Caffe学习系列(21):caffe图形化操作工具digits的安装与运行
经过前面一系列的学习,我们基本上学会了如何在linux下运行caffe程序,也学会了如何用python接口进行数据及参数的可视化。
如果还没有学会的,请自行细细阅读: caffe学习系列:http://www.cnblogs.com/denny402/tag/caffe/
也许有人会觉得比较复杂。确实,对于一个使用惯了windows视窗操作的用户来说,各种命令就要了人命,甚至会非常抵触命令操作。没有学过python,要自己去用python编程实现可视化,也是非常头痛的事情。幸好现在有了nvidia digits这款工具,这些问题都可以解决了。
nvidia为了卖出更多的显卡,对深度学习的偏爱真是亮瞎了狗眼。除了cudnn, 又出了digits,真是希望小学生也能学会深度学习,然后去买他们的卡。
nvidia digits是一款web应用工具,在网页上对caffe进行图形化操作和可视化,用于caffe初学者来说,帮助非常大。
不过有点遗憾的是,据nvidia官方文档称,digits最佳支持系统是ubuntu 14.04,其它的系统效果如何,就不得而知了。
一、安装digits 3.0
digits是运行在cuda和caffe基础上的,所以要先配置好cuda+caffe那是毫无疑问的了。还不会配置的,请参考:Caffe学习系列(1):安装配置ubuntu14.04+cuda7.5+caffe+cudnn
打开一个终端,依次运行下列命令:
cd sudo -s
进入当前用户根目录,并切换到超级用户(符号由$变成#,不用每句都输sudo)
CUDA_REPO_PKG=cuda-repo-ubuntu1404_7.5-18_amd64.deb &&
wget http://developer.download.nvidia.com/compute/cuda/repos/ubuntu1404/x86_64/$CUDA_REPO_PKG &&
sudo dpkg -i $CUDA_REPO_PKG
接着,
ML_REPO_PKG=nvidia-machine-learning-repo_4.0-2_amd64.deb &&
wget http://developer.download.nvidia.com/compute/machine-learning/repos/ubuntu1404/x86_64/$ML_REPO_PKG &&
sudo dpkg -i $ML_REPO_PKG
apt-get update
apt-get install digits
ok,保持网络通畅,慢慢安装吧!
二、运行digits
默认情况下,digits的安装目录为 /usr/share/digits
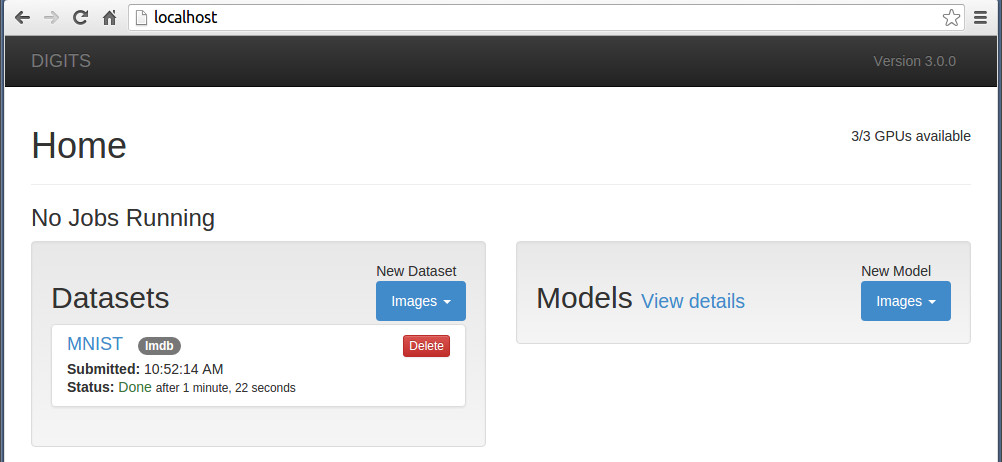
安装完成后,打开浏览器,地址栏输入 http://localhost/ 就可以了,就是这么简单。
更强悍的是:在局域内的其它机子上,也可以用浏览器访问,只是localhost变成了主机 ip地址。很多人喜欢在windows系统上远程连接linux来执行caffe。现在好了,不需要远程连接了,只需要访问一个网站就可以了。。。还有谁!!!!
