Scrapy框架的应用
一, Scrapy
Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架,非常出名,非常强悍。所谓的框架就是一个已经被集成了各种功能(高性能异步下载,队列,分布式,解析,持久化等)的具有很强通用性的项目模板。
- 高性能的网络请求
- 高性能的数据解析
- 高性能的持久化存储
- 深度爬取
- 全栈爬取
- 分布式
- 中间件
- 请求传参
- ...等等
环境的安装:
mac/linux:pip install scrapy
window:
- pip install wheel
- 下载twisted http://www.lfd.uci.edu/~gohlke/pythonlibs/#twisted
- 进入下载目录,执行 pip install Twisted‑17.1.0‑cp37‑cp37m‑win_amd64.whl
- pip install pywin32
- pip install scrapy
二, 基础的使用
新建一个工程:
scrapy startproject ProName- 目录结构:
- spiders(包):空包
- settings:配置文件
- 不遵从robots:
ROBOTSTXT_OBEY = False - UA伪装:
USER_AGENT = 'xxx' - 日志等级的指定:
LOG_LEVEL = 'ERROR'
- 不遵从robots:
- 目录结构:
cd ProName:进入到工程目录中- 在spiders(爬虫文件夹)中创建一个爬虫文件
scrapy genspider spiderName www.xxx.com- 编写代码:主要的代码会编写在爬虫文件中
- 执行工程:
scrapy crawl spiderName
# -*- coding: utf-8 -*-
import scrapy
# 爬虫类: 父类 => Spider
class FirstSpider(scrapy.Spider):
# 爬虫文件的名称: 当前爬虫源文件的唯一标识
name = 'first'
# 允许的域名, 限定爬取的域名
# allowed_domains = ['www.baidu.com']
# 起始的url列表, 列表中存放的url都可以被scrapy进行异步的网络请求
start_urls = ['https://www.baidu.com/', 'https://www.taobao.com/']
# 用作与数据解析
# 参数: response就是响应对象
def parse(self, response):
print(response)
scrapy的数据解析与持久化存储:
需求: 爬取 https://dig.chouti.com/ 的文章标题与作者
extract()与extract_first(): 从xpath查询结果对象(Selector)中取得数据
scrapy的持久化存储
基于终端指令进行持久化存储
只可以将parse方法的返回值存储到本地的磁盘文件(指定形式后缀)中
支持:
json,jsonlines,jl,csv,xml,marshall,picklescrapy crawl spiderName -o filePath# 用作与数据解析
# 参数: response就是响应对象
def parse(self, response):
div_list = response.xpath('/html/body/main/div/div/div[1]/div/div[2]/div[1]/div')
all_data = []
for div in div_list:
# 解析标题和作者信息
# xpath在取标签中存储的文本数据时必须要使用extract(),extract_first()进行字符串的单独提取
title = div.xpath('.//div[@class="link-detail"]/a/text()')[0].extract()
author = div.xpath('.//span[@class="left author-name"]/text()').extract_first()
all_data.append({'title': title, 'author': author})
# 基于终端指令的持久化存储
# scrapy crawl spiderName -o filePath
return all_data
基于管道进行持久化存储(常用)
编码流程:
- 在爬虫文件中进行数据解析
- 在item类中定义相关的属性
- 将解析到的数据存储到一个item类型的对象中
- 将item类型的对象提交给管道
- 管道类的process_item方法负责接收item,接收到后可以对item实现任意形式的持久化存储操作
- 在配置文件中开启管道
- 一个管道类对应一种平台的持久化存储
# settings.py
# 开启管道,注册管道
ITEM_PIPELINES = {
# 300表示优先级,数值越小优先级越高
'firstblood.pipelines.FirstbloodPipeline': 300,
}
# items.py
import scrapy
class FirstbloodItem(scrapy.Item):
# define the fields for your item here like:
# name = scrapy.Field()
# Field类型视为一个万能的数据类型
title = scrapy.Field()
author = scrapy.Field()
# pipelines.py
import pymysql
class FirstbloodPipeline(object):
conn = None
cursor = None
# 重写父类方法,该方法只会在爬虫开始时被执行一次
def open_spider(self, spider):
self.conn = pymysql.Connection(host='127.0.0.1', port=3306, user='root', password='123', db='scrapy',
