高可用,多路冗余GFS2集群文件系统搭建详解
2014.06
实验拓扑图:
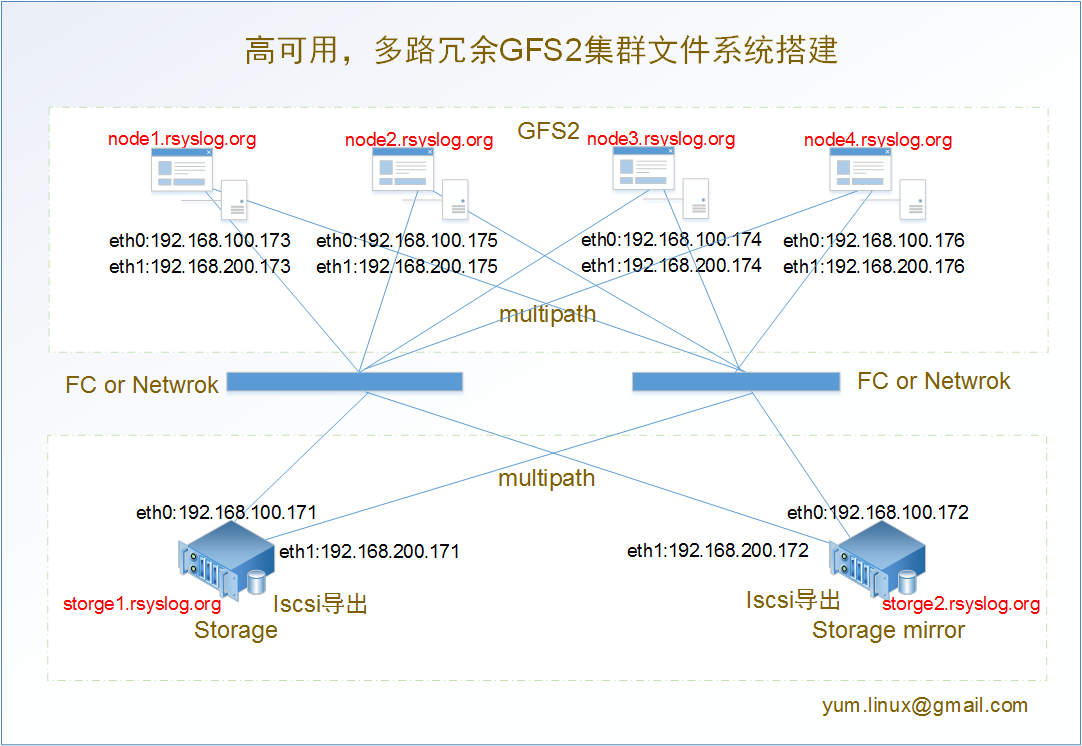
实验原理:
实验目的:通过RHCS集群套件搭建GFS2集群文件系统,保证不同节点能够同时对GFS2集群文件系统进行读取和写入,其次通过multipath实现node和FC,FC和Share Storage之间的多路冗余,最后实现存储的mirror复制达到高可用。
GFS2:全局文件系统第二版,GFS2是应用最广泛的集群文件系统。它是由红帽公司开发出来的,允许所有集群节点并行访问。元数据通常会保存在共享存储设备或复制存储设备的一个分区里或逻辑卷中。
实验环境:
|
1
2
3
4
5
6
7
8
|
[root@storage1 ~]# uname -r2.6.32-279.el6.x86_64[root@storage1 ~]# cat /etc/redhat-releaseRed Hat Enterprise Linux Server release 6.3 (Santiago)[root@storage1 ~]# /etc/rc.d/init.d/iptables statusiptables: Firewall is not running.[root@storage1 ~]# getenforceDisabled |
实验步骤:
1、前期准备工作
0)、设置一台管理端(192.168.100.102manager.rsyslog.org)配置ssh 私钥、公钥,将公钥传递到所有节点上
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@manager ~]# ssh-keygen \\生成公钥和私钥Generating public/private rsa key pair.Enter file in which to save the key (/root/.ssh/id_rsa):Enter passphrase (empty for no passphrase):……[root@manager ~]# for i in {1..6}; do ssh-copy-id -i 192.168.100.17$i; done \\将公钥传输到各节点/root/.ssh/目录下root@192.168.100.171's password:Now try logging into the machine, with "ssh '192.168.100.171'", and check in:.ssh/authorized_keysto make sure we haven't added extra keys that you weren't expecting..……[root@manager ~]# ssh node1 \\测试登录Last login: Sat Jun 8 17:58:51 2013 from 192.168.100.31[root@node1 ~]# |
1)、配置双网卡IP,所有节点参考拓扑图配置双网卡,并配置相应IP即可
|
1
2
3
4
5
|
[root@storage1 ~]# ifconfig eth0 | grep "inet addr" | awk -F[:" "]+ '{ print $4 }'192.168.100.171[root@storage1 ~]# ifconfig eth1 | grep "inet addr" | awk -F[:" "]+ '{ print $4 }'192.168.200.171…… |
2)、配置hosts文件并同步到所有节点去(也可以配置DNS,不过DNS解析绝对不会有hosts解析快,其次DNS服务器出问题会直接导致节点和节点以及和存储直接不能够解析而崩溃)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
|
[root@manager ~]# cat /etc/hosts127.0.0.1 localhost localhost.rsyslog.org192.168.100.102 manager manager.rsyslog.org192.168.100.171 storage1 storage1.rsyslog.org192.168.200.171 storage1 storage1.rsyslog.org192.168.100.172 storage2 storage2.rsyslog.org192.168.200.172 storage2 storage2.rsyslog.org192.168.100.173 node1 node1.rsyslog.org192.168.200.173 node1 node1.rsyslog.org192.168.100.174 node2 node2.rsyslog.org192.168.200.174 node2 node2.rsyslog.org192.168.100.175 node3 node3.rsyslog.org192.168.200.175 node3 node3.rsyslog.org192.168.100.176 node4 node4.rsyslog.org192.168.200.176 node4 node4.rsyslog.org[root@manager ~]# for i in {1..6}; do scp /etc/hosts 192.168.100.17$i:/etc/ ; donehosts 100% 591 0.6KB/s 00:00hosts 100% 591 0.6KB/s 00:00hosts 100% 591 0.6KB/s 00:00hosts 100% 591 0.6KB/s 00:00hosts 100% 591 0.6KB/s 00:00hosts 100% 591 0.6KB/s 00:00 |
3)、配置yum源(将所有节点光盘挂接到/media/cdrom,如果不方便,也可以做NFS,将镜像挂载到NFS里面,然后节点挂载到NFS共享目录中即可,注意:不同版本的系统,RHCS集群套件存放位置会有所不同,所以yum源的指向位置也会有所不同)
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
|
[root@manager ~]# cat /etc/yum.repos.d/rhel-gfs2.repo[rhel-cdrom]name=RHEL6U3-cdrombaseurl=file:///media/cdromenabled=1gpgcheck=0[rhel-cdrom-HighAvailability]name=RHEL6U3-HighAvailabilitybaseurl=file:///media/cdrom/HighAvailabilityenabled=1gpgcheck=0[rhel-cdrom-ResilientStorage]name=RHEL6U3-ResilientStoragebaseurl=file:///media/cdrom/ResilientStorageenabled=1gpgcheck=0[rhel-cdrom-LoadBalancer]name=RHEL6U3-LoadBalancerbaseurl=file:///media/cdrom/LoadBalancerenabled=1gpgcheck=0[rhel-cdrom-ScalableFileSystem]name=RHEL6U3-ScalableFileSystembaseurl=file:///media/cdrom/ScalableFileSystemenabled=1gpgcheck=0[root@manager ~]# for i in {1..6}; do scp /etc/yum.repos.d/rhel-gfs2.repo 192.168.100.17$i:/etc/yum.repos.d ; donerhel-gfs2.repo 100% 588 0.6KB/s 00:00rhel-gfs2.repo 100% 588 0.6KB/s 00:00rhel-gfs2.repo 100% 588 0.6KB/s 00:00rhel-gfs2.repo 100% 588 0.6KB/s 00:00rhel-gfs2.repo 100% 588 0.6KB/s 00:00rhel-gfs2.repo 100% 588 0.6KB/s 00:00[root@manager ~]# for i in {1..6}; do ssh 192.168.100.17$i "yum clean all && yum makecache"; doneLoaded plugins: product-id, security, subscription-managerUpdating certificate-based repositories.Unable to read consumer identity…… |
