java正则表达式详细总结
Java 提供了功能强大的正则表达式API,在java.util.regex 包下。本教程介绍如何使用正则表达式API。
正则表达式
一个正则表达式是一个用于文本搜索的文本模式。换句话说,在文本中搜索出现的模式。例如,你可以用正则表达式搜索网页中的邮箱地址或超链接。
正则表达式示例
下面是一个简单的Java正则表达式的例子,用于在文本中搜索 http://
String text =
"This is the text to be searched " +
"for occurrences of the http:// pattern.";
String pattern = ".*http://.*";
boolean matches = Pattern.matches(pattern, text);
System.out.println("matches = " + matches);
示例代码实际上没有检测找到的 http:// 是否是一个合法超链接的一部分,如包含域名和后缀(.com,.net 等等)。代码只是简单的查找字符串 http:// 是否出现。
Java6 中关于正则表达式的API
本教程介绍了Java6 中关于正则表达式的API。
Pattern (java.util.regex.Pattern)
类 java.util.regex.Pattern 简称 Pattern, 是Java正则表达式API中的主要入口,无论何时,需要使用正则表达式,从Pattern 类开始
Pattern.matches()
检查一个正则表达式的模式是否匹配一段文本的最直接方法是调用静态方法Pattern.matches(),示例如下:
String text =
"This is the text to be searched " +
"for occurrences of the pattern.";
String pattern = ".*is.*";
boolean matches = Pattern.matches(pattern, text);
System.out.println("matches = " + matches);
上面代码在变量 text 中查找单词 “is” 是否出现,允许”is” 前后包含 0或多个字符(由 .* 指定)
Pattern.matches() 方法适用于检查 一个模式在一个文本中出现一次的情况,或适用于Pattern类的默认设置。
如果需要匹配多次出现,甚至输出不同的匹配文本,或者只是需要非默认设置。需要通过Pattern.compile() 方法得到一个Pattern 实例。
Pattern.compile()
如果需要匹配一个正则表达式在文本中多次出现,需要通过Pattern.compile() 方法创建一个Pattern对象。示例如下
String text =
"This is the text to be searched " +
"for occurrences of the http:// pattern.";
String patternString = ".*http://.*";
Pattern pattern = Pattern.compile(patternString);
可以在Compile 方法中,指定一个特殊标志:Pattern pattern = Pattern.compile(patternString, Pattern.CASE_INSENSITIVE);
Pattern 类包含多个标志(int 类型),这些标志可以控制Pattern 匹配模式的方式。上面代码中的标志使模式匹配是忽略大小写
Pattern.matcher()
一旦获得了Pattern对象,接着可以获得Matcher对象。Matcher 示例用于匹配文本中的模式.示例如下Matcher matcher = pattern.matcher(text);
Matcher类有一个matches()方法,可以检查文本是否匹配模式。以下是关于Matcher的一个完整例子
String text =
"This is the text to be searched " +
"for occurrences of the http:// pattern.";
String patternString = ".*http://.*";
Pattern pattern = Pattern.compile(patternString, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(text);
boolean matches = matcher.matches();
System.out.println("matches = " + matches);
Pattern.split()
Pattern 类的 split()方法,可以用正则表达式作为分隔符,把文本分割为String类型的数组。示例:
String text = "A sep Text sep With sep Many sep Separators";
String patternString = "sep";
Pattern pattern = Pattern.compile(patternString);
String[] split = pattern.split(text);
System.out.println("split.length = " + split.length);
for(String element : split){
System.out.println("element = " + element);
}
上例中把text 文本分割为一个包含5个字符串的数组。
Pattern.pattern()
Pattern 类的 pattern 返回用于创建Pattern 对象的正则表达式,示例:
String patternString = "sep"; Pattern pattern = Pattern.compile(patternString); String pattern2 = pattern.pattern();
上面代码中 pattern2 值为sep ,与patternString 变量相同。
Matcher (java.util.regex.Matcher)
java.util.regex.Matcher 类用于匹配一段文本中多次出现一个正则表达式,Matcher 也适用于多文本中匹配同一个正则表达式。
Matcher 有很多有用的方法,详细请参考官方JavaDoc。这里只介绍核心方法。
以下代码演示如何使用Matcher
String text =
"This is the text to be searched " +
"for occurrences of the http:// pattern.";