charset='utf8')
# process_item方法调用后就可以接收爬虫类提交来的item对象
def process_item(self, item, spider):
title = item['title']
author = item['author']
sql = 'insert into chouti values (%s, %s)'
self.cursor = self.conn.cursor()
# 事务处理
try:
self.cursor.execute(sql, [author, title])
self.conn.commit()
except Exception as e:
print(e)
# 回滚事务
self.conn.rollback()
return item # 将item传递给下个管道类
def close_spider(self, spider):
self.cursor.close()
self.conn.close()
# first.py
# -*- coding: utf-8 -*-
import scrapy
from firstblood.items import FirstbloodItem
class FirstSpider(scrapy.Spider):
name = 'first'
start_urls = ['https://dig.chouti.com/']
# 用作与数据解析
# 参数: response就是响应对象
def parse(self, response):
div_list = response.xpath('/html/body/main/div/div/div[1]/div/div[2]/div[1]/div')
for div in div_list:
title = div.xpath('.//div[@class="link-detail"]/a/text()')[0].extract()
author = div.xpath('.//span[@class="left author-name"]/text()').extract_first()
# 实例化一个item类型的对象
item = FirstbloodItem()
# 给item对象的属性赋值
item['title'] = title
item['author'] = author
yield item # 将item提交给管道
三, 图片数据爬取(流数据的爬取)
案例:
爬取http://www.521609.com/daxuexiaohua/的图片
scrapy中封装了一个管道类(ImagesPipeline),基于该管道类,可以实现图片资源的请求和永久化存储
编码流程:
1.在爬虫文件中解析出图片的地址
2.将图片地址封装到item中且提交给管道
import scrapy
from getImg.items import GetimgItem
class ImgSpider(scrapy.Spider):
name = 'Img'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://www.521609.com/daxuemeinv/']
# 定义一个通用的url模板
url = 'http://www.521609.com/daxuemeinv/list8%d.html'
pageNum = 1
def parse(self, response):
li_list = response.xpath('//*[@id="content"]/div[2]/div[2]/ul/li')
for li in li_list:
img_src = 'http://www.521609.com' + li.xpath('./a[1]/img/@src').extract_first()
item = GetimgItem()
item['img_src'] = img_src
yield item
if self.pageNum < 5:
self.pageNum += 1
new_url = self.url % self.pageNum
# 手动发请求,实现深度爬取
yield scrapy.Request(new_url, callback=self.parse)
3.管道文件中自定义一个管道类(继承ImagesPipeline)
4.重写三个方法:
def get_media_requests(self, item, info):
def file_path(self, request, response=None, info=None):
def item_completed(self, results, item, info):
import scrapy
from scrapy.pipelines.images import ImagesPipeline
class GetimgPipeline(ImagesPipeline):
# 该方法是用作与请求发送的
def get_media_requests(self, item, info):
# 对item中的img_src进行请求发送
# 手动进行请求发送
yield scrapy.Request(url=item['img_src'])
# 用于指定文件路径(文件夹 + 文件名称)
def file_path(self, request, response=None, info=None):
# 存到settings中指定的文件夹中
return request.url.split('/')[-1]
# 将当前的item提交给下个管道类
def item_completed(self, results, item, info):
return item
5.在配置文件中开启管道且加上IMAGES_STORE配置
# 自定义文件夹路径
IMAGES_STORE = './imgLibs'
四, POST请求
在scrapy中如何进行手动请求发送?
yield scrapy.Request(url, callback)
在scrapy中如何进行post请求的发送?
