lucene索引
一、lucene索引
1、文档层次结构
- 索引(Index):一个索引放在一个文件夹中;
- 段(Segment):一个索引中可以有很多段,段与段之间是独立的,添加新的文档可能产生新段,不同的段可以合并成一个新段;
- 文档(Document):文档是创建索引的基本单位,不同的文档保存在不同的段中,一个段可以包含多个文档;
- 域(Field):一个文档包含不同类型的信息,可以拆分开索引;
- 词(Term):词是索引的最小单位,是经过词法分析和语言处理后的数据;
文档是Lucene索引和搜索的原子单位,文档为包含一个或多个域的容器,而域则依次包含“真正的”被搜索内容,域值通过分词技术处理,得到多个词元。如一篇小说信息可以称为一个文档;小说信息又包含多个域,比如标题,作者、简介、最后更新时间等;对标题这一个域采用分词技术,又可以等到一个或多个词元。
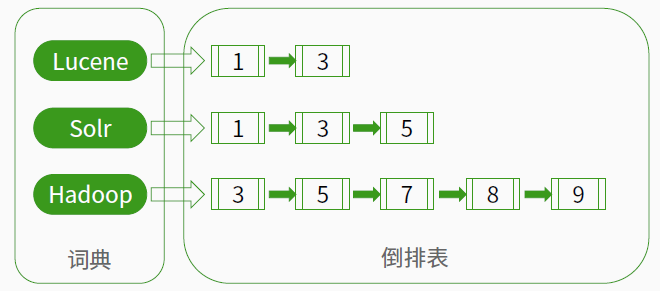
2、正向索引与反向索引
- 正向索引:文档占据了中心的位置,每个文档指向了一个它所包含的索引项的序列。正向信息就是按层次保存了索引一直到词的包含关系: 索引 -> 段-> 文档 -> 域 -> 词
- 反向索引:一种以索引项为中心来组织文档的方式,每个索引项指向一个文档序列,这个序列中的文档都包含该索引项。反向信息保存了词典的倒排表映射:词 -> 文档
lucene使用到的就是反向索引。如下图所示:
二、索引操作
相关示例如下:
package com.test.lucene; import java.io.IOException;
import java.nio.file.Paths; import org.apache.lucene.analysis.Analyzer;
import org.apache.lucene.analysis.cn.smart.SmartChineseAnalyzer;
import org.apache.lucene.document.Document;
import org.apache.lucene.document.Field.Store;
import org.apache.lucene.document.IntField;
import org.apache.lucene.document.StringField;
import org.apache.lucene.document.TextField;
import org.apache.lucene.index.DirectoryReader;
import org.apache.lucene.index.IndexWriter;
import org.apache.lucene.index.IndexWriterConfig;
import org.apache.lucene.index.Term;
import org.apache.lucene.index.IndexWriterConfig.OpenMode;
import org.apache.lucene.queryparser.classic.ParseException;
import org.apache.lucene.queryparser.classic.QueryParser;
import org.apache.lucene.search.IndexSearcher;
import org.apache.lucene.search.Query;
import org.apache.lucene.search.TopDocs;
import org.apache.lucene.store.Directory;
import org.apache.lucene.store.FSDirectory; /**
* 索引增删改查
*/
public class IndexTest {
/**
* 创建索引
*
* @param path
* 索引存放路径
*/
public static void create(String path) {
System.out.println("创建开始=============================》");
Analyzer analyzer = new SmartChineseAnalyzer();// 指定分词技术,这里使用的是中文分词 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// indexWriter的配置信息 indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); // 索引的打开方式:没有则创建,有则打开 Directory directory = null;
IndexWriter indexWriter = null;
// 文档一
Document doc1 = new Document();
doc1.add(new StringField("id", "1111", Store.YES));
doc1.add(new TextField("content", "中国广州", Store.YES));
doc1.add(new IntField("num", 1, Store.YES)); // 文档二
Document doc2 = new Document();
doc2.add(new StringField("id", "2222", Store.YES));
doc2.add(new TextField("content", "中国上海", Store.YES));
doc2.add(new IntField("num", 2, Store.YES)); try {
directory = FSDirectory.open(Paths.get(path));// 索引在硬盘上的存储路径
indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriter.addDocument(doc1);
indexWriter.addDocument(doc2);
// 将indexWrite操作提交,如果不提交,之前的操作将不会保存到硬盘
// 但是这一步很消耗系统资源,索引执行该操作需要有一定的策略
indexWriter.commit();
} catch (IOException e) {
e.printStackTrace();
} finally { // 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("创建索引完成=================================");
} /**
* 添加索引
*
* @param path
* 索引存放路径
* @param document
* 添加的文档
*/
public static void add(String path, Document document) {
System.out.println("增加索引开始=============================》");
Analyzer analyzer = new SmartChineseAnalyzer();// 指定分词技术,这里使用的是中文分词 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// indexWriter的配置信息 indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); // 索引的打开方式:没有则创建,有则打开
Directory directory = null;
IndexWriter indexWriter = null;
try {
directory = FSDirectory.open(Paths.get(path));// 索引在硬盘上的存储路径 indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriter.addDocument(document);
indexWriter.commit();
} catch (IOException e) {
e.printStackTrace();
} finally { // 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("增加索引完成=================================");
} /**
* 删除索引
*
* @param indexpath