4)、时间要同步,可以考虑配置NTP时间服务器,如果联网可以考虑同步互联网时间,当然也可以通过date命令设置相同时间。
2、安装luci和ricci(管理端安装luci,节点安装ricci)
Luci是运行WEB样式的Conga服务器端,它可以通过web界面很容易管理整个RHCS集群,每一步操作都会在/etc/cluster/cluster.conf生成相应的配置信息
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
|
[root@manager ~]# yum install luci –y[root@manager ~]# /etc/rc.d/init.d/luci start \\生成以下信息,说明配置成功,注意:安装luci会安装很多python包,python包尽量采用光盘自带的包,否则启动luci会出现报错现象。Adding following auto-detected host IDs (IP addresses/domain names), corresponding to `manager.rsyslog.org' address, to the configuration of self-managed certificate `/var/lib/luci/etc/cacert.config' (you can change them by editing `/var/lib/luci/etc/cacert.config', removing the generated certificate `/var/lib/luci/certs/host.pem' and restarting luci):(none suitable found, you can still do it manually as mentioned above)Generating a 2048 bit RSA private keywriting new private key to '/var/lib/luci/certs/host.pem'正在启动 saslauthd: [确定]Start luci... [确定]Point your web browser to https://manager.rsyslog.org:8084 (or equivalent) to access luci[root@manager ~]# for i in {1..4}; do ssh node$i "yum install ricci -y"; done[root@manager ~]# for i in {1..4}; do ssh node$i "chkconfig ricci on && /etc/rc.d/init.d/ricci start"; done[root@manager ~]# for i in {1..4}; do ssh node$i "echo '123.com' | passwd ricci --stdin"; done \\ricci设置密码,在Conga web页面添加节点的时候需要输入ricci密码。更改用户 ricci 的密码 。passwd: 所有的身份验证令牌已经成功更新。…… |
3、通过luci web管理界面安装RHCS集群套件
https://manager.rsyslog.org:8084或者https://192.168.100.102:8084
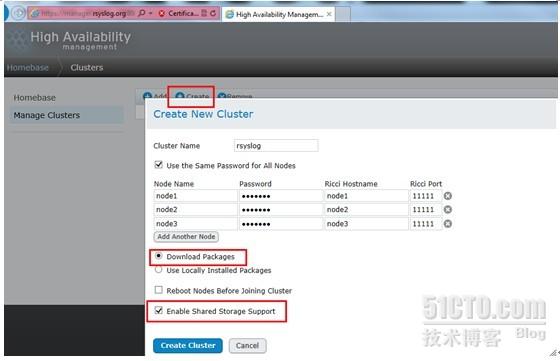
添加节点node1-node3,先设置3个,后期在增加一个节点,password为各节点ricci的密码,然后勾选“Download Packages”(在各节点yum配置好的基础上,自动安装cman和rgmanager及相关的依赖包),勾选“Enable Shared Storage Support”,安装存储相关的包,并支持gfs2文件系统、DLM锁、clvm逻辑卷等。
安装过程如下:
以下为安装完成之后,所有节点状态
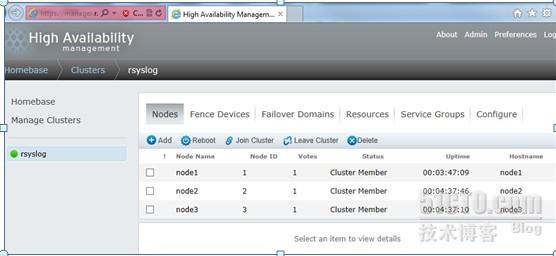
点开一个节点,可以看到这个节点上所有相关服务都处于运行状态。
登录任意一个节点查看各服务的开机启动情况,为2-5级别自动启动。
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
|
[root@manager ~]# ssh node1 "chkconfig --list | grep cman"cman 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭[root@manager ~]# ssh node1 "chkconfig --list | grep rgmanager"rgmanager 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭[root@manager ~]# ssh node1 "chkconfig --list | grep clvmd"clvmd 0:关闭 1:关闭 2:启用 3:启用 4:启用 5:启用 6:关闭[root@node2 ~]# cat /etc/cluster/cluster.conf \\查看各节点集群配置信息,各节点这部分必须一样。<?xml version="1.0"?><cluster config_version="1" name="rsyslog"><clusternodes><clusternode name="node1" nodeid="1"/><clusternode name="node2" nodeid="2"/></clusternodes><cman expected_votes="1" two_node="1"/><fencedevices/><rm/></cluster>[root@node2 ~]# clustat \\查看集群节点状态(可以通过 cluster -i 1 动态查看变化状态)Cluster Status for rsyslog @ Sat Jun 8 00:03:40 2013Member Status: QuorateMember Name ID Status------ ---- ---- ------node1 1 Onlinenode2 2 Online, Localnode3 3 Online |
4、安装存储管理管理软件,并导出磁
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
|