# formdata是post提交的数据
yield scrapy.FormRequest(url, callback, formdata={})
如何对起始的url进行post请求的发送?
# 重写父类的start_requests(self)方法
def start_requests(self):
for url in self.start_urls:
yield scrapy.FormRequest(url, callback=self.parse, formdata={})
五, 提升爬取数据的效率
增加并发:
默认scrapy开启的并发线程为32个,可以适当进行增加。在settings配置文件中修改CONCURRENT_REQUESTS = 100值为100,并发设置成了为100。
降低日志级别:
在运行scrapy时,会有大量日志信息的输出,为了减少CPU的使用率。可以设置log输出信息为INFO或者ERROR即可。在配置文件中编写:LOG_LEVEL = ‘ERROR’
禁止cookie:
如果不是真的需要cookie,则在scrapy爬取数据时可以禁止cookie从而减少CPU的使用率,提升爬取效率。在配置文件中编写:COOKIES_ENABLED = False
禁止重试:
对失败的HTTP进行重新请求(重试)会减慢爬取速度,因此可以禁止重试。在配置文件中编写:RETRY_ENABLED = False
减少下载超时:
如果对一个非常慢的链接进行爬取,减少下载超时可以能让卡住的链接快速被放弃,从而提升效率。在配置文件中进行编写:DOWNLOAD_TIMEOUT = 1 超时时间为10s
六, 深度爬取
什么叫深度爬取?
- 爬取的数据没有存在同一张页面中
如何实现请求传参?
Request(url,callback,meta={}):可以将meta字典传递给callback
callback接收item:response.meta
需求:
爬取https://www.4567tv.tv/index.php/vod/show/class/%E5%8A%A8%E4%BD%9C/id/1.html的每一页的电影名称和简介.
import scrapy
from moviePro.items import MovieproItem
class MovieSpider(scrapy.Spider):
name = 'movie'
# allowed_domains = ['www.xxx.com']
start_urls = ['https://www.4567tv.tv/index.php/vod/show/class/%E5%8A%A8%E4%BD%9C/id/1.html']
# 通用url模板
url = 'https://www.4567tv.tv/index.php/vod/show/class/动作/id/1/page/%d.html'
pageNum = 2
# 解析电影名称和详情页的url
def parse(self, response):
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
title = li.xpath('./div/div/h4/a/text()').extract_first()
detail_url = 'https://www.4567tv.tv' + li.xpath('./div/div/h4/a/@href').extract_first()
item = MovieproItem()
item['title'] = title
# 手动请求发送, 将meta字典传递给指定的callback(请求传参)
yield scrapy.Request(detail_url, callback=self.parse_detailxxx, meta={'item': item})
if self.pageNum < 5:
new_url = format(self.url % self.pageNum)
self.pageNum += 1
yield scrapy.Request(new_url, callback=self.parse)
# 解析详情页中的电影简介
def parse_detailxxx(self, response):
item = response.meta['item']
desc = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[2]/text()').extract_first()
item['desc'] = desc
yield item
七, 五大核心组件
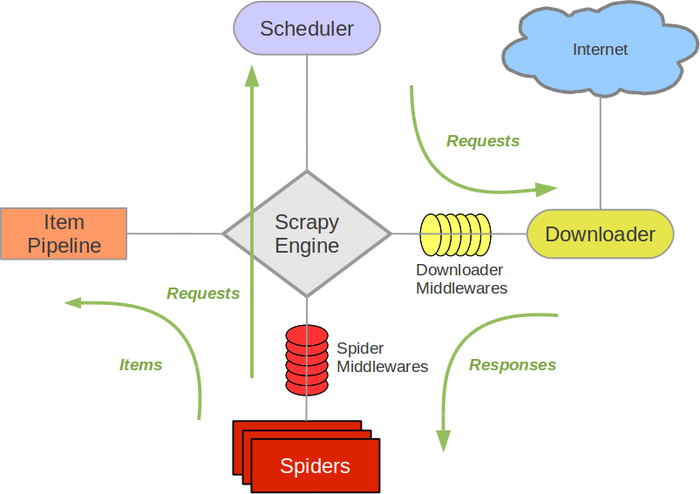
Scrapy Engine(引擎): 负责Spider、ItemPipeline、Downloader、Scheduler中间的通讯,信号、数据传递等。
Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整理排列,入队,当引擎需要时,交还给引擎。
Downloader(下载器):负责下载Scrapy Engine(引擎)发送的所有Requests请求,并将其获取到的Responses交还给Scrapy Engine(引擎),由引擎交给Spider来处理,
Spider(爬虫):它负责处理所有Responses,从中分析提取数据,获取Item字段需要的数据,并将需要跟进的URL提交给引擎,再次进入Scheduler(调度器).