String patternString = ".*http://.*";
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(text);
boolean matches = matcher.matches();
首先创建一个Pattern,然后得到Matcher ,调用matches() 方法,返回true 表示模式匹配,返回false表示不匹配。
可以用Matcher 做更多的事。
创建Matcher
通过Pattern 的matcher() 方法创建一个Matcher。
String text =
"This is the text to be searched " +
"for occurrences of the http:// pattern.";
String patternString = ".*http://.*";
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(text);
matches()
Matcher 类的 matches() 方法用于在文本中匹配正则表达式
boolean matches = matcher.matches();
如果文本匹配正则表达式,matches() 方法返回true。否则返回false。
matches() 方法不能用于查找正则表达式多次出现。如果需要,请使用find(), start() 和 end() 方法。
lookingAt()
lookingAt() 与matches() 方法类似,最大的不同是,lookingAt()方法对文本的开头匹配正则表达式;而
matches() 对整个文本匹配正则表达式。换句话说,如果正则表达式匹配文本开头而不匹配整个文本,lookingAt() 返回true,而matches() 返回false。 示例:
String text =
"This is the text to be searched " +
"for occurrences of the http:// pattern.";
String patternString = "This is the";
Pattern pattern = Pattern.compile(patternString, Pattern.CASE_INSENSITIVE);
Matcher matcher = pattern.matcher(text);
System.out.println("lookingAt = " + matcher.lookingAt());
System.out.println("matches = " + matcher.matches());
上面的例子分别对文本开头和整个文本匹配正则表达式 “this is the”. 匹配文本开头的方法(lookingAt()) 返回true。
对整个文本匹配正则表达式的方法 (matches()) 返回false,因为 整个文本包含多余的字符,而 正则表达式要求文本精确匹配”this is the”,前后又不能有额外字符。
find() + start() + end()
find() 方法用于在文本中查找出现的正则表达式,文本是创建Matcher时,通过 Pattern.matcher(text) 方法传入的。如果在文本中多次匹配,find() 方法返回第一个,之后每次调用 find() 都会返回下一个。
start() 和 end() 返回每次匹配的字串在整个文本中的开始和结束位置。实际上, end() 返回的是字符串末尾的后一位,这样,可以在把 start() 和 end() 的返回值直接用在String.substring() 里。
String text =
"This is the text which is to be searched " +
"for occurrences of the word 'is'.";
String patternString = "is";
Pattern pattern = Pattern.compile(patternString);
Matcher matcher = pattern.matcher(text);
int count = 0;
while(matcher.find()) {
count++;
System.out.println("found: " + count + " : " + matcher.start() + " - " + matcher.end());
}
这个例子在文本中找到模式 “is” 4次,输出如下:
found: 1 : 2 - 4 found: 2 : 5 - 7 found: 3 : 23 - 25 found: 4 : 70 - 72
reset()
reset() 方法会重置Matcher 内部的 匹配状态。当find() 方法开始匹配时,Matcher 内部会记录截至当前查找的距离。调用 reset() 会重新从文本开头查找。
也可以调用 reset(CharSequence) 方法. 这个方法重置Matcher,同时把一个新的字符串作为参数传入,用于代替创建 Matcher 的原始字符串。
group()
假设想在一个文本中查找URL链接,并且想把找到的链接提取出来。当然可以通过 start()和 end()方法完成。但是用group()方法更容易些。
分组在正则表达式中用括号表示,例如:
(John)
此正则表达式匹配John, 括号不属于要匹配的文本。括号定义了一个分组。当正则表达式匹配到文本后,可以访问分组内的部分。
使用group(int groupNo) 方法访问一个分组。一个正则表达式可以有多个分组。每个分组由一对括号标记。想要访问正则表达式中某分组匹配的文本,可以把分组编号传入 group(int groupNo)方法。
group(0) 表示整个正则表达式,要获得一个有括号标记的分组,分组编号应该从1开始计算。
String text = "John writes about this, and John writes about that," +
" and John writes about everything. " ;
String patternString1 = "(John)";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
while(matcher.find()) {
System.out.println("found: " + matcher.group(1));
}
以上代码在文本中搜索单词John.从每个匹配文本中,提取分组1,就是由括号标记的部分。输出如下
found: John found: John found: John
多分组
上面提到,一个正则表达式可以有多个分组,例如:(John) (.+?)