[root@storage1 ~]# fdisk /dev/sda \\创建一个大小为2G的逻辑分区并导出Command (m for help): nCommand actione extendedp primary partition (1-4)eSelected partition 4First cylinder (1562-2610, default 1562):Using default value 1562Last cylinder, +cylinders or +size{K,M,G} (1562-2610, default 2610): +4GCommand (m for help): nFirst cylinder (1562-2084, default 1562):Using default value 1562Last cylinder, +cylinders or +size{K,M,G} (1562-2084, default 2084): +2GCommand (m for help): w……[root@storage1 ~]# partx -a /dev/sda[root@storage1 ~]# ll /dev/sdasda sda1 sda2 sda3 sda4 sda5[root@storage1 ~]# yum install scsi-target-utils –y \\安装target管理端[root@storage1 ~]# vim /etc/tgt/targets.conf \\配置导出磁盘的信息<target iqn.2013.05.org.rsyslog:storage1.sda5><backing-store /dev/sda5>scsi_id storage1_idscsi_sn storage1_sn</backing-store>incominguser xiaonuo 081ac67e74a6bb13b7a22b8a89e7177b \\设置用户名及密码访问initiator-address 192.168.100.173 \\设置允许的IP地址initiator-address 192.168.100.174initiator-address 192.168.100.175initiator-address 192.168.100.176initiator-address 192.168.200.173initiator-address 192.168.200.174initiator-address 192.168.200.175initiator-address 192.168.200.176</target>[root@storage1 ~]# /etc/rc.d/init.d/tgtd start && chkconfig tgtd on[root@storage1 ~]# tgtadm --lld iscsi --mode target --op show \\查看是否导出成功Target 1: iqn.2013.05.org.rsyslog:storage1.sda5……LUN: 1Type: diskSCSI ID: storage1_idSCSI SN: storage1_snSize: 2151 MB, Block size: 512Online: YesRemovable media: NoPrevent removal: NoReadonly: NoBacking store type: rdwrBacking store path: /dev/sda5Backing store flags:Account information:xiaonuoACL information:192.168.100.173192.168.100.174192.168.100.175192.168.100.176192.168.200.173192.168.200.174192.168.200.175192.168.200.176[root@manager ~]# for i in {1..3}; do ssh node$i "yum -y install iscsi-initiator-utils"; done \\节点安装iscsi客户端软件[root@node1 ~]# vim /etc/iscsi/iscsid.conf \\所有节点配置文件加上以下3行,设置账户密码node.session.auth.authmethod = CHAPnode.session.auth.username = xiaonuonode.session.auth.password = 081ac67e74a6bb13b7a22b8a89e7177b[root@manager ~]# for i in {1..3}; do ssh node$i "iscsiadm -m discovery -t st -p 192.168.100.171"; done \\发现共享设备192.168.100.171:3260,1 iqn.2013.05.org.rsyslog:storage1.sda5192.168.100.171:3260,1 iqn.2013.05.org.rsyslog:storage1.sda5192.168.100.171:3260,1 iqn.2013.05.org.rsyslog:storage1.sda5[root@manager ~]# for i in {1..3}; do ssh node$i "iscsiadm -m discovery -t st -p 192.168.200.171"; done192.168.200.171:3260,1 iqn.2013.05.org.rsyslog:storage1.sda5192.168.200.171:3260,1 iqn.2013.05.org.rsyslog:storage1.sda5192.168.200.171:3260,1 iqn.2013.05.org.rsyslog:storage1.sda5[root@manager ~]# for i in {1..3}; do ssh node$i "iscsiadm -m node -l"; done \\注册iscsi共享设备Logging in to [iface: default, target: iqn.2013.05.org.rsyslog:storage1.sda5, portal: 192.168.200.171,3260] (multiple)Logging in to [iface: default, target: iqn.2013.05.org.rsyslog:storage1.sda5, portal: 192.168.100.171,3260] (multiple)Login to [iface: default, target: iqn.2013.05.org.rsyslog:storage1.sda5, portal: 192.168.200.171,3260] successful.Login to [iface: default, target: iqn.2013.05.org.rsyslog:storage1.sda5, portal: 192.168.100.171,3260] successful.……[root@storage1 ~]# tgtadm --lld iscsi --op show --mode conn --tid 1 \\iscsi服务器端查看共享情况Session: 12Connection: 0Initiator: iqn.1994-05.com.redhat:a12e282371a1IP Address: 192.168.200.175Session: 11Connection: 0Initiator: iqn.1994-05.com.redhat:a12e282371a1IP Address: 192.168.100.175…….[root@node1 ~]# netstat -nlatp | grep 3260tcp 0 0 192.168.200.173:37946 192.168.200.171:3260 ESTABLISHED 37565/iscsidtcp 0 0 192.168.100.173:54306 192.168.100.171:3260 ESTABLISHED 37565/iscsid[root@node1 ~]# ll /dev/sd \\在各个节点上面都会多出两个iscsi设备sda sda1 sda2 sda3 sdb sdc |
5、安装配置multipath多路冗余实现线路冗余
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
