KNN算法之KD树
KD树算法是先对数据集进行建模,然后搜索最近邻,最后一步是预测。
KD树中的K指的是样本特征的维数。
一、KD树的建立
m个样本n维特征,计算n个特征的方差,取方差最大的第k维特征作为根节点。选择第k维特征的中位数作为切分点,小于中位数的放左子树,大于中位数的放右子树,递归生成。

举例
有二维样本6个,{(2,3),(5,4),(9,6),(4,7),(8,1),(7,2)}:
1、找根节点,6个数据点在x、y维度上的方差分别是6.97,5.37,x维度方差最大,因此选择x维进行键树;
2、找切分点,x维中位数是(7,2),因此以这个点的x维度的取值进行划分;
3、x=7将空间分为左右两个部分,然后递归使用此方法,最后结果为:

(7,2)
/ \
(5,4) (9,6)
/ \ /
(2,3)(4,7) (8,1)
二、搜索最近邻
先找到包含目标点的叶子节点,然后以目标点为圆心,目标点到叶子节点距离为半径,得到超球体。最近邻的点一点在内部。
返回叶子节点的父节点,检查另一个叶子节点包含的超矩体是否和这个超球体相交,相交的话在这个叶子节点寻找有没有更近的近邻,更新。当回溯到根节点时,结束。此时保存的节点就是最近邻节点。
KD树划分后可以大大减少无效的最近邻搜索,很多样本点由于所在的超矩形体和超球体不相交,根本不需要计算距离。大大节省了计算时间。
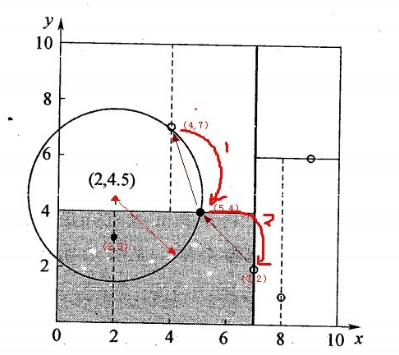
1、对(2,4.5)搜索最近邻,先从(7,2)开始找,2<7因此在左子树;
2、4.5>4,在右子空间找到叶子节点(4,7),计算距离为3.202,以它为半径得到超球体,返回父节点(5,4);
3、计算父节点与(2,4.5)的距离=3.041<3.202,更新保存的最近节点,同时由于左子空间与超球体相交,所以到左子空间中找有没有叶子节点;
4、左子空间中(2,3)节点与目标节点更近,找到最近邻。
三、KD树预测
在kd树搜索最近邻的基础上,选择到了第一个最近邻样本,把它设置为已选,然后第二轮中忽略这个样本,重新找最近邻。
四、球树
kd树对样本分布不均匀时,效果不好。
球树:每个分割快都是超球体。
过程:从球中选择一个离球的中心最远的点,然后选择第二个点离第一个点最远,将所有的点分配到这两个点上,计算聚类中心,然后对这两个小超球体递归使用这个方法
KNN算法之KD树的更多相关文章
- KNN算法与Kd树
最近邻法和k-近邻法 下面图片中只有三种豆,有三个豆是未知的种类,如何判定他们的种类? 提供一种思路,即:未知的豆离哪种豆最近就认为未知豆和该豆是同一种类.由此,我们引出最近邻算法的定义:为了判定未知 ...
- 【分类算法】K近邻(KNN) ——kd树(转载)
K近邻(KNN)的核心算法是kd树,转载如下几个链接: [量化课堂]一只兔子帮你理解 kNN [量化课堂]kd 树算法之思路篇 [量化课堂]kd 树算法之详细篇
- 从K近邻算法谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/v_july_v/article/details/8203674 ,感谢july的辛勤劳动 前言 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章 ...
- <转>从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转自 http://blog.csdn.net/likika2012/article/details/39619687 前两日,在微博上说:“到今天为止,我至少亏欠了3篇文章待写:1.KD树:2.神经 ...
