Storm概念学习系列 之数据流模型、Storm数据流模型
不多说,直接上干货!
数据流模型
数据流模型是由数据流、数据处理任务、数据节点、数据处理任务实例等构成的一种数据模型。本节将介绍的数据流模型如图1所示。
分布式流处理系统由多个数据处理节点(node)组成,每个数据处理节点上运行有多个数据任务实例,每个数据任务实例属于一个数据任务定义。任务实例是在任务定义的基础上,添加了输入流过滤条件和强制输出周期属性后,可实际推送到数据处理节点上运行的逻辑实体;数据任务定义包含输入数据流、数据处理逻辑和输出数据流属性。
数据流模型简介
首先介绍数据流模型中的一些重要概念。
1. 数据流
数据流是时间分布和数量上无限的一系列数据记录的集合体。数据记录是数据流的最小组成单元,每条数据记录包括三类数据:数据流名称(stream name)、标识数据(key)和具体数据处理逻辑所需的数据(value)。

图1 数据流处理流程图
2. 定义数据处理任务
定义数据处理任务只是定义一个数据处理任务的基本属性,任务还无法直接执行,必须将其实现为具体的任务实例。数据处理任务的基本属性包括输入流、输出流和数据处理逻辑。
(1)输入流(可选)
输入流描述该任务依赖哪些数据流作为输入,是一个数据流名称列表;数据流产生源不会依赖其他数据流,可忽略该配置。
(2)输出流(可选)
输出流描述该任务产生哪个数据流,是一个数据流名称;数据流处理链末级任务不会产生新的数据流,可忽略该配置。
(3)数据处理逻辑
数据处理逻辑描述该任务具体的处理逻辑,如由独立进程执行的外部处理逻辑。
3. 数据处理节点
数据处理节点是可容纳多个数据处理任务实例运行的实体机器,每个数据处理节点的IPv4地址必须保证唯一。
4. 数据处理任务实例
对一个数据处理任务定义进行具体约束后,可将其推送到某个处理节点上运行具体的逻辑实体。数据处理任务基本属性包括数据处理任务定义、输入流过滤条件、强制输出周期,下面进行具体介绍。
(1)数据处理任务定义
数据处理任务定义指向该任务实例对应的数据处理任务定义实体。
(2)输入流过滤条件
输入流过滤条件是一个布尔类型表达式列表,描述每个输入流中符合什么条件的数据记录可以作为有效数据交给处理逻辑。若某个输入流中所有数据记录都是有效数据,则可直接用true表示。
(3)强制输出周期(可选)
强制输出周期描述以什么频率强制该任务实例产生输出流记录,可以用输入流记录数或间隔时间作为周期。如果忽略该配置,则输出流记录产生周期完全由处理逻辑自身决定,不受框架约束。
Storm数据流模型
数据流(Stream)是Storm中对数据进行的抽象,它是时间上无界的Tuple元组序列。在Topology中,Spout是Stream的源头,负责为Topology从特定数据源发射Stream(Spout并不需要接收流,只会发射流);Bolt可以接收任意多个流作为输入,然后进行数据的加工处理过程,如果需要,Bolt还可以发射出新的流给下级Bolt处理。Topology内部Spout和Bolt之间的数据流关系图如图2所示。
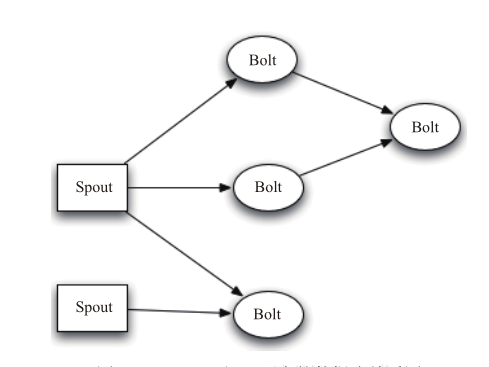
图2 Spout和Bolt中的数据流关系图
Topology中每一个计算组件(Spout和Bolt)都有一个并行执行度(Task),在创建Topology时可以指定,Storm会在集群内分配对应并行度个数的线程来同时执行这一组件。Storm提供了若干种数据流分发(Stream Grouping)策略来解决在两个组件(Spout和Bolt)之间发送Tuple。在定义Topology时,需要为每个Bolt指定接收什么样的流作为其输入。
Storm概念学习系列 之数据流模型、Storm数据流模型的更多相关文章
- Storm概念学习系列之核心概念(Tuple、Spout、Blot、Stream、Stream Grouping、Worker、Task、Executor、Topology)(博主推荐)
不多说,直接上干货! 以下都是非常重要的storm概念知识. (Tuple元组数据载体 .Spout数据源.Blot消息处理者.Stream消息流 和 Stream Grouping 消息流组.Wor ...