|
[root@manager ~]# for i in {1..3}; do ssh node$i "yum -y install device-mapper-*"; done[root@manager ~]# for i in {1..3}; do ssh node$i "mpathconf --enable"; done \\生成配置文件[root@node1 ~]# /sbin/scsi_id -g -u /dev/sdb \\查看导入设备的WWID1storage1_id[root@node1 ~]# /sbin/scsi_id -g -u /dev/sdc1storage1_id[root@node1 ~]# vim /etc/multipath.confmultipaths {multipath {wwid 1storage1_id \\设置导出设备的WWIDalias iscsi1 \\设置别名path_grouping_policy multibuspath_selector "round-robin 0"failback manualrr_weight prioritiesno_path_retry 5}}[root@node1 ~]# /etc/rc.d/init.d/multipathd startStarting multipathd daemon: [ OK ][root@node1 ~]# ll /dev/mapper/iscsi1lrwxrwxrwx 1 root root 7 Jun 7 23:58 /dev/mapper/iscsi1 -> ../dm-0[root@node1 ~]# multipath –ll \\查看绑定是否成功iscsi1 (1storage1_id) dm-0 IET,VIRTUAL-DISKsize=2.0G features='1 queue_if_no_path' hwhandler='0' wp=rw`-+- policy='round-robin 0' prio=1 status=active|- 20:0:0:1 sdb 8:16 active ready running`- 19:0:0:1 sdc 8:32 active ready running……\\其他两个节点同上 |
6、在节点上创建clvm逻辑卷并创建gfs2集群文件系统
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
[root@node1 ~]# pvcreate /dev/mapper/iscsi1 \\将多路冗余设备创建成pvWriting physical volume data to disk "/dev/mapper/iscsi1"Physical volume "/dev/mapper/iscsi1" successfully created[root@node1 ~]# vgcreate cvg0 /dev/mapper/iscsi1 \\创建vgClustered volume group "cvg0" successfully created[root@node1 ~]# lvcreate -L +1G cvg0 -n clv0 \\创建大小为1G的lvLogical volume "clv0" created[root@node1 ~]# lvs \\从node1查看lv情况LV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 -wi-a--- 1.00g[root@node2 ~]# lvs \\从node2查看lv情况LV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 -wi-a--- 1.00g[root@manager ~]# for i in {1..3}; do ssh node$i "lvmconf --enable-cluster"; done \\打开DLM锁机制,在web配置时候,如果勾选了“Enable Shared Storage Support”,则默认就打开了。[root@node2 ~]# mkfs.gfs2 -j 3 -p lock_dlm -t rsyslog:web /dev/cvg0/clv0 \\创建gfs2集群文件系统,并设置节点为3个,锁协议为lock_dlmThis will destroy any data on /dev/cvg0/clv0.It appears to contain: symbolic link to `../dm-1'Are you sure you want to proceed? [y/n] yDevice: /dev/cvg0/clv0Blocksize: 4096Device Size 1.00 GB (262144 blocks)Filesystem Size: 1.00 GB (262142 blocks)Journals: 3Resource Groups: 4Locking Protocol: "lock_dlm"Lock Table: "rsyslog:web"UUID: 7c293387-b59a-1105-cb26-4ffc41b5ae3b |
7、在storage2上创建storage1的mirror,实现备份及高可用
1)、创建跟storage1一样大的iscs空间2G,并配置targets.conf
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
|
[root@storage2 ~]# vim /etc/tgt/targets.conf<target iqn.2013.05.org.rsyslog:storage2.sda5><backing-store /dev/sda5>scsi_id storage2_idscsi_sn storage2_sn</backing-store>incominguser xiaonuo 081ac67e74a6bb13b7a22b8a89e7177binitiator-address 192.168.100.173initiator-address 192.168.100.174initiator-address 192.168.100.175initiator-address 192.168.100.176initiator-address 192.168.200.173initiator-address 192.168.200.174initiator-address 192.168.200.175initiator-address 192.168.200.176</target> |
2)、各节点导入storage1设备
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
|
[root@manager ~]# for i in {1..3}; do ssh node$i "iscsiadm -m discovery -t st -p 192.168.100.172"; done192.168.100.172:3260,1 iqn.2013.05.org.rsyslog:storage2.sda5192.168.100.172:3260,1 iqn.2013.05.org.rsyslog:storage2.sda5192.168.100.172:3260,1 iqn.2013.05.org.rsyslog:storage2.sda5[root@manager ~]# for i in {1..3}; do ssh node$i "iscsiadm -m discovery -t st -p 192.168.200.172"; done192.168.200.172:3260,1 iqn.2013.05.org.rsyslog:storage2.sda5192.168.200.172:3260,1 iqn.2013.05.org.rsyslog:storage2.sda5192.168.200.172:3260,1 