Item Pipeline(管道):它负责处理Spider中获取到的Item,并进行进行后期处理(详细分析、过滤、存储等)的地方。
Downloader Middlewares(下载中间件):你可以当作是一个可以自定义扩展下载功能的组件。 (常用,可以取到request和response)
Spider Middlewares(Spider中间件):你可以理解为是一个可以自定扩展和操作引擎和Spider中间通信的功能组件(比如进入Spider的Responses;和从Spider出去的Requests)
执行流程:
1 引擎:Hi!Spider, 你要处理哪一个网站?
2 Spider:老大要我处理xxxx.com。
3 引擎:你把第一个需要处理的URL给我吧。
4 Spider:给你,第一个URL是xxxxxxx.com。
5 引擎:Hi!调度器,我这有request请求你帮我排序入队一下。
6 调度器:好的,正在处理你等一下。
7 引擎:Hi!调度器,把你处理好的request请求给我。
8 调度器:给你,这是我处理好的request
9 引擎:Hi!下载器,你按照老大的下载中间件的设置帮我下载一下这个request请求
10 下载器:好的!给你,这是下载好的东西。(如果失败:sorry,这个request下载失败了。然后引擎告诉调度器,这个request下载失败了,你记录一下,我们待会儿再下载)
11 引擎:Hi!Spider,这是下载好的东西,并且已经按照老大的下载中间件处理过了,你自己处理一下(注意!这儿responses默认是交给def parse()这个函数处理的)
12 Spider:(处理完毕数据之后对于需要跟进的URL),Hi!引擎,我这里有两个结果,这个是我需要跟进的URL,还有这个是我获取到的Item数据。
13 引擎:Hi !管道 我这儿有个item你帮我处理一下!调度器!这是需要跟进URL你帮我处理下。然后从第四步开始循环,直到获取完老大需要全部信息。
14 管道调度器:好的,现在就做!
注意!只有当调度器中不存在任何request了,整个程序才会停止,(也就是说,对于下载失败的URL,Scrapy也会重新下载。)
八, 中间件
scrapy有哪些中间件?
- 下载中间件(推荐)
- 爬虫中间件
下载中间件的作用:
- 批量拦截所有的请求(request)和响应(response)
为什么拦截请求?
- 篡改请求的头信息(UA):
request.headers['User-Agent'] = 'xxxxx' - 设置代理:
request.meta['proxy'] = 'http://ip:port'
为什么拦截响应?