- Storm概念学习系列之storm流程图
把stream当做一列火车, tuple当做车厢,spout当做始发站,bolt当做是中间站点!!! 见 Storm概念学习系列之Spout数据源 Storm概念学习系列之Topology拓扑 Sto ...
- Storm概念学习系列之Worker、Task、Executor三者之间的关系
不多说,直接上干货! Worker.Task.Executor三者之间的关系 Storm集群中的一个物理节点启动一个或者多个Worker进程,集群的Topology都是通过这些Worker进程运行的. ...
- Storm概念学习系列之storm的雪崩
不多说,直接上干货! Storm的雪崩问题的解决办法1: Storm概念学习系列之并行度与如何提高storm的并行度 Storm的雪崩问题的解决办法2:
- Storm概念学习系列之storm的特性
不多说,直接上干货! storm的特性 Storm 是一个开源的分布式实时计算系统,可以简单.可靠地处理大量的数据流. Storm支持水平扩展,具有高容错性,保证每个消息都会得到处理,而且处理速度很快 ...
- Storm概念学习系列之Tuple元组(数据载体)
不多说,直接上干货! Tuple元组 Tuple 是 Storm 的主要数据结构,并且是 Storm 中使用的最基本单元.数据模型和元组. Tuple 描述 Tuple 就是一个值列表, Tuple ...
- Storm概念学习系列之并行度与如何提高storm的并行度
不多说,直接上干货! 对于storm来说,并行度的概念非常重要!大家一定要好好理解和消化. storm的并行度,可以简单的理解为多线程. 如何提高storm的并行度? storm程序主要由spout和 ...
- Storm概念学习系列之storm核心组件
不多说,直接上干货! Storm核心组件 了解 Storm 的核心组件对于理解 Storm 原理非常重要,下面介绍 Storm 的整体,然后介绍 Storm 的核心. Storm 集群由一个主节点和多 ...
- Storm概念学习系列之storm-starter项目(完整版)(博主推荐)
不多说,直接上干货! 这是书籍<从零开始学Storm>赵必厦 2014年出版的配套代码! storm-starter项目包含使用storm的各种各样的例子.项目托管在GitHub上面,其网 ...
随机推荐
- Poj1218_THE DRUNK JAILER(水题)
一.Description A certain prison contains a long hall of n cells, each right next to each other. Each ...
- Python:map()、reduce()、filter()的区别
文章转于:https://blog.csdn.net/goupper1991/article/details/49803355 原文博主:https://blog.csdn.net/goupper19 ...
- java web项目创建
https://www.cnblogs.com/kangjianwei101/p/5621738.html
- CentOS安装配置radius服务器
1.安装 Yum install -y freeradius freeradius-mysql freeradius-utils 2.配置 1)修改 clients.conf # vi /usr/lo ...
- 测试RDP回放
Dim fso,num,flagflag=trueset bag=getobject("winmgmts:\\.\root\cimv2") Set fso=CreateObject ...
- NET项目中分页方法
/// <summary> /// 获得查询分页数据 /// </summary> public DataSet GetList(int pageSize, int pageI ...
- shell 自动删除n天前备份
Linux自动删除n天前备份Linux是一个很能自动产生文件的系统,日志.邮件.备份等.因此需要设置让系统定时清理一些不需要的文件.语句写法: find 对应目录 -mtime +天数 -na ...
- 21 、GPD-PSL-VCF
https://genome.ucsc.edu/FAQ/FAQformat.html#format9 1.Variant Call Format(VCF) Example ##fileformat=V ...
- ascII、iso、utf-8、Unicode的区别
utf-8和Unicode到底有什么区别?是存储方式不同?编码方式不同?它们看起来似乎很相似,但是实际上他们并不是同一个层次的概念,utf-8是unicode的实现方式. 要想先讲清楚他们的区别,首先 ...
- jzoj3208. 【JSOI2013】编程作业(kmp)
题面 Description Will相信,很多同学都有过这样的经历:大牛已经写好了编程作业,而作为菜鸟的自己不会写怎么办呢?拿大牛的代码抄一下嘛!但是提交一模一样的作业是不是不太好?于是就改一改变量 ...