iqn.2013.05.org.rsyslog:storage2.sda5[root@manager ~]# for i in {1..3}; do ssh node$i "iscsiadm -m node -l"; doneLogging in to [iface: default, target: iqn.2013.05.org.rsyslog:storage2.sda5, portal: 192.168.100.172,3260] (multiple)Logging in to [iface: default, target: iqn.2013.05.org.rsyslog:storage2.sda5, portal: 192.168.200.172,3260] (multiple)Login to [iface: default, target: iqn.2013.05.org.rsyslog:storage2.sda5, portal: 192.168.100.172,3260] successful.Login to [iface: default, target: iqn.2013.05.org.rsyslog:storage2.sda5, portal: 192.168.200.172,3260] successful.…… |
3)、设置multipath
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
|
[root@node1 ~]# ll /dev/sdsda sda1 sda2 sda3 sdb sdc sdd sde[root@node1 ~]# /sbin/scsi_id -g -u /dev/sdd1storage2_id[root@node1 ~]# /sbin/scsi_id -g -u /dev/sde1storage2_id[root@node1 ~]# vim /etc/multipath.conf \\其它两个节点配置类同multipaths {multipath {wwid 1storage1_idalias iscsi1path_grouping_policy multibuspath_selector "round-robin 0"failback manualrr_weight prioritiesno_path_retry 5}multipath {wwid 1storage2_idalias iscsi2path_grouping_policy multibuspath_selector "round-robin 0"failback manualrr_weight prioritiesno_path_retry 5}}[root@node1 ~]# /etc/rc.d/init.d/multipathd reloadReloading multipathd: [ OK ][root@node1 ~]# multipath -lliscsi2 (1storage2_id) dm-2 IET,VIRTUAL-DISKsize=2.0G features='1 queue_if_no_path' hwhandler='0' wp=rw|-+- policy='round-robin 0' prio=1 status=active| `- 21:0:0:1 sde 8:64 active ready running`-+- policy='round-robin 0' prio=1 status=enabled`- 22:0:0:1 sdd 8:48 active ready runningiscsi1 (1storage1_id) dm-0 IET,VIRTUAL-DISKsize=2.0G features='1 queue_if_no_path' hwhandler='0' wp=rw`-+- policy='round-robin 0' prio=1 status=active|- 20:0:0:1 sdb 8:16 active ready running`- 19:0:0:1 sdc 8:32 active ready running4)、将新的iscsi设备加入卷组cvg0。[root@node3 ~]# pvcreate /dev/mapper/iscsi2Writing physical volume data to disk "/dev/mapper/iscsi2"Physical volume "/dev/mapper/iscsi2" successfully created[root@node3 ~]# vgextend cvg0 /dev/mapper/iscsi2Volume group "cvg0" successfully extended[root@node3 ~]# vgsVG #PV #LV #SN Attr VSize VFreecvg0 2 1 0 wz--nc 4.00g 3.00g |
5)、安装cmirror,并在节点创建stoarge1的mirror为stoarage2
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
|
[root@manager ~]# for i in {1..3}; do ssh node$i "yum install cmirror -y"; done[root@manager ~]# for i in {1..3}; do ssh node$i "/etc/rc.d/init.d/cmirrord start && chkconfig cmirrord on"; done[root@node3 ~]# dmsetup ls –tree \\没有创建mirror之前的状况iscsi2 (253:2)├─ (8:48)└─ (8:64)cvg0-clv0 (253:1)└─iscsi1 (253:0)├─ (8:32)└─ (8:16)[root@node3 ~]# lvs \\没有创建mirror之前的状况LV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 -wi-a--- 1.00g[root@node3 ~]# lvconvert -m 1 /dev/cvg0/clv0 /dev/mapper/iscsi1 /dev/mapper/iscsi2 \\创建先有lv的mirror,以下可以看到数据在复制cvg0/clv0: Converted: 0.4%cvg0/clv0: Converted: 10.9%cvg0/clv0: Converted: 18.4%cvg0/clv0: Converted: 28.1%cvg0/clv0: Converted: 42.6%cvg0/clv0: Converted: 56.6%cvg0/clv0: Converted: 70.3%cvg0/clv0: Converted: 85.9%cvg0/clv0: Converted: 100.0%[root@node2 ~]# lvs \\创建过程中,storage1中的clv0正在想storage2复制相同内容LV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 mwi-a-m- 1.00g clv0_mlog 6.64[root@node2 ~]# lvsLV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 mwi-a-m- 1.00g clv0_mlog 100.00[root@node3 ~]# dmsetup ls –tree \\查看现有iscsi导出设备的状态为mirror型cvg0-clv0 (253:1)├─cvg0-clv0_mimage_1 (253:5)│ └─iscsi2 (253:2)│ ├─ (8:48)│ └─ (8:64)├─cvg0-clv0_mimage_0 (253:4)│ └─iscsi1 (253:0)│ ├─ (8:32)│ └─ (8:16)└─cvg0-clv0_mlog (253:3)└─iscsi2 (253:2)├─ (8:48)└─ (8:64) |