- 篡改响应数据
- 篡改响应对象(推荐)
案例分析:
爬取网易新闻(国内,国际,军事,航空,无人机)新闻数据的标题和内容,并且调用百度AI对文章内容进行标签提取和文章分类
分析:
1.每一个板块下对应的新闻数据都是动态加载出来的
2.会对五个板块的响应数据进行数据解析,但是板块对应的响应对象是不包含动态加载的新闻数据,目前获取的每一个板块对应的响应对象是不满足需求的响应对象
3.将不满足需求的5个响应对象(工程中一共会有1+5+n),修改成满足需求的响应对象。
# 爬虫文件中
import scrapy
from NewsPro.items import NewsproItem
from selenium import webdriver
import time
from aip import AipNlp
class NewsSpider(scrapy.Spider):
name = 'news'
# allowed_domains = ['https://news.163.com']
start_urls = ['https://news.163.com/']
# 5个板块的url
model_urls = []
# 打开selenium
browser = webdriver.Chrome(executable_path='./chromedriver.exe')
time.sleep(1)
# 解析出每个板块对应的url
def parse(self, response):
li_index = [3, 4, 6, 7, 8]
li_list = response.xpath('//div[@class="ns_area list"]/ul/li')
for index in li_index:
# 解析到每个板块的url
model_url = li_list[index].xpath('./a/@href').extract_first()
self.model_urls.append(model_url)
# 对板块的url进行请求发送获取每一个板块对应的页面源码数据
yield scrapy.Request(model_url, self.parse_model)
# 请求每个板块的页面源码数据,解析出新闻的标题和详情页url
def parse_model(self, response):
div_list = response.xpath('//div[@class="ndi_main"]/div')
for div in div_list:
item = NewsproItem()
new_url = div.xpath('./div/div[1]/h3/a/@href').extract_first()
title = div.xpath('./div/div[1]/h3/a/text()').extract_first()
if new_url and title:
item['title'] = title
# 对新闻的详情页进行请求发送,获取详情页的页面源码数据
yield scrapy.Request(new_url, self.parse_new, meta={'item': item})
# 解析新闻详情页数据,并提交给管道
def parse_new(self, response):
content = response.xpath('//*[@id="endText"]//text()').extract()
content = ''.join(content)
item = response.meta['item']
item['content'] = content
yield item
# 关闭selenium浏览器
def closed(self, spider):
self.browser.quit()
from scrapy import signals
import random
from time import sleep
from scrapy.http import HtmlResponse
user_agent_list = ['xxx', 'xxx']
class NewsproDownloaderMiddleware(object):
def process_request(self, request, spider):
# 通过中间件进行UA伪装,尽量每次使用不同的UA
request.headers['User-Agent'] = random.choice(user_agent_list)
return None
def process_response(self, request, response, spider):
# selenium对象
browser = spider.browser
url = request.url
# 判断是否5个模块的url
if url in spider.model_urls:
browser.get(url)
sleep(1)
# 下来滚轴,获取全部的动态加载数据
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(1)
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(1)
browser.execute_script('window.scrollTo(0,document.body.scrollHeight)')
sleep(1)
page_text = browser.page_source
# 封装一个response对象,替代不符合要求的response对象
response = HtmlResponse(url=request.url, body=page_text, encoding='utf-8', request=request)
return response
九, Crawl Spider
用途: 便捷的实现全站数据爬取
- 新建工程
scrapy startproject proName cd proName- 创建爬虫文件
scrapy genspider -t crawl spiderName www.xxx.com
核心:
链接提取器(LinkExtractor)
- 可以根据指定的规则对指定的链接进行提取
- 提取的规则就是构造方法中的allow参数决定的,是一个正则表达式
规则解析器(Rule)
- 可以将链接提取器提取到的链接进行请求发送
- 可以根据指定的规则(callback)对请求到的数据进行解析
follow=True: 将链接提取器继续作用到链接提取到的链接所对应的页面源码中,实现深度爬取
案例:
爬取http://wz.sun0769.com/html/top/report.shtml中所有页文章的标题和内容
class LxSpider(CrawlSpider):
name = 'lx'
# allowed_domains = ['www.xxx.com']
start_urls = ['http://wz.sun0769.com/html/top/report.shtml']
# 链接提取器
link = LinkExtractor(allow=r'page=\d+')
link_1 = LinkExtractor(allow=r'page=$')
link_detail = LinkExtractor(allow=r'question/\d+/\d+\.shtml')
rules = (
# 实例化一个Rule(规则解析器)对象
# follow=True: 将链接提取器 继续 作用到链接提取到的链接所对应的页面源码中
Rule(link_1, callback='parse_item', follow=False),
Rule(link, callback='parse_item', follow=True),
Rule(link_detail, callback='parse_item_detail', follow=False),
)
# 数据解析,是用来解析链接提取器提取到的链接所对应的页面
def parse_item(self, response):
tr_list = response.xpath('/html/body/div[8]/table[2]//tr')
for tr in tr_list:
title = tr.xpath('./td[3]/a/text()').extract_first()
num = tr.xpath('./td[1]/text()').extract_first()
item = Item2()
item['title'] = title
item['num'] = num
yield item
# 解析详情页中的新闻内容
def parse_item_detail(self, response):
content = ''.join(response.xpath('/html/body/div[9]/table[2]//tr[1]/td//text()').extract())
num = response.xpath('/html/body/div[9]/table[1]//tr/td[2]/span[2]/text()').extract_first().split(':')[-1]
item = Item1()
item['content'] = content
item['num'] = num
yield item
注意, 如果想将不同页面的数据统一保存,使用Crawl Spider不是很方便,因为它无法进行请求传参.