三、运行mnist实例
现在来运行一个实例:mnist(名符其实的helloworld)
原始数据需要的是图片,但网上提供的mnist数据并不是图片格式的数据,因此我们需要将它转换成图片才能运行。
digits提供了一个脚本文件,用于下载mnist, cifar10 和cifar100 三类数据,并转换成png格式图片。文件路径为:
/usr/share/digits/tools/download_data/main.py
我们先在当前用户的根目录下,新建一个mnist文件夹用来保存mnist图片。
# cd
# mkdir mnist
然后执行脚本
# /usr/share/digits/tools/download_data/main.py mnist ~/mnist
main.py带两个参数,第一个为数据集名称(可设置为mnist, cifar10或cifar100),第二个为输出路径(~/mnist)
执行成功后,会在mnist文件夹下,生成两个文件夹(train文件夹和test文件夹),每个文件夹下面就是我们需要的图片(10类分别放在10个子文件夹内),同时还生成了对应在图片列表文件train.txt和test.txt

接下来,在浏览器上运行digits, 点击左边Dataset模块的"Image"按钮选择“classification", 创建一个dataset
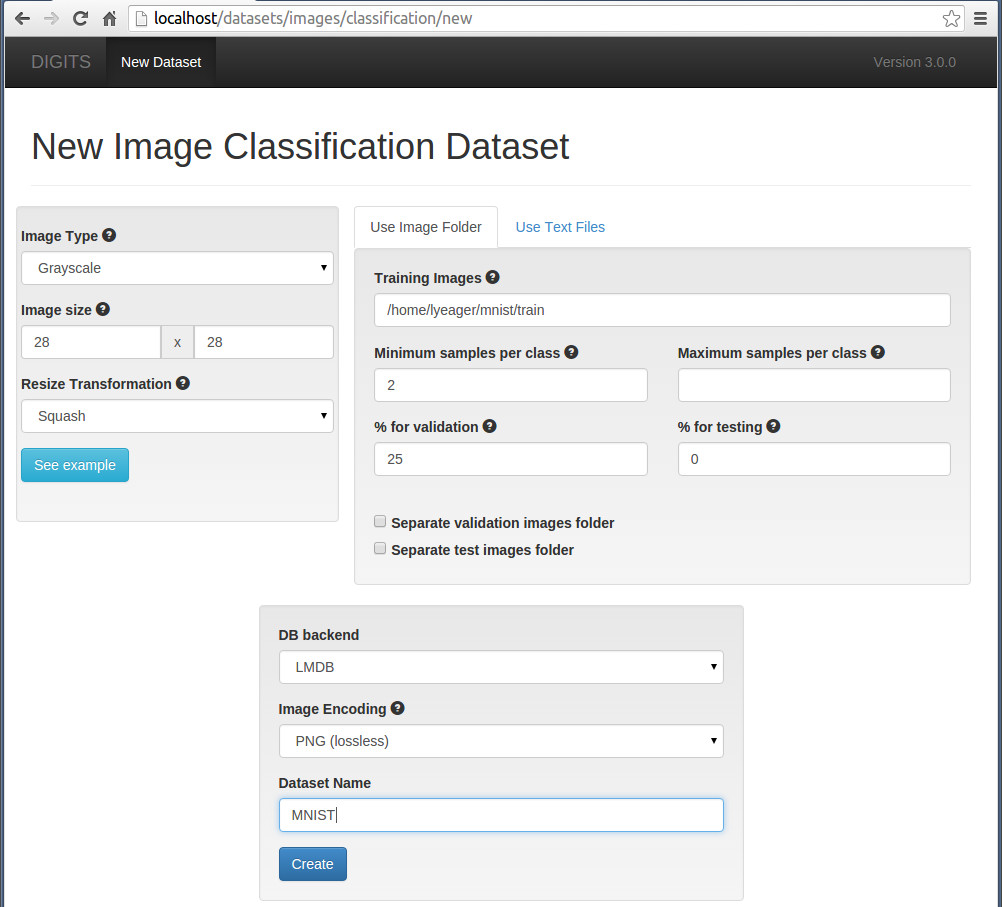