8、集群管理
1)、当基于clvm的gfs2文件系统不够用时,如何增加
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@node3 ~]# lvextend -L +200M /dev/cvg0/clv0Extending 2 mirror images.Extending logical volume clv0 to 1.20 GiBLogical volume clv0 successfully resized[root@node3 ~]# gfs2_grow /opt \\同步文件系统Error: The device has grown by less than one Resource Group (RG).The device grew by 200MB. One RG is 255MB for this file system.gfs2_grow complete.[root@node3 ~]# lvsLV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 mwi-aom- 1.20g clv0_mlog 96.08 |
2)、当节点不够用时,如果添加一个新的节点加入集群
步骤如下:
1>、安装ricci
|
1
|
[root@node4 ~]# yum install ricci -y |
2>、登录luci web,添加ricci
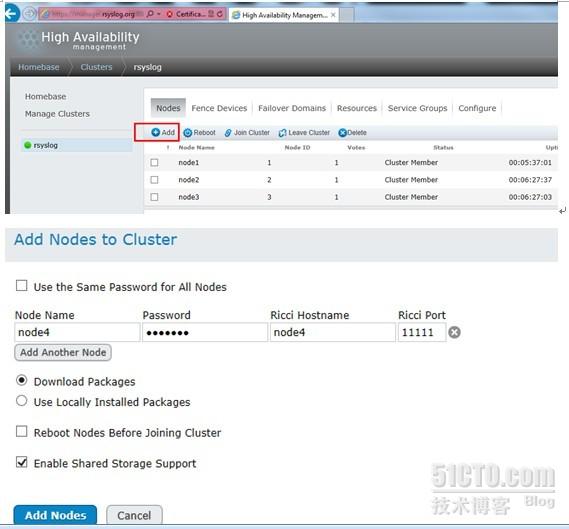
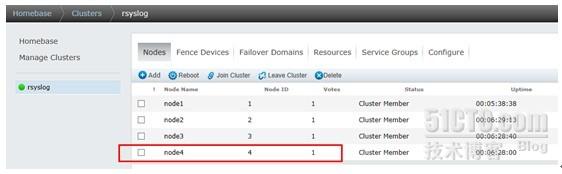
3>、导入共享存储设备
|
1
2
3
4
5
6
|
[root@node4 ~]# iscsiadm -m discovery -t st -p 192.168.100.171[root@node4 ~]# iscsiadm -m discovery -t st -p 192.168.100.172[root@node4 ~]# iscsiadm -m discovery -t st -p 192.168.200.172[root@node4 ~]# iscsiadm -m discovery -t st -p 192.168.200.171[root@node2 ~]# scp /etc/iscsi/iscsid.conf node4:/etc/iscsi/[root@node4 ~]# iscsiadm -m node –l |
4>、设置multipath
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
|
[root@node4 ~]# yum -y install device-mapper-*[root@node4 ~]# mpathconf –enable \\生成配置文件[root@node4 ~]# scp node1:/etc/multipath.conf /etc/ \\也可以直接从其他节点复制过来直接使用[root@node4 ~]# /etc/rc.d/init.d/multipathd start[root@node4 ~]# lvsLV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 mwi---m- 1.20g clv0_mlog[root@node4 ~]# multipath -lliscsi2 (1storage2_id) dm-0 IET,VIRTUAL-DISKsize=2.0G features='1 queue_if_no_path' hwhandler='0' wp=rw`-+- policy='round-robin 0' prio=1 status=active|- 11:0:0:1 sdb 8:16 active ready running`- 12:0:0:1 sdd 8:48 active ready runningiscsi1 (1storage1_id) dm-1 IET,VIRTUAL-DISKsize=2.0G features='1 queue_if_no_path' hwhandler='0' wp=rw`-+- policy='round-robin 0' prio=1 status=active|- 13:0:0:1 sde 8:64 active ready running`- 14:0:0:1 sdc 8:32 active ready running5>、安装cmirror,支持mirror[root@node4 ~]# yum install cmirror –y[root@node4 ~]# /etc/rc.d/init.d/cmirrord start && chkconfig cmirrord on |
6>、在已成功挂载的节点上增加节点数,并实现挂载使用(注意:如果系统看不到/dev/cvg0/clv0,或者通过lvs看不到mirror的copy或者通过dmsetup ls –tree查看不到mirror结构,则重新启动节点系统即可生效)
|
1
2
3
4
5
6
7
8
9
10
11
|
[root@node4 ~]# mount /dev/cvg0/clv0 /opt/ \\节点数不够Too many nodes mounting filesystem, no free journals[root@node2 ~]# gfs2_jadd -j 1 /opt \\增加一个节点数Filesystem: /optOld Journals 3New Journals 4[root@node4 ~]# mount /dev/cvg0/clv0 /opt/[root@node4 ~]# ll /opt/total 4-rw-r--r-- 1 root root 210 Jun 8 00:42 test.txt[root@node4 ~]# |
1、整体测试
1)、测试多路冗余是否OK
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
|
[root@node2 ~]# ifdown eth1 \\关闭某一个网卡,模拟单线路故障[root@node2 ~]# multipath -lliscsi2 (1storage2_id) dm-1 IET,VIRTUAL-DISKsize=2.0G features='1 queue_if_no_path' hwhandler='0' wp=rw`-+- policy='round-robin 0' prio=1 status=active|- 4:0:0:1 sde 8:64 failed faulty running \\导出设备故障`- 3:0:0:1 sdd 8:48 active ready runningiscsi1 (1storage1_id) dm-0 IET,VIRTUAL-DISKsize=2.0G features='1 queue_if_no_path' hwhandler='0' wp=rw`-+- policy='round-robin 0' prio=1 status=active|- 6:0:0:1 sdc 8:32 active ready running`- 5:0:0:1 sdb 8:16 failed faulty running \\导出设备故障[root@node2 opt]# mount | grep opt/dev/mapper/cvg0-clv0 on /opt type gfs2 (rw,relatime,hostdata=jid=0)[root@node2 opt]# touch test \\单线路故障并不影响集群文件系统正常使用[root@node2 ~]# ifup eth1 \\恢复网卡[root@node2 opt]# multipath –ll \\查看多路冗余是否恢复iscsi2 (1storage2_id) dm-1 IET,VIRTUAL-DISKsize=2.0G features='1 queue_if_no_path' hwhandler='0' wp=rw`-+- policy='round-robin 0' prio=1 status=active|- 4:0:0:1 sde 8:64 active ready running`- 3:0:0:1 sdd 8:48 active ready runningiscsi1 (1storage1_id) dm-0 IET,VIRTUAL-DISKsize=2.0G features='1 queue_if_no_path' hwhandler='0' wp=rw`-+- policy='round-robin 0' prio=1 status=active|- 6:0:0:1 sdc 8:32 active ready running`- 5:0:0:1 sdb 8:16 active ready running |