这个表达式匹配文本”John” 后跟一个空格,然后跟1个或多个字符,最后跟一个空格。你可能看不到最后的空格。
这个表达式包括一些字符有特别意义。字符 点 . 表示任意字符。 字符 + 表示出现一个或多个,和. 在一起表示 任何字符,出现一次或多次。字符? 表示 匹配尽可能短的文本。
完整代码如下
String text =
"John writes about this, and John Doe writes about that," +
" and John Wayne writes about everything."
;
String patternString1 = "(John) (.+?) ";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
while(matcher.find()) {
System.out.println("found: " + matcher.group(1) +
" " + matcher.group(2));
}
注意代码中引用分组的方式。代码输出如下
found: John writes found: John Doe found: John Wayne
嵌套分组
在正则表达式中分组可以嵌套分组,例如((John) (.+?))
这是之前的例子,现在放在一个大分组里.(表达式末尾有一个空格)。
当遇到嵌套分组时, 分组编号是由左括号的顺序确定的。上例中,分组1 是那个大分组。分组2 是包括John的分组,分组3 是包括 .+? 的分组。当需要通过groups(int groupNo) 引用分组时,了解这些非常重要。
以下代码演示如何使用嵌套分组
String text =
"John writes about this, and John Doe writes about that," +
" and John Wayne writes about everything."
;
String patternString1 = "((John) (.+?)) ";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
while(matcher.find()) {
System.out.println("found: ");
}
输出如下
found: found: found:
replaceAll() + replaceFirst()
replaceAll() 和 replaceFirst() 方法可以用于替换Matcher搜索字符串中的一部分。replaceAll() 方法替换全部匹配的正则表达式,replaceFirst() 只替换第一个匹配的。
在处理之前,Matcher 会先重置。所以这里的匹配表达式从文本开头开始计算。
示例如下
String text =
"John writes about this, and John Doe writes about that," +
" and John Wayne writes about everything."
;
String patternString1 = "((John) (.+?)) ";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
String replaceAll = matcher.replaceAll("Joe Blocks ");
System.out.println("replaceAll = " + replaceAll);
String replaceFirst = matcher.replaceFirst("Joe Blocks ");
System.out.println("replaceFirst = " + replaceFirst);
输出如下
replaceAll = Joe Blocks about this, and Joe Blocks writes about that, and Joe Blocks writes about everything. replaceFirst = Joe Blocks about this, and John Doe writes about that, and John Wayne writes about everything.
输出中的换行和缩进是为了可读而增加的。
注意第1个字符串中所有出现 John 后跟一个单词 的地方,都被替换为 Joe Blocks 。第2个字符串中,只有第一个出现的被替换。
appendReplacement() + appendTail()
appendReplacement() 和 appendTail() 方法用于替换输入文本中的字符串短语,同时把替换后的字符串附加到一个 StringBuffer 中。
当find() 方法找到一个匹配项时,可以调用 appendReplacement() 方法,这会导致输入字符串被增加到StringBuffer 中,而且匹配文本被替换。 从上一个匹配文本结尾处开始,直到本次匹配文本会被拷贝。
appendReplacement() 会记录拷贝StringBuffer 中的内容,可以持续调用find(),直到没有匹配项。
直到最后一个匹配项目,输入文本中剩余一部分没有拷贝到 StringBuffer. 这部分文本是从最后一个匹配项结尾,到文本末尾部分。通过调用 appendTail() 方法,可以把这部分内容拷贝到 StringBuffer 中.
String text =
"John writes about this, and John Doe writes about that," +
" and John Wayne writes about everything."
