python模块, 包的初识
Python 模块(Module),
是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义和Python语句。
模块让你能够有逻辑地组织你的 Python 代码段。
把相关的代码分配到一个模块里能让你的代码更好用,更易懂。
模块能定义函数,类和变量,模块里也能包含可执行的代码。
模块主要分为:
1, 内置的
2, 扩展的/ 第三方的
3, 自定义的 py文件
自定义模块时, 文件名的明明要求和变量名的规范一样
注意:
1, 导入模块时, 一般用 import 文件名(即模块名) 或者 form 模块 import XXX
* 导入模块(无论是用‘import 模块’还是用‘from 模块 import xxx)本质就是除if__name__=’__main’代码外,把该模块里的所有内容从头到尾执行一遍。
2, 模块不会被多次重复导入,一般只会导入一次
3, 模块的导入相当于执行包含模块的这个文件
4, 模块拥有自己独立的命名空间
5, 在导入模块的时候可以对导入的模块进行重命名(import sys as i
[即 在当前的代码运行时,调用模块的名字是i, 而不再是sys, 但是原sys模块名不变]),
6, 在导入多个模块的时候,
(1) 一行导入多个模块 , 用逗号隔开. 此方法在实际编程的时候不建议使用.
(2) 多行导入多个的时候导入顺序: 以内置>>>第三方>>>自定义的顺序进行导入.
# 在模块的导入中 不要产生循环引用问题
# 如果发生循环导入了
# 就会发现明明写在这个模块中的方法,确偏显示找不到
☆ import 导入:
模板的引入.模块定义好后,可以用import语句来引入模块:
首先定义一个叫my_module.py的模块.
name = 'www'
def login():
print('login',name)
格式为:
import 模块名例如: import my_module
而当调用模块中的函数时,
模块名.函数名(my_module.func)则调用为:
my_module.login =====> login www
注:
模块在没被导入的时候存储在硬盘上.
当解释器遇到import语句的时候,如果模块在当前的搜索路径就会被导入.
搜索路径时.
from 模块名 import XXX(函数名)
1, 其过程仍然相当于执行了整个的模块.
2, 导入了什么就能使用什么,不导入的变量不能使用
不导入并不意味着不存而是没有建立文件到模块中其他名字的引用
from 模块名 import * (原理跟from 模块名 import 函数名 基本一样,
这里是把模块中的所有函数全部导入到当前的命名空间中.)
这种导入方法可以一次导入多个函数,并且能进行重命名.
例如: 一次导入多个 : from my_module import login,name
进行重命名 : from my_module import login as m,name as l
总结:
1, 导入了什么 就能使用什么 不导入的变量 不能使用
2, 不导入并不意味着不存 而是没有建立文件到模块中其他名字的引用3, 当模块中导入的方法或者变量 和 本文件重名的时候,那么这个名字只代表最后一次对它赋值的哪个方法或者变量
在本文件中对全局变量的修改是完全不会影响到模块中的变量引用的
模块编写以及使用规范:
运行一个py文件的两种方法:
1, 以模块的形式运行
import my_module
if __name__ == '__main__':
my_module.login()
2, 直接pucharm 运行 cmd运行
---------以脚本的形式运行
(需要在本文件中直接打印的代码上加上 if __name__ == '__main__' )
在编写py文件的时候,所有不在函数和类中封装的内容都应该写在
if __name__ == '__main__' : 下面.
例如:
def login():
print('login',name)
if __name__ == '__main__':
print('饿了么')
print(__name__,type(__name__))
模块搜索路径:
# 模块的搜索路径全部存储在sys.path列表中
# 导入模块的顺序,是从前到后找到一个符合条件的模块就立即停止不再向后寻找
# 如果要导入的模块和当前执行的文件同级
# 直接导入即可
# 如果要导入的模块和当前执行的文件不同级
# 需要把要导入模块的绝对路径添加到sys.path列表中
补充:
import aaa
import time
import importlib
aaa.login()
time.sleep(20)
importlib.reload(aaa) # 表示重新加载
aaa.login()# 在import之后 再修改这个被导入的模块
# 程序感知不到# reload这种方式可以强制程序再重新导入这个模块一次
# 非常不推荐你使用# 在模块的导入中 不要产生循环引用问题
# 如果发生循环导入了
# 就会发现明明写在这个模块中的方法,确偏显示找不到
python中的包:
包是一个分层次的文件目录结构,它定义了一个由模块及子包,和子包下的子包等组成的 Python 的应用环境。
简单来说,包就是文件夹,但该文件夹下必须存在 __init__.py 文件, 该文件的内容可以为空。__init__.py 用于标识当前文件夹是一个包。
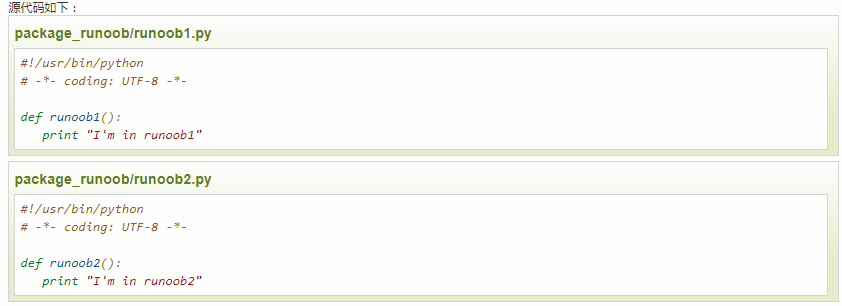
考虑一个在 package_runoob 目录下的 runoob1.py、runoob2.py、__init__.py 文件,test.py 为测试调用包的代码,目录结构如下:
PYTHONPATH 变量
作为环境变量,PYTHONPATH 由装在一个列表里的许多目录组成。PYTHONPATH 的语法和 shell 变量 PATH 的一样。
在 Windows 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=c:\python27\lib;在 UNIX 系统,典型的 PYTHONPATH 如下:
set PYTHONPATH=/usr/local/lib/python
命名空间和作用域
变量是拥有匹配对象的名字(标识符)。命名空间是一个包含了变量名称们(键)和它们各自相应的对象们(值)的字典。
一个 Python 表达式可以访问局部命名空间和全局命名空间里的变量。如果一个局部变量和一个全局变量重名,则局部变量会覆盖全局变量。
每个函数都有自己的命名空间。类的方法的作用域规则和通常函数的一样。
Python 会智能地猜测一个变量是局部的还是全局的,它假设任何在函数内赋值的变量都是局部的。
因此,如果要给函数内的全局变量赋值,必须使用 global 语句。
global VarName 的表达式会告诉 Python, VarName 是一个全局变量,这样 Python 就不会在局部命名空间里寻找这个变量了。
例如,我们在全局命名空间里定义一个变量 Money。我们再在函数内给变量 Money 赋值,然后 Python 会假定 Money 是一个局部变量。然而,我们并没有在访问前声明一个局部变量 Money,结果就是会出现一个 UnboundLocalError 的错误。取消 global 语句的注释就能解决这个问题。
#!/usr/bin/python
# -*- coding: UTF-8 -*- Money = 2000
def AddMoney():
# 想改正代码就取消以下注释:
# global Money
Money = Money + 1 print Money
AddMoney()
print Money
dir()函数
dir() 函数一个排好序的字符串列表,内容是一个模块里定义过的名字。
返回的列表容纳了在一个模块里定义的所有模块,变量和函数。如下一个简单的实例:
#!/usr/bin/python
# -*- coding: UTF-8 -*- # 导入内置math模块
import math content = dir(math) print content;以上实例输出结果:
['__doc__', '__file__', '__name__', 'acos', 'asin', 'atan',
'atan2', 'ceil', 'cos', 'cosh', 'degrees', 'e', 'exp',
'fabs', 'floor', 'fmod', 'frexp', 'hypot', 'ldexp', 'log',
'log10', 'modf', 'pi', 'pow', 'radians', 'sin', 'sinh',
'sqrt', 'tan', 'tanh']在这里,特殊字符串变量__name__指向模块的名字,__file__指向该模块的导入文件名。
globals() 和 locals() 函数
根据调用地方的不同,globals() 和 locals() 函数可被用来返回全局和局部命名空间里的名字。
如果在函数内部调用 locals(),返回的是所有能在该函数里访问的命名。
如果在函数内部调用 globals(),返回的是所有在该函数里能访问的全局名字。
两个函数的返回类型都是字典。所以名字们能用 keys() 函数摘取。
reload() 函数
当一个模块被导入到一个脚本,模块顶层部分的代码只会被执行一次。
因此,如果你想重新执行模块里顶层部分的代码,可以用 reload() 函数。该函数会重新导入之前导入过的模块。语法如下:
reload(module_name)在这里,module_name要直接放模块的名字,而不是一个字符串形式。比如想重载 hello 模块,如下:
reload(hello)
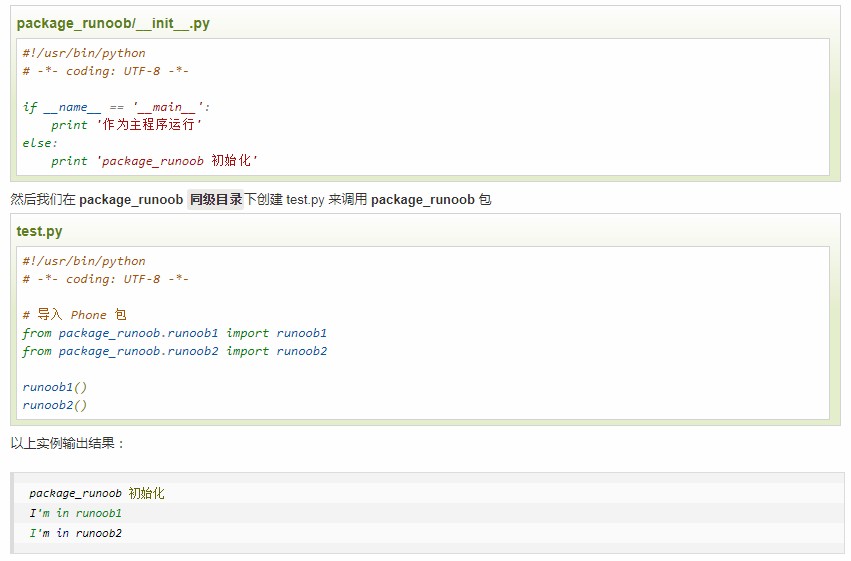
如上,为了举例,我们只在每个文件里放置了一个函数,但其实你可以放置许多函数。你也可以在这些文件里定义Python的类,然后为这些类建一个包。
python模块, 包的初识的更多相关文章
- (转载)Linux平台下安装 python 模块包
https://blog.csdn.net/aiwangtingyun/article/details/79121145 一.安装Python Windows平台下: 进入Python官网下载页面下载 ...
