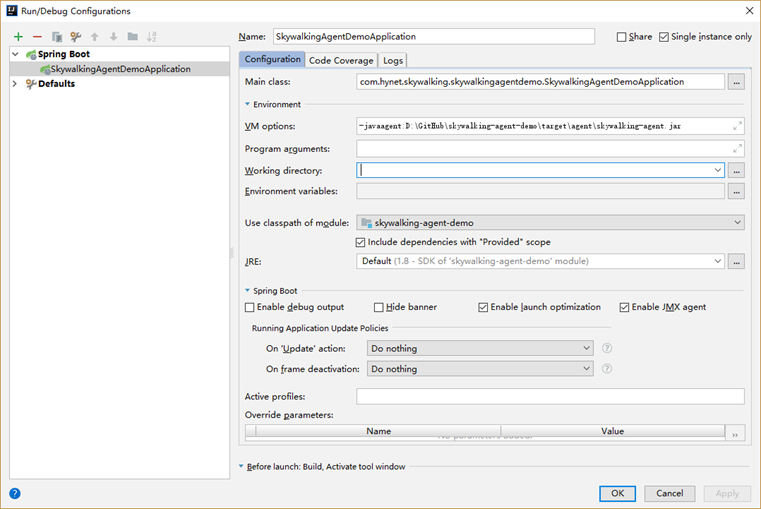
复制 /opt/apache-skywalking-apm-6.1.0/agent 目录到项目的 target 目录中,增加 VM options 参数 -javaagent 并指向到 agent\skywalking-agent.jar ,如下图:
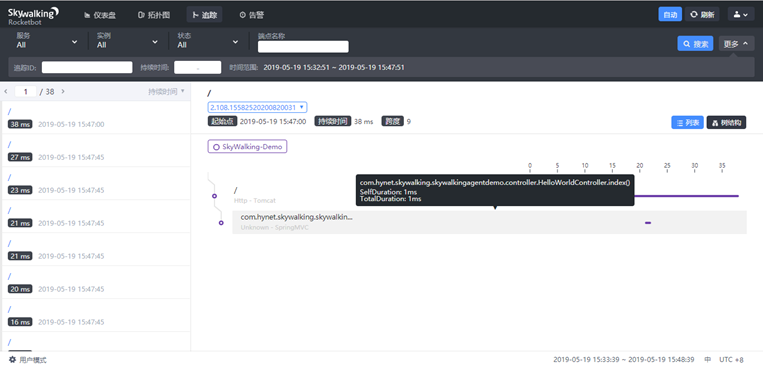
启动项目进行测试,请通过浏览器访问 rest 服务,然后访问 skywalking web 可以查询到刚才的访问。
利用 Skywalking 搭建 APM(应用性能管理)— 安装与配置的更多相关文章
- (九)OpenStack---M版---双节点搭建---Swift(单节点)安装和配置
↓↓↓↓↓↓↓↓视频已上线B站↓↓↓↓↓↓↓↓ >>>>>>传送门 本次搭建仅采用Compute单节点做swift组件 1.Controller安装并配置控制节点 ...
- Linux搭建JDK、Tomcat安装及配置
一.JDK安装及配置 1.JKD下载地址:http://pan.baidu.com/s/1i5NpImx 2.查看安装: rpm -qa | grep jdk 3.卸载:rpm -e --nodeps ...
- 利用SOLR搭建企业搜索平台 之——solr配置solrconfig.xml
来源:http://blog.csdn.net/zx13525079024/article/details/25310781 solrconfig.xml配置文件主要定义了SOLR的一些处理规则,包括 ...
- 利用SOLR搭建企业搜索平台 之——模式配置Schema.xml
来源:http://blog.csdn.net/awj3584/article/details/16963525 schema.xml这个配置文件可以在你下载solr包的安装解压目录的\solr\ex ...
- 1.环境搭建-mysql+tomcat+myeclipse安装并配置
一.安装mysql数据库并配置 下载地址:https://pan.baidu.com/s/1OJ3ggda7Cthl4GCxWKbTng 密码:sd6b 1.打开安装程序
- 利用Hexo搭建个人博客-博客初始化篇
上一篇博文 <利用Hexo搭建个人博客-环境搭建篇> 中,我们讲解了利用Hexo搭建个人博客应该要配置哪些环境.相信大家已经迫不及待的想要知道接下来应该要怎么把自己的博客搭起来了,下面,让 ...
- 在Ubuntu 15下搭建V/P/N服务器pptpd安装和配置
在Ubuntu 15下搭建VPN服务器pptpd安装和配置 在ubuntu下配置vpn的方式有很多种,其中比较常见的是pptpd,它配置简单,但是安全性不高,不过对于一般使用来说足够了,我按照程搭建了 ...
- SkyWalking 搭建及简单使用(Linux)
1.需求 公司项目采用微服务的架构,服务很多,人工监控是不可能的,项目的访问量很大,想通过日志查找某个方法中性能的问题也是非常困难的.但是系统的性能问题是不能忽视的.系统性能检测的问题如鲠在喉,经过长 ...
- Kafka1 利用虚拟机搭建自己的Kafka集群
前言: 上周末自己学习了一下Kafka,参考网上的文章,学习过程中还是比较顺利的,遇到的一些问题最终也都解决了,现在将学习的过程记录与此,供以后自己查阅,如果能帮助到其他人,自然是更好的. ...
随机推荐
- Html mate标签的常见功能
一.常用的功能 1.禁止屏幕缩放 <meta content="width=device-width, initial-scale=1.0, maximum-scale=1.0, us ...
- Eigen的aligned_allocator
今天看ORBSLAM2中的OptimizeEssentialGraph()函数时,对一句代码中的aligned_allocator不太清楚: vector<g2o::Sim3,Eigen::al ...
- [Git] 008 status 与 commit 命令的补充
本文的"剧情"承接 [Git] 007 三棵树以及向本地仓库加入第一个文件 1. 对 "status" 的补充 1.1 "status" 有 ...
- win10创建扩展分区
1.开始菜单中选择命令提示符,以管理员身份运行. 2.运行“diskpart”命令. 3.DISKPART>后面输入list disk命令,显示磁盘列表. 4.选择磁盘,select disk ...
- 1.Dockerfile
1.docker build docker build 这个动作有一个context 上下文的概念 docker build -f /path/to/a/Dockerfile .这个动作 通过 -f ...
- React父子组件间的传值
父组件: import React, { Component } from 'react'; import Child from './chlid'; class parent extends Com ...
- P2517 [HAOI2010]订货(dp)
P2517 [HAOI2010]订货 设$f[i][j]$表示第$i$个月,库存为$j$的最小代价 枚举上个月的库存$k$,那么$f[i][j]=f[i-1][k]+(j+U[i]-k)*D[i]+j ...
- TAB切换与内容伸展闭合的结合
<!doctype html> <html lang="en"> <head> <meta charset="UTF-8&quo ...
- HTML文档流和脱离文档流
文档流:也就是我们通常看到的由左到右.由上而下的元素排列形式,在网页中每个元素都是默认按照这个顺序进行排序和显示的. 脱离文档流:元素脱离文档流之后,将不再在文档流中占据空间,而是处于浮动状态(可以理 ...
- CentOS7搭建Kafka单机环境及基础操作
前提 安装Kafka前需要先安装zookeeper集群,集体安装方法请参照我的另一篇文档. Kafka安装 下载 wget https://archive.apache.org/dist/kafka/ ...