十, 分布式
什么是分布式?
需要搭建一个由n台电脑组成的机群,然后在每一台电脑中执行同一组程序,让其对同一个网络资源进行联合且分布的数据爬取,大幅度提升爬取效率
实现方式:
scrapy+scrapy_redis组件实现的分布式.
注意, 原生的scrapy是不可以实现分布式的,为什么?
- 调度器不可以被分布式机群共享
- 管道不可以被分布式机群共享
scrapy-redis组件的作用是什么?
- 提供可以被共享的管道和调度器
实现流程:
环境的安装:
pip install scrapy-redis创建工程:
scrapy startproject proNamecd proName创建爬虫文件
- 基于Spider
- 基于Craw Spider
修改爬虫文件
1. 导入:
from scrapy_redis.spiders import RedisCrawlSpider
from scrapy_redis.spiders import RedisSpider
将当前爬虫类的父类修改为导入的类
删除allowed_domains和start_urls
添加一个redis_key = 'xxx'属性,表示调度器队列的名称
根据常规形式编写爬虫文件后续的代码
修改settings.py配置文件
# 指定管道
ITEM_PIPELINES = {
'scrapy_redis.pipelines.RedisPipeline': 400
} # 指定调度器 # 增加了一个去重容器类的配置, 作用使用Redis的set集合来存储请求的指纹数据, 从而实现请求去重的持久化
DUPEFILTER_CLASS = "scrapy_redis.dupefilter.RFPDupeFilter"
# 使用scrapy-redis组件自己的调度器
SCHEDULER = "scrapy_redis.scheduler.Scheduler"
# 配置调度器是否要持久化, 也就是当爬虫结束了, 要不要清空Redis中请求队列和去重指纹的set。如果是True, 就表示要持久化存储, 就不清空数据, 否则清空数据
SCHEDULER_PERSIST = True
# 指定redis数据库
REDIS_HOST = '127.0.0.1'
REDIS_PORT = 6379
修改redis的配置文件
redis.windows.conf关闭默认绑定
56行: # bind 127.0.0.1
关闭保护模式
75行: protected-mode no
启动redis的服务端(携带配置文件)和客户端
启动分布式的程序
cd 到spiders文件夹内
scrapy runspider xxx.py
向调度器的队列中添加一个起始的url
队列是存在于redis中的
redis的客户端中: lpush sun www.xxx.com
案例:
# spiders文件中
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapy_redis.spiders import RedisCrawlSpider
from fenbushi.items import FenbushiItem
class FbsSpider(RedisCrawlSpider):
name = 'fbs'
# allowed_domains = ['www.xxx.com']
# start_urls = ['http://www.xxx.com/']
redis_key = 'sun' # 可被共享的调度器队列的名称,即需要添加起始url的redis中的set
link = LinkExtractor(allow=r'page=\d+')
rules = (
Rule(link, callback='parse_item', follow=True),
)
def parse_item(self, response):
tr_list = response.xpath('/html/body/div[8]/table[2]//tr')
for tr in tr_list:
title = tr.xpath('./td[3]/a/text()').extract_first()
item = FenbushiItem()
item['title'] = title
yield item
十一, 增量式
概念: 监测网站数据更新
核心技术: 去重
适合使用增量式的网站:
- 基于深度爬取: 对爬取过的页面的url进行记录(记录表)
- 基于非深度爬取: 爬取过的数据对应的数据指纹(记录表)
- 数据指纹: 原始数据的一组唯一标识(例如MD5值)
记录表是以怎样的形式存在于哪?