;
String patternString1 = "((John) (.+?)) ";
Pattern pattern = Pattern.compile(patternString1);
Matcher matcher = pattern.matcher(text);
StringBuffer stringBuffer = new StringBuffer();
while(matcher.find()){
matcher.appendReplacement(stringBuffer, "Joe Blocks ");
System.out.println(stringBuffer.toString());
}
matcher.appendTail(stringBuffer);
System.out.println(stringBuffer.toString());
注意我们在while循环中调用appendReplacement() 方法。在循环完毕后调用appendTail()。 代码输出如下:
Joe Blocks Joe Blocks about this, and Joe Blocks Joe Blocks about this, and Joe Blocks writes about that, and Joe Blocks Joe Blocks about this, and Joe Blocks writes about that, and Joe Blocks writes about everything.
Java 正则表达式语法
为了更有效的使用正则表达式,需要了解正则表达式语法。正则表达式语法很复杂,可以写出非常高级的表达式。只有通过大量的练习才能掌握这些语法规则。
本篇文字,我们将通过例子了解正则表达式语法的基础部分。介绍重点将会放在为了使用正则表达式所需要了解的核心概念,不会涉及过多的细节。详细解释,参见 Java DOC 中的 Pattern 类.
基本语法
在介绍高级功能前,我们先快速浏览下正则表达式的基本语法。
字符
是正则表达式中最经常使用的的一个表达式,作用是简单的匹配一个确定的字符。例如:John
这个简单的表达式将会在一个输入文本中匹配John文本。
可以在表达式中使用任意英文字符。也可以使用字符对于的8进制,16进制或unicode编码表示。例如:101
\x41
\u0041
以上3个表达式 都表示大写字符A。第一个是8进制编码(101),第2个是16进制编码(41),第3个是unicode编码(0041).
字符分类
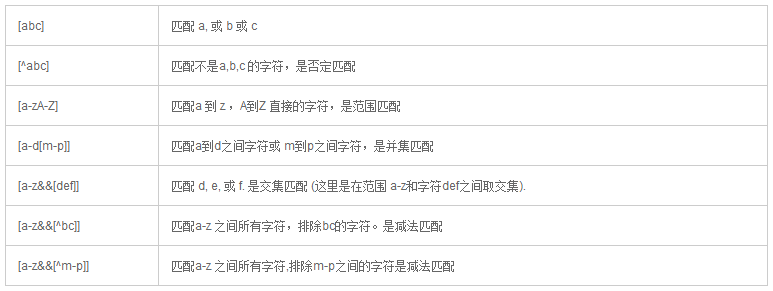
字符分类是一种结构,可以针对多个字符匹配而不只是一个字符。换句话说,一个字符分类匹配输入文本中的一个字符,对应字符分类中多个允许字符。例如,你想匹配字符 a,b 或c,表达式如下:[abc]
用一对方括号[] 表示字符分类。方括号本身并不是要匹配的一部分。
可以用字符分类完成很多事。例如想要匹配单词John,首字母可以为大写和小写J.[Jj]ohn
字符分类[Jj] 匹配J或j,剩余的 ohn 会准确匹配字符ohn.