- 从K近邻算法、距离度量谈到KD树、SIFT+BBF算法
转载自:http://blog.csdn.net/v_july_v/article/details/8203674/ 从K近邻算法.距离度量谈到KD树.SIFT+BBF算法 前言 前两日,在微博上说: ...
- KNN 算法-实战篇-如何识别手写数字
公号:码农充电站pro 主页:https://codeshellme.github.io 上篇文章介绍了KNN 算法的原理,今天来介绍如何使用KNN 算法识别手写数字? 1,手写数字数据集 手写数字数 ...
- KD树
k-d树 在计算机科学里,k-d树( k-维树的缩写)是在k维欧几里德空间组织点的数据结构.k-d树可以使用在多种应用场合,如多维键值搜索(例:范围搜寻及最邻近搜索).k-d树是空间二分树(Binar ...
- 【数据结构与算法】k-d tree算法
k-d tree算法 k-d树(k-dimensional树的简称),是一种分割k维数据空间的数据结构.主要应用于多维空间关键数据的搜索(如:范围搜索和最近邻搜索). 应用背景 SIFT算法中做特征点 ...
- 一看就懂的K近邻算法(KNN),K-D树,并实现手写数字识别!
1. 什么是KNN 1.1 KNN的通俗解释 何谓K近邻算法,即K-Nearest Neighbor algorithm,简称KNN算法,单从名字来猜想,可以简单粗暴的认为是:K个最近的邻居,当K=1 ...
随机推荐
- 网络通讯数据.传输json(java<==>C#)
ZC:主要是测试解决 时间转成JSON不一样的问题 ZC:java中转换时间格式的关键是“JSONUtils.getMorpherRegistry().registerMorpher(new Date ...
- 系统用户与用户组管|chfn、密码管理、身份切换、sudo
2 系统用户与用户组管理 GID为GroupId,即组ID,用来标识用户组的唯一标识符 UID为UserId,即用户ID,用来标识每个用户的唯一标示符 /etc/passwd /etc/shadow ...
- MySQL数据库的特点和优势
MySQL数据库的特点和优势: 1.MySQL性能卓越.服务稳定,很少出现异常宕机. 2.MySQL开放源代码且无版权制约,自主性及使用成本低. 3.MySQL历史悠久,用户使用活跃,遇到问题可以寻求 ...
- P1536村村通
这是一个并查集的题,被洛谷评为提高—. 拿到这个题便看出了这是一个裸的并查集,于是就写了一个模板,结果发现连输入都输不进去,一看竟然是多组数据,,然后看到N==0结束,于是便加了一层while.之后提 ...
- 04: DjangoRestFramework使用
Django其他篇 目录: 1.1 DjangoRestFramework基本使用 1.2 drf认证&权限 模块 1.3 djangorestframework 序列化 1.4 django ...
- hive中的索引创建
1.在hive中创建索引所在表 create table if not exists h_odse.hxy(id int,name string,hobby array<string>,a ...
- python递归方式和普通方式实现输出和查询斐波那契数列
●斐波那契数列 斐波那契数列(Fibonacci sequence),是从1,1开始,后面每一项等于前面两项之和. 如果为了方便可以用递归实现,要是为了性能更好就用循环. ◆递归方式实现生成前30个斐 ...
- 第三方模块:gulp模块
一.Gulp的使用 1. 使用npm install gulp 下载gulp库文件 2. 在项目根目录下简历gulpfile.js文件 3. 重构项目的文件夹架构src目录放置源代码文件,dist ...
- 00.AutoMapper 之入门指南(Getting Started Guide)
转载(https://www.jianshu.com/p/29ee5a94c1d9) 入门指南(Getting Started Guide) AutoMapper 是什么? AutoMapper 是一 ...
- Mysql数据库在建表时指定engine等于InnoDB 或MyISAM的意义
一.ISAM和InnoDB的定义 1. ISAM ISAM是一个定义明确且历经时间考验的数据表格管理方法,它在设计之时就考虑到数据库被查询的次数要远大于更新的次数.因此,ISAM执行读取操作的速度很快 ...