在这个页面的左边,可以设置图片是彩色图片还是灰度图片,如果提供的原始图片大小不一致,还可用Resize Transformation功能转换成一致大小 。从页面中间可以看出,系统默认将训练图片中的25%取出来作为验证集(for validation)。
如果想把用来测试的图片,也生成lmdb, 则把“ separate test image folder" 这个选项选上。
全部设置好后,点击"create" 按钮,开始生成lmdb数据。
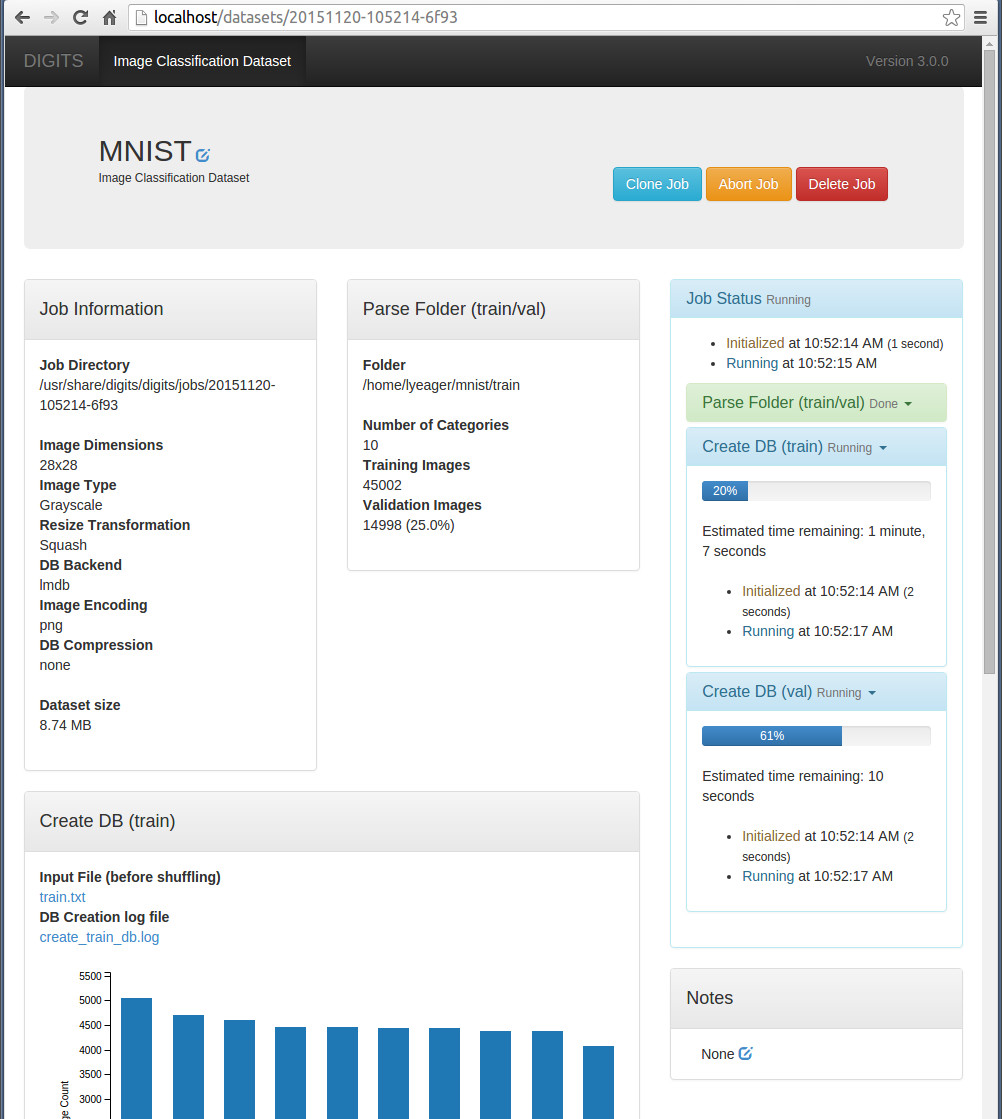
注意左上角的Job Directory(工作目录),生成的lmdb文件就放在这个目录下面,大家最好打开这个目录去看看,看一下生成了些什么文件,了解一下运行原理。
在这个界面,我们还可以可视化查看训练和测试的图片,如下图:
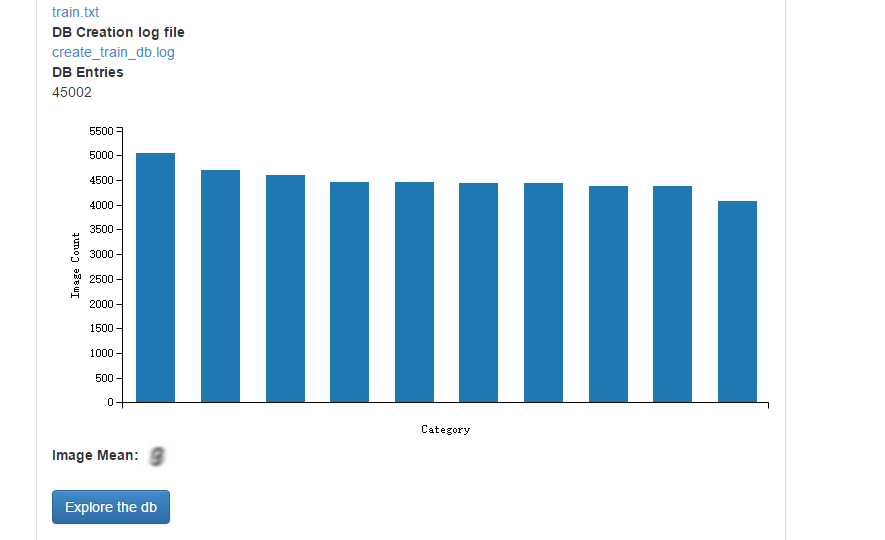
train.txt里面存放的是所有训练图片的列表清单,柱状图清晰地显示了10类样本各自的数量。点击" Explorer the db” 即可查看图片。
最后,点击最左上角“ DIGITS" 链接回到网站根目录。
由于图片太多,因此本文很长,所以在此截断一下,后续。。
Caffe学习系列(21):caffe图形化操作工具digits的安装与运行的更多相关文章
- Caffe学习系列(22):caffe图形化操作工具digits运行实例
上接:Caffe学习系列(21):caffe图形化操作工具digits的安装与运行 经过前面的操作,我们就把数据准备好了. 一.训练一个model 右击右边Models模块的” Images" ...