2)、测试基于gfs2文件系统的集群节点是否支持同时读写操作
|
1
2
3
4
5
6
7
8
9
|
[root@manager ~]# for i in {1..3}; do ssh node$i "mount /dev/cvg0/clv0 /opt"; done[root@node1 ~]# while :; do echo node1 >>/opt/test.txt;sleep 1; done \\节点1模拟向test.txt文件写入node1[root@node2 ~]# while :; do echo node2 >>/opt/test.txt;sleep 1; done \\节点2模拟向test.txt文件写入node1[root@node3 ~]# tail -f /opt/test.txt \\节点3模拟读出节点1和节点2同时写入的数据node1node2node1node2……… |
3)、测试Storage损坏一个是否能够正常工作
|
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
|
[root@node1 ~]# lvs \\mirror正常情况下的lvLV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 mwi-a-m- 1.20g clv0_mlog 100.00[root@storage1 ~]# ifdown eth1 && ifdown eth0 \\关闭storage1的两块网卡,相当于storage1宕机[root@node2 opt]# lvs \\ \mirror在storage1宕机正常情况下的lv/dev/mapper/iscsi1: read failed after 0 of 4096 at 2150563840: Input/output error/dev/mapper/iscsi1: read failed after 0 of 4096 at 2150637568: Input/output error/dev/mapper/iscsi1: read failed after 0 of 4096 at 0: Input/output error/dev/mapper/iscsi1: read failed after 0 of 4096 at 4096: Input/output error/dev/sdb: read failed after 0 of 4096 at 0: Input/output error/dev/sdb: read failed after 0 of 4096 at 2150563840: Input/output error/dev/sdb: read failed after 0 of 4096 at 2150637568: Input/output error/dev/sdb: read failed after 0 of 4096 at 4096: Input/output error/dev/sdc: read failed after 0 of 4096 at 0: Input/output error/dev/sdc: read failed after 0 of 4096 at 2150563840: Input/output error/dev/sdc: read failed after 0 of 4096 at 2150637568: Input/output error/dev/sdc: read failed after 0 of 4096 at 4096: Input/output errorCouldn't find device with uuid ziwJmg-Si56-l742-R3Nx-h0rK-KggJ-NdCigs.LV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 -wi-ao-- 1.20g[root@node2 opt]# cp /var/log/messages .\\copy数据到挂载的目录,发现存储宕机一个并不影响读取和写入。[root@node2 opt]# ll messages-rw------- 1 root root 1988955 Jun 8 18:08 messages[root@node2 opt]# dmsetup ls --treecvg0-clv0 (253:5)└─iscsi2 (253:1)├─ (8:48)└─ (8:64)iscsi1 (253:0)├─ (8:16)└─ (8:32)[root@node2 opt]# vgs \\查看vgs情况WARNING: Inconsistent metadata found for VG cvg0 - updating to use version 11Missing device /dev/mapper/iscsi1 reappeared, updating metadata for VG cvg0 to version 11.VG #PV #LV #SN Attr VSize VFreecvg0 2 1 0 wz--nc 4.00g 2.80g[root@node2 opt]# lvconvert -m 1 /dev/cvg0/clv0 /dev/mapper/iscsi1 \\恢复mirrorcvg0/clv0: Converted: 0.0%cvg0/clv0: Converted: 8.5%[root@node1 ~]# lvsLV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 mwi-a-m- 1.20g clv0_mlog 77.45[root@node1 ~]# lvsLV VG Attr LSize Pool Origin Data% Move Log Copy% Convertclv0 cvg0 mwi-a-m- 1.20g clv0_mlog 82.35[root@node1 ~]# dmsetup ls --treecvg0-clv0 (253:5)├─cvg0-clv0_mimage_1 (253:4)│ └─iscsi1 (253:1)│ ├─ (8:64)│ └─ (8:48)├─cvg0-clv0_mimage_0 (253:3)│ └─iscsi2 (253:0)│ ├─ (8:16)│ └─ (8:32)└─cvg0-clv0_mlog (253:2)└─iscsi1 (253:1)├─ (8:64)└─ (8:48)[root@node1 ~]# ll /opt/messages \\可以看到数据还在-rw------- 1 root root 1988955 Jun 8 18:08 /opt/messages |
高可用,多路冗余GFS2集群文件系统搭建详解的更多相关文章
- 全是干货---Linux 高可用(HA)集群基本概念详解
http://www.linuxidc.com/Linux/2013-08/88522.htm 高可用集群的衡量标准 HA(High Available), 高可用性群集是通过系统的可靠性(re ...