* 索引存放路径
* @param id
* 文档id
*/
public static void delete(String indexpath, String id) {
System.out.println("删除索引开始=============================》");
Analyzer analyzer = new SmartChineseAnalyzer();// 指定分词技术,这里使用的是中文分词 IndexWriterConfig indexWriterConfig = new IndexWriterConfig(analyzer);// indexWriter的配置信息 indexWriterConfig.setOpenMode(OpenMode.CREATE_OR_APPEND); // 索引的打开方式:没有则创建,有则打开
IndexWriter indexWriter = null;
Directory directory = null;
try {
directory = FSDirectory.open(Paths.get(indexpath));// 索引在硬盘上的存储路径
indexWriter = new IndexWriter(directory, indexWriterConfig);
indexWriter.deleteDocuments(new Term("id", id));// 删除索引操作
} catch (IOException e) {
e.printStackTrace();
} finally { // 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("删除索引完成=================================");
} /**
* Lucene没有真正的更新操作,通过某个fieldname,可以更新这个域对应的索引,但是实质上,它是先删除索引,再重新建立的。
*
* @param indexpath
* 索引存放路径
* @param newDoc
* 更新后的文档
* @param oldDoc
* 需要更新的目标文档
*/
public static void update(String indexpath, Document newDoc, Document oldDoc) {
System.out.println("更新索引开始=============================》");
Analyzer analyzer = new SmartChineseAnalyzer();
IndexWriterConfig config = new IndexWriterConfig(analyzer);
config.setOpenMode(OpenMode.CREATE_OR_APPEND);
IndexWriter indexWriter = null;
Directory directory = null;
try {
directory = FSDirectory.open(Paths.get(indexpath));
indexWriter = new IndexWriter(directory, config);
indexWriter.updateDocument(new Term("id", oldDoc.get("id")), newDoc);
} catch (IOException e) {
e.printStackTrace();
} finally { // 关闭资源
try {
indexWriter.close();
directory.close();
} catch (IOException e) {
e.printStackTrace();
}
}
System.out.println("更新索引完成=================================");
} /**
* 搜索
*
* @param keyword
* 关键字
* @param indexpath
* 索引存放路径
*/
public static void search(String keyword, String indexpath) {
Directory directory = null;
try {
directory = FSDirectory.open(Paths.get(indexpath));// 索引硬盘存储路径 DirectoryReader directoryReader = DirectoryReader.open(directory);// 读取索引 IndexSearcher searcher = new IndexSearcher(directoryReader);// 创建索引检索对象 Analyzer analyzer = new SmartChineseAnalyzer();// 分词技术 QueryParser parser = new QueryParser("content", analyzer);// 创建Query
Query query = parser.parse(keyword);// 查询content为广州的
// 检索索引,获取符合条件的前10条记录
TopDocs topDocs = searcher.search(query, 10);
if (topDocs != null) {
System.out.println("符合条件的记录为: " + topDocs.totalHits);
for (int i = 0; i < topDocs.scoreDocs.length; i++) {
Document doc = searcher.doc(topDocs.scoreDocs[i].doc);
System.out.println("id = " + doc.get("id"));
System.out.println("content = " + doc.get("content"));
System.out.println("num = " + doc.get("num"));
}
}
directory.close();
directoryReader.close();
} catch (IOException e) {
e.printStackTrace();
} catch (ParseException e) {
e.printStackTrace();
}
}
/**
* 测试代码
* @param args
*/
public static void main(String[] args) {
String indexpath = "D://index/test";
create(indexpath);// 创建索引
search("广州", indexpath);
Document doc = new Document();
doc.add(new StringField("id", "3333", Store.YES));
doc.add(new TextField("content", "中国北京广州", Store.YES));
doc.add(new IntField("num", 2, Store.YES));
add(indexpath, doc);// 添加索引
search("广州", indexpath);
Document newDoc = new Document();
newDoc.add(new StringField("id", "3333", Store.YES));
newDoc.add(new TextField("content", "中国北京广州我的顶顶顶顶顶顶顶顶顶顶顶顶", Store.YES));
newDoc.add(new IntField("num", 3, Store.YES));
update(indexpath, newDoc, doc);// 更新索引
search("广州", indexpath);
delete(indexpath, "3333");// 删除索引
search("广州", indexpath);
}
}
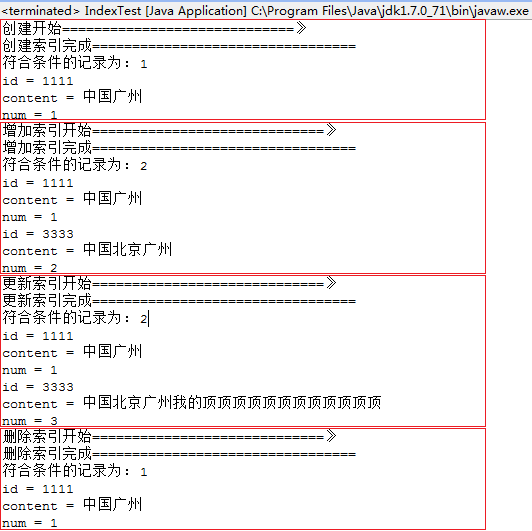
运行结果如下:
lucene索引的更多相关文章
- MySQL和Lucene索引对比分析
MySQL和Lucene都可以对数据构建索引并通过索引查询数据,一个是关系型数据库,一个是构建搜索引擎(Solr.ElasticSearch)的核心类库.两者的索引(index)有什么区别呢?以前写过 ...