预定义字符分类
正则表达式中有一些预定义的字符分类可以使用。例如, \d 表示任意数字, \s 表示任意空白字符,\w 表示任意单词字符。
预定义字符分类不需要括在方括号里,当然也可以组合使用\d
[\d\s]
第1个匹配任意数字,第2个匹配任意数字或空白符。
完整的预定义字符分类列表,在本文最后列出。
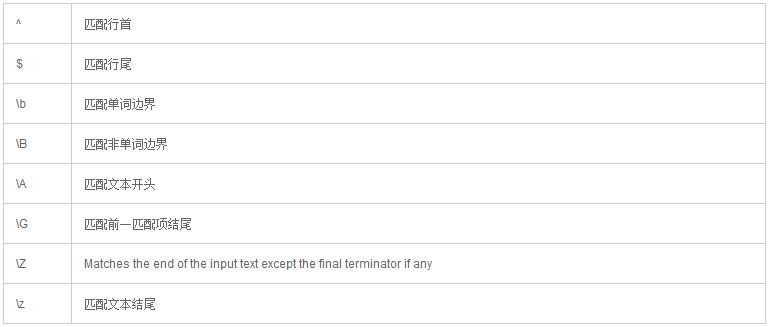
边界匹配
正则表达式支持匹配边界,例如单词边界,文本的开头或末尾。例如,\w 匹配一个单词,^匹配行首,$ 匹配行尾。^This is a single line$
上面的表达式匹配一行文本,只有文本 This is a single line。注意其中的行首和行尾标志,表示不能有任何文本在文本的前面后后面,只能是行首和行尾。
完整的匹配边界列表,在本文最后列出。
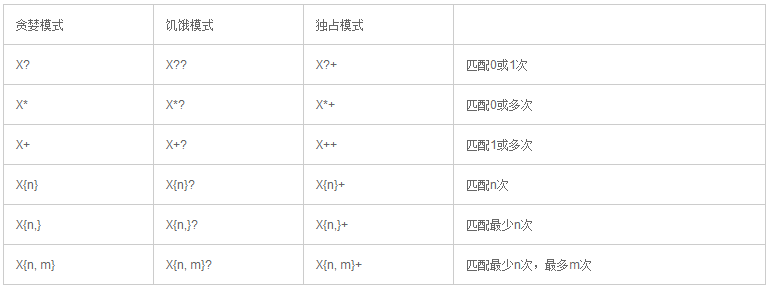
量词匹配
量词可以匹配一个表达式多次出现。例如下列表达式匹配字母A 出现0次或多次。A*
量词 * 表示0次或多次。+ 表示1次或多次。? 表示0次或1次。还有些其他量词,参见本文后面的列表。
量词匹配分为 饥饿模式,贪婪模式,独占模式。饥饿模式 匹配尽可能少的文本。贪婪模式匹配尽可能多的文本。独占模式匹配尽可能多的文本,甚至导致剩余表达式匹配失败。
以下演示饥饿模式,贪婪模式,独占模式区别。假设以下文本:John went for a walk, and John fell down, and John hurt his knee.
饥饿模式下 表达式:John.*?
这个表达式匹配John 后跟0个或多个字符。 . 表示任意字符。* 表示0或多次。? 跟在 * 后面,表示 * 采用饥饿模式。
饥饿模式下,量词只会匹配尽可能少的字符,即0个字符。上例中的表达式将会匹配单词John,在输入文本中出现3次。
如果改为贪婪模式,表达式如下:John.*
贪婪模式下,量词会匹配尽可能多的字符。现在表达式会匹配第一个出现的John,以及在贪婪模式下 匹配剩余的所有字符。这样,只有一个匹配项。
最后,我们改为独占模式:John.*+hurt
*后跟+ 表示独占模式量词。
这个表达式在输入文本中没有匹配项,尽管文本中包括 John 和 hurt. 为什么会这样? 因为 .*+ 是独占模式。与贪婪模式下,尽可能多的匹配文本,以使整个表达式匹配不同。独占模式会尽可能的多的匹配,但不考虑表达式剩余部分是否能匹配上。
.*+ 将会匹配第一个John之后的所有字符,这会导致表达式中剩余的 hurt 没有匹配项。如果改为贪婪模式,会有一个匹配项。表达式如下:John.*hurt
逻辑操作符
正则表达式支持少量的逻辑运算(与,或,非)。
与操作是默认的,表达式 John ,意味着J 与 o与h与n。
或操作需要显示指定,用 | 表示。例如表达式 John|hurt 意味着John 或 hurt 。
字符

字符分类
内置字符分类

边界匹配
量词
我有一个微信公众号,经常会分享一些Java技术相关的干货;如果你喜欢我的分享,可以用微信搜索“Java团长”或者“javatuanzhang”关注。
参考:
java正则表达式详细总结的更多相关文章
- Java 正则表达式详细使用
Java 正则表达式 java.util.regex.Pattern java.util.regex.Matcher 1.Matchmatch 是从字符串最头部开始匹配,一直到结束,需要匹配整个串 S ...
- Java 正则表达式详细实例解析
案例1:判断字符串是否是abc package Regex; import java.util.regex.Matcher; import java.util.regex.Pattern; /** * ...