推荐使用redis的set充当记录表
案例:
监测https://www.4567tv.tv/index.php/vod/show/id/1/page/1.html的电影标题与简介
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from redis import Redis
from zlsPro.items import ZlsproItem
class ZlsSpider(CrawlSpider):
name = 'zls'
start_urls = ['https://www.4567tv.tv/index.php/vod/show/id/1/page/1.html']
# 解析每一页的页码链接
link = LinkExtractor(allow=r'1/page/\d+\.html')
rules = (
Rule(link, callback='parse_item', follow=False),
)
conn = Redis(host='127.0.0.1', port=6379)
def parse_item(self, response):
li_list = response.xpath('/html/body/div[1]/div/div/div/div[2]/ul/li')
for li in li_list:
detail_url = 'https://www.4567tv.tv' + li.xpath('./div/a/@href').extract_first()
ex = self.conn.sadd('urls', detail_url)
if ex == 1:
# detail_url不存在于redis的set中
yield scrapy.Request(detail_url, self.parse_detail)
else:
# detail_url存在于redis的set中
print('无数据更新')
def parse_detail(self, response):
title = response.xpath('/html/body/div[1]/div/div/div/div[2]/h1/text()').extract_first()
desc = response.xpath('/html/body/div[1]/div/div/div/div[2]/p[5]/span[3]/text()').extract_first()
print(title, '是新数据')
item = ZlsproItem()
item['title'] = title
item['desc'] = desc
yield item
十二, 反爬机制
robots: 不管它..
UA检测: UA伪装
图片懒加载: 获取相应的伪属性对应的值
验证码: 打码平台,selenium
cookie: session对象自动记录cookie
动态加载的数据: 使用抓包工具,获取动态加载数据对应的url
动态变化的请求参数: 一般隐藏在页面源码中
IP检测: IP代理池
js混淆: js反混淆
js加密: 找到对应的js代码,使用PyExecJS运行js代码
Scrapy框架的应用的更多相关文章
- Python爬虫Scrapy框架入门(2)
本文是跟着大神博客,尝试从网站上爬一堆东西,一堆你懂得的东西 附上原创链接: http://www.cnblogs.com/qiyeboy/p/5428240.html 基本思路是,查看网页元素,填写 ...
- Python爬虫Scrapy框架入门(1)
也许是很少接触python的原因,我觉得是Scrapy框架和以往Java框架很不一样:它真的是个框架. 从表层来看,与Java框架引入jar包.配置xml或.property文件不同,Scrapy的模 ...
- Scrapy框架使用—quotesbot 项目(学习记录一)
一.Scrapy框架的安装及相关理论知识的学习可以参考:http://www.yiibai.com/scrapy/scrapy_environment.html 二.重点记录我学习使用scrapy框架 ...
- Python爬虫从入门到放弃(十一)之 Scrapy框架整体的一个了解
这里是通过爬取伯乐在线的全部文章为例子,让自己先对scrapy进行一个整理的理解 该例子中的详细代码会放到我的github地址:https://github.com/pythonsite/spider ...
- Python爬虫从入门到放弃(十二)之 Scrapy框架的架构和原理
这一篇文章主要是为了对scrapy框架的工作流程以及各个组件功能的介绍 Scrapy目前已经可以很好的在python3上运行Scrapy使用了Twisted作为框架,Twisted有些特殊的地方是它是 ...