- Lucene索引文件学习
最近在做搜索,抽空看一下lucene,资料挺多的,不过大部分都是3.x了--在对着官方文档大概看一下. 优化后的lucene索引文件(4.9.0) 一.段文件 1.段文件:segments_5p和s ...
- lucene 索引合并策略
在索引算法确定的情况下,最为影响Lucene索引速度有三个参数--IndexWriter中的 MergeFactor, MaxMergeDocs, RAMBufferSizeMB .这些参数无非是控制 ...
- Lucene学习笔记: 四,Lucene索引过程分析
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- Lucene 索引功能
Lucene 数据建模 基本概念 文档(doc): 文档是 Lucene 索引和搜索的原子单元,文档是一个包含多个域的容器. 域(field): 域包含“真正的”被搜索的内容,每一个域都有一个标识名称 ...
- Lucene学习总结之四:Lucene索引过程分析
对于Lucene的索引过程,除了将词(Term)写入倒排表并最终写入Lucene的索引文件外,还包括分词(Analyzer)和合并段(merge segments)的过程,本次不包括这两部分,将在以后 ...
- lucene 索引查看工具
luke 是 lucene 索引查看工具,基于 swing 开发的,是 lucene.solr.nutch 开发过程中不可或缺的工具.在测试搜索过程,进程出现搜不到东西或者搜到的东西不是想要的结果时, ...
- 深入Lucene索引机制
Lucene的索引里面存了些什么,如何存放的,也即Lucene的索引文件格式,是读懂Lucene源代码的一把钥匙. 当我们真正进入到Lucene源代码之中的时候,我们会发现: Lucene的索引过程, ...
- Lucene系列五:Lucene索引详解(IndexWriter详解、Document详解、索引更新)
一.IndexWriter详解 问题1:索引创建过程完成什么事? 分词.存储到反向索引中 1. 回顾Lucene架构图: 介绍我们编写的应用程序要完成数据的收集,再将数据以document的形式用lu ...
随机推荐
- BZOJ1008 /乘法原理+快速幂 解题报告
1008: [HNOI2008]越狱 Description 监狱有连续编号为1...N的N个房间,每个房间关押一个犯人,有M种宗教,每个犯人可能信仰其中一种.如果相邻房间的犯人的宗教相同,就可能发生 ...
- Linux永久修改系统时间和时区方法
修改时区: 1> 找到相应的时区文件 /usr/share/zoneinfo/Asia/Shanghai 用这个文件替换当前的/etc/localtime文件. 或者找你认为是标准时间的服务器, ...
- [Latex]实现行内高亮
Latex的行内高亮 前两天想要在做的小操作系统实验指导书里使用行内高亮,一开始虽然有命令 \mint{Language}|contents| 但是无奈只能实现跳行高亮,即不能实现行内高亮.即代码高亮 ...
- eclipse中去掉Js/javsscript报错信息
1.首先在problem>errors中删除所有js错误: 如下图 2.然后再勾选掉javascript Validator: 3.clean下项目吧,你会发现再也不出现js红叉叉了,哈哈.
- C# 泛型简介
摘要:本文讨论泛型处理的问题空间.它们的实现方式.该编程模型的好处,以及独特的创新(例如,约束.一般方法和委托以及一般继承).此外,本文还讨论 .NET Framework 如何利用泛型. 下载 Ge ...
- Can you explain Lazy Loading?
Introduction Lazy loading is a concept where we delay the loading of the object until the point wher ...
- 10个出色的NoSQL数据库
http://www.infoq.com/research/nosql-databases?utm_source=infoqresearch&utm_campaign=lr-homepage ...
- 重大发现Discuz DB层跨库映射关系表名前缀BUG
本文更新:http://www.cnblogs.com/x3d/p/3916198.html 场景: 在Discuz中创建Table模型,但该Table所在库与Discuz不在同一个库. Discuz ...
- java之AbstractStringBuilder类详解
目录 AbstractStringBuilder类 字段 构造器 方法 public abstract String toString() 扩充容量 void expandCapacity(in ...
- DP入门---Robberies
HDU 2955 Description The aspiring Roy the Robber has seen a lot of American movies, and knows that ...