- Java正则表达式详细解析
元字符 正则表达式使用一些特定的元字符来检索.匹配和替换符合规则的字符串 元字符:普通字符.标准字符.限定字符(量词).定位字符(边界字符) 正则表达式引擎 正则表达式是一个用正则符号写出来的公式 程 ...
- JAVA 正则表达式 (超详细)
(PS:这篇文章为转载,我不喜欢转载的但我觉得这篇文章实在是超赞了,就转了过来,这篇可以说是学习JAVA正则表达的必读篇.作者是个正真有功力的人,阅读愉快) 在Sun的Java JDK 1.40版本中 ...
- 转载:JAVA 正则表达式 (超详细)
在Sun的JavaJDK 1.40版本中,Java自带了支持正则表达式的包,本文就抛砖引玉地介绍了如何使用Java.util.regex包. 可粗略估计一下,除了偶尔用Linux的外,其他Linu x ...
- Java 正则表达式详解
Java 提供了功能强大的正则表达式API,在java.util.regex 包下.本教程介绍如何使用正则表达式API. 正则表达式 一个正则表达式是一个用于文本搜索的文本模式.换句话说,在文本中搜索 ...
- JAVA正则表达式:Pattern类与Matcher类详解(转)
java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包.它包括两个类:Pattern和Matcher Pattern 一个Pattern是一个正则表达式经编译后的表 ...
- JAVA正则表达式:Pattern类与Matcher类详解
java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包.它包括两个类:Pattern和Matcher Pattern 一个Pattern是一个正则表达式经编译后的表 ...
- Java正则表达式实用教程
java.util.regex是一个用正则表达式所订制的模式来对字符串进行匹配工作的类库包.java.util.regex包主要包括以下三个类:Pattern.Matcher和PatternSynta ...
随机推荐
- Centos7环境下Docker容器的安装与卸载
Docker是一个开源的引擎,可以轻松的为任何应用创建一个轻量级的.可移植的.自给自足的容器.开发者在笔记本上编译测试通过的容器可以批量地在生产环境中部署,包括VMs(虚拟机).bare metal. ...
- python:set() 函数
描述 Python 内置函数 创建一个无序不重复元素集 可进行关系测试,删除重复数据 集合对象还支持union(联合), intersection(交), difference(差)和sysmmetr ...
- 102、如何滚动更新 Service (Swarm09)
参考https://www.cnblogs.com/CloudMan6/p/7988455.html 在前面的实验中,我们部署了多个副本的服务,本节将讨论如何滚动更新每一个副本. 滚动更新降低 ...
- java复制文件范例代码
String url1 = "F:\\SuperMap-Projects\\region.udb";// 源文件路径 try { for(int i=1;i<101;i++) ...
- EF报错:对一个或多个实体的验证失败(Entity Framework 强制转换失败数据异常处理方法)
1.使用MVC和EF,在保存数据的时候报错:System.Data.Entity.Validation.DbEntityValidationException: 对一个或多个实体的验证失败.有关详细信 ...
- (转)Java并发编程:核心理论
原文链接:https://www.cnblogs.com/paddix/p/5374810.html Java并发编程系列: Java 并发编程:核心理论 Java并发编程:Synchronized及 ...
- 19、Firewalld防火墙
安全的考虑方向: 安全框架 OSI七层模型 硬件 机架上锁(机柜) 温度 硬件检查 网络 iptables/firewalld 仅允许公司的IP地址能连接服务器的22端口 公有云使用 安全组 系统 没 ...
- 第二章 Vue快速入门-- 15 vue中通过属性绑定为元素设置class类样式
<!DOCTYPE html> <html lang="en"> <head> <meta charset="utf-8&quo ...
- 高性能mysql 第6章 查询性能优化
查询缓存: 在解析一个sql之前,如果查询缓存是打开的,mysql会去检查这个查询(根据sql的hash作为key)是否存在缓存中,如果命中的话,那么这个sql将会在解析,生成执行计划之前返回结果. ...
- oozie 启动过程中--- Existing PID file found during start. Removing/clearing stale PID file.
如果oozie使用kill -9 暴力杀死了tomcat,再启动的时候,会出问题,需要删除tomcat的pid文件 彻底停止oozie的tomcat的进程,然后删除pid文件 rm -rf /exp ...