- Caffe学习系列(23):如何将别人训练好的model用到自己的数据上
caffe团队用imagenet图片进行训练,迭代30多万次,训练出来一个model.这个model将图片分为1000类,应该是目前为止最好的图片分类model了. 假设我现在有一些自己的图片想进行分 ...
- Caffe 学习系列
学习列表: Google protocol buffer在windows下的编译 caffe windows 学习第一步:编译和安装(vs2012+win 64) caffe windows学习:第一 ...
- Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- 转 Caffe学习系列(3):视觉层(Vision Layers)及参数
所有的层都具有的参数,如name, type, bottom, top和transform_param请参看我的前一篇文章:Caffe学习系列(2):数据层及参数 本文只讲解视觉层(Vision La ...
- Caffe学习系列——工具篇:神经网络模型结构可视化
Caffe学习系列——工具篇:神经网络模型结构可视化 在Caffe中,目前有两种可视化prototxt格式网络结构的方法: 使用Netscope在线可视化 使用Caffe提供的draw_net.py ...
- Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- 转 Caffe学习系列(12):训练和测试自己的图片
学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测试模型的整个流程. 一.准备数据 有条件的同学,可以去 ...
- Caffe学习系列(12):训练和测试自己的图片--linux平台
Caffe学习系列(12):训练和测试自己的图片 学习caffe的目的,不是简单的做几个练习,最终还是要用到自己的实际项目或科研中.因此,本文介绍一下,从自己的原始图片到lmdb数据,再到训练和测 ...
随机推荐
- Objective-C之Protocol
*:first-child { margin-top: 0 !important; } body > *:last-child { margin-bottom: 0 !important; } ...
- Monyer's Game 0~5关过关方法
自从Monyer编写了这个通关小游戏,可谓是好事坏事参半吧! 好事是Monyer认识了许多电脑高手,包括netpatch.luoluo等,连LCX这种骨灰级选手也过来了,可谓是收获不小(所以既然我已经 ...
- Effective Java 12 Consider implementing Comparable
Sort array with sorted collection construction. public class WordList { public static void main(Stri ...
- Effective Java 58 Use checked exceptions for recoverable conditions and runtime exceptions for programming errors
Three kinds of throwables Throwables Checked Recoverable checked exceptions Y Y runtime exceptions N ...
- CentOS下搭建SVN服务器
1.安装SVN SVN数据存储有两种方式,BDB(事务安全表类型)和FSFS(一种不需要数据库的存储系统),为了避免在服务器连接中断时锁住数据,FSFS是一种更安全也更多人使用的方式.SVN的运行方式 ...
- MongoDB(一)
问题解决 1.由于目标计算机积极拒绝 无法连接 原因:还没有启动mongodb,就使用mongo命令 解决方法:在bin目录下输入 mongod --dbpath XXXX/data 然后在输入 mo ...
- IE6/7/8不支持jQuery创建非闭合格式的链接A
代码如下 <!DOCTYPE html> <html> <head> <meta charset="utf-8"> <scri ...
- Mac OS X 快捷键
启动快捷键 按下按键或组合键,直到所需的功能出现(例如,在启动过程中按住 Option 直到出现“启动管理程序”,或按住 Shift 直到出现“安全启动”).提示:如果启动功能未起作用,而您使用的是第 ...
- C++ new(3)
转载自:http://www.builder.com.cn/2008/0104/696370.shtml “new”是C++的一个关键字,同时也是操作符.关于new的话题非常多,因为它确实比较复杂,也 ...
- TEZ安装试用
下载地址:http://pan.baidu.com/s/1ZNpyI 第一次使用maven编译 tez的时候到tez ui部分报错,google后发现有人遇到类似问题是因为maven版本的问题, 当时 ...