- python爬虫scrapy框架——人工识别登录知乎倒立文字验证码和数字英文验证码(2)
操作环境:python3 在上一文中python爬虫scrapy框架--人工识别知乎登录知乎倒立文字验证码和数字英文验证码(1)我们已经介绍了用Requests库来登录知乎,本文如果看不懂可以先看之前 ...
- 一个scrapy框架的爬虫(爬取京东图书)
我们的这个爬虫设计来爬取京东图书(jd.com). scrapy框架相信大家比较了解了.里面有很多复杂的机制,超出本文的范围. 1.爬虫spider tips: 1.xpath的语法比较坑,但是你可以 ...
- 安装scrapy框架的常见问题及其解决方法
下面小编讲一下自己在windows10安装及配置Scrapy中遇到的一些坑及其解决的方法,现在总结如下,希望对大家有所帮助. 常见问题一:pip版本需要升级 如果你的pip版本比较老,可能在安装的过程 ...
- 关于使用scrapy框架编写爬虫以及Ajax动态加载问题、反爬问题解决方案
Python爬虫总结 总的来说,Python爬虫所做的事情分为两个部分,1:将网页的内容全部抓取下来,2:对抓取到的内容和进行解析,得到我们需要的信息. 目前公认比较好用的爬虫框架为Scrapy,而且 ...
- 利用scrapy框架进行爬虫
今天一个网友问爬虫知识,自己把许多小细节都忘了,很惭愧,所以这里写一下大概的步骤,主要是自己巩固一下知识,顺便复习一下.(scrapy框架有一个好处,就是可以爬取https的内容) [爬取的是杨子晚报 ...
随机推荐
- [洛谷P2154] SDOI2009 虔诚的墓主人
问题描述 小W是一片新造公墓的管理人.公墓可以看成一块N×M的矩形,矩形的每个格点,要么种着一棵常青树,要么是一块还没有归属的墓地. 当地的居民都是非常虔诚的基督徒,他们愿意提前为自己找一块合适墓地. ...
- 表格 td 设置宽度无效问题
现在有个需求,就是表格的列不固定,都是动态加载的,想给每一列设置宽度,但是设置 width:100xp,没有效果,不过设置min-width:100px 就有效果了,table的宽度为 td的宽度和 ...
- CSS画心形和蛋形
一.心形 使用transform-origin属性实现设置不同的点为原点 1.改变元素基点transform-origin(transform-origin是变形原点,原点就是元素绕着旋转或变形的点) ...
- JavaScript自增和自减
一.自增++ 通过自增运算符可以使变量在自身的基础上加一: 对于一个变量自增以后,原变量的值会立即自增一: 自增符号:++ 自增分为两种:1.后++(a++):2.前++(++a): 共同点:a++ ...
- python 存取字典dict
数据处理的时候主要通过两个函数(1):np.save(“test.npy”,数据结构) ----存数据(2):data =np.load('test.npy") ----取数据 1.存列表 ...
- Python_019(六星级别之反射方法)
1.反射 1)神赐给你的内置函数 : a: getattr(命名空间,'函数名') == 命名空间.属性名; 这里的命名空间指的是对象或者类; b: getattr四个应用场景: 1)类名.名字 &l ...
- Internet History, Technology, and Security(week8)——Security: Encrypting and Signing
Hiding Date from Ohters Security Introduction Alice and Bob是密码学.博弈论.物理学等领域中的通用角色之一.Alice(代表A)和Bob(代表 ...
- 在 iTerm2 终端使用 command + ;会弹出最近使用的命令列表
- 北风设计模式课程---开放封闭原则(Open Closed Principle)
北风设计模式课程---开放封闭原则(Open Closed Principle) 一.总结 一句话总结: 抽象是开放封闭原则的关键. 1."所有的成员变量都应该设置为私有(Private)& ...
- jquery.ui.widget.js