- Linux 高可用(HA)集群基本概念详解
大纲一.高可用集群的定义二.高可用集群的衡量标准三.高可用集群的层次结构四.高可用集群的分类 五.高可用集群常用软件六.共享存储七.集群文件系统与集群LVM八.高可用集群的工作原理 推荐阅读: Cen ...
- Linux 高可用(HA)集群之keepalived详解
http://freeloda.blog.51cto.com/2033581/1280962 大纲 一.前言 二.Keepalived 详解 三.环境准备 四.LVS+Keepalived 实现高可用 ...
- LVS负载均衡集群服务搭建详解(一)
LVS概述 1.LVS:Linux Virtual Server 四层交换(路由):根据请求报文的目标IP和目标PORT将其转发至后端主机集群中的某台服务器(根据调度算法): 不能够实现应用层的负载均 ...
- LVS负载均衡集群服务搭建详解(二)
lvs-nat模型构建 1.lvs-nat模型示意图 本次构建的lvs-nat模型的示意图如下,其中所有的服务器和测试客户端均使用VMware虚拟机模拟,所使用的CentOS 7 VS内核都支持ipv ...
- Corosync+Pacemaker+DRBD+MySQL 实现高可用(HA)的MySQL集群
大纲一.前言二.环境准备三.Corosync 安装与配置四.Pacemaker 安装与配置五.DRBD 安装与配置六.MySQL 安装与配置七.crmsh 资源管理 推荐阅读: Linux 高可用(H ...
- 高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南
原文:http://my.oschina.net/wstone/blog/365010#OSC_h3_13 (WJW)高可用,完全分布式Hadoop集群HDFS和MapReduce安装配置指南 [X] ...
- t持久化与集群部署开发详解
Quartz.net持久化与集群部署开发详解 序言 我前边有几篇文章有介绍过quartz的基本使用语法与类库.但是他的执行计划都是被写在本地的xml文件中.无法做集群部署,我让它看起来脆弱不堪,那是我 ...
- hadoop1.2.1+zk-3.4.5+hbase-0.94.1集群安装过程详解
hadoop1.2.1+zk-3.4.5+hbase-0.94.1集群安装过程详解 一,环境: 1,主机规划: 集群中包括3个节点:hadoop01为Master,其余为Salve,节点之间局域网连接 ...
随机推荐
- 保存cookie 到本地
#encoding: utf-8 from urllib import requestfrom http.cookiejar import MozillaCookieJar #创建一个cookieja ...
- webdriervAPI(窗口截图)
from selenium import webdriver driver = webdriver.Chorme() driver.get("http://www.baidu.co ...
- 基于vs插件的abp代码生成器
工作了这么多年,一直都在小公司摸爬滚打,对于小公司而言,开发人员少,代码风格五花八门.要想用更少的人,更快的速度,开发更规范的代码,那自然离不开代码生成器.之前用过动软的,也用过T4,后面又接触了力软 ...
- aliyun挂载oss
配置 oss 挂载 阿里云 ecs 按照ossfs工具:yum install http://gosspublic.alicdn.com/ossfs/ossfs_1.80.5_centos6.5_x8 ...
- "alert(1) to win" writeup
地址:http://escape.alf.nu/ level 0: 注意补全,");alert(1)// level 1: 通过添加反斜线使用来转义的反斜线变为字符,\");ale ...
- Partition to K Equal Sum Subsets
Given an array of integers nums and a positive integer k, find whether it's possible to divide this ...
- Centos 7 下Gitlab 自启动设置
禁止 Gitlab 开机自启动: systemctl disable gitlab-runsvdir.service 启用 Gitlab 开机自启动: systemctl enable gitlab- ...
- 在Ubuntu上安装Spark
1.下载spark2.4.3 使用用户的hadoop的版本,解压并放到/usr/local下并改名为spark目录 2.设置spark目录为本用户所有 3.设置环境变量 (1)#~/.bashrc e ...
- (转)当margin-top、padding-top的值为百分比时是如何计算的?
本文链接:https://blog.csdn.net/qq_27437967/article/details/72625900问题:当margin-top.padding-top的值是百分比时,分别是 ...
- BM求线性递推模板(杜教版)
BM求线性递推模板(杜教版) BM求线性递推是最近了解到的一个黑科技 如果一个数列.其能够通过线性递推而来 例如使用矩阵快速幂优化的 DP 大概都可以丢进去 则使用 BM 即可得到任意 N 项的数列元 ...