- 羞羞的Python模块包
目录 一.pip 二.pip常用命令 三.No module 'xxxxx' 四.写在最后 前言 写Python代码的时候,经常会遇到包的问题,但是都是遇到一次,搜索一次,解决了.下一次还是同样的 ...
- Python模块包(pycharm右键创建文件夹和python package的区别)中__init__.py文件的作用
在eclipse中用pydev开发Python脚本时,我遇到了一个这样的现象,当我新建一个pydev package时,总会自动地生成一个空的__init__.py文件,因为是python新手,所以很 ...
- 18.Python模块包(pycharm右键创建文件夹和python package的区别)中__init__.py文件的作用
原来在python模块的每一个包中,都有一个__init__.py文件(这个文件定义了包的属性和方法)然后是一些模块文件和子目录,假如子目录中也有 __init__.py 那么它就是这个包的子包了.当 ...
- Python模块/包/库安装几种方法(转载)
一.方法1: 单文件模块直接把文件拷贝到 $python_dir/Lib 二.方法2: 多文件模块,带setup.py 下载模块包(压缩文件zip或tar.gz),进行解压,CMD->cd进入模 ...
- Python——模块&包&异常
模块&包&异常 一. 模块 Python 模块(Module),是一个 Python 文件,以 .py 结尾,包含了 Python 对象定义(变量)和Python语句. 模块能定义函数 ...
- Python模块包中__init__.py文件的作用
转载自:http://hi.baidu.com/tjuer/item/ba37ac4ce7482a0f6dc2f08b 模块包: 包通常总是一个目录,目录下为首的一个文件便是 __init__.py. ...
- day 21 01 序列化模块和模块的导入的复习以及包的初识
day 21 01 序列化和模块的导入的复习以及包的初识 1.序列化模块 什么是序列化模块:数据类型转化成字符串的过程就是序列卷 为什么要使用序列化模块:为了方便存储和网络传输 三种序列化模块: (1 ...
- python模块与包的导入
1. 模块与包的区别 模块,即module,一个包含python语句的.py文件就是一个模块!每个源代码文件都会自动成为模块!没有额外的语法用来声明模块. 包,又称模块包,即module packag ...
随机推荐
- django10 使用自定义标签配置说明
1).在app目录下建目录templatetags[不可改名]目录,然后在该目录下建一个空的__init__.py 2).mytags.py 在templatetags下建一个mytags.py,添加 ...
- IE常见BUG总结(持续更新)
ie6~7下display:inline-block无效 解决方案:需要hack触发hasLayout 1 //IE6.7中内联元素(如span)触发layout属性后, 它的行为和标准中的 inli ...
- Spark-Join优化之Broadcast
适用场景 进行join中至少有一个RDD的数据量比较少(比如几百M,或者1-2G) 因为,每个Executor的内存中,都会驻留一份广播变量的全量数据 Broadcast与map进行join代码示例 ...
- jconsole使用记录
jconsole/JVisualVM连接linux服务器查看JVM使用情况 现需要在本地电脑上查看服务器的tomcat的整体的运行状态,使用jconsole工具. JMX配置 拷贝$JAVA_HOME ...
- RPC接口mock测试
转载:http://blog.csdn.net/ronghuanye/article/details/71124127 1 简介 Dubbo目前的应用已经越来越广泛.或者基于Dubbo二 ...
- Java BaseDao
BaseDao类: package dao; import java.sql.*; public class BaseDao { private static final String driver ...
- Linux下的非阻塞IO(一)
非阻塞IO是相对于传统的阻塞IO而言的. 我们首先需要搞清楚,什么是阻塞IO.APUE指出,系统调用分为两类,低速系统调用和其他,其中低速系统调用是可能会使进程永远阻塞的一类系统调用.但是与磁盘IO有 ...
- java.lang.NoSuchMethodError: ognl.SimpleNode.isEvalChain(Lognl/OgnlContext;)Z解决方法
执行JavaEE项目时出现例如以下错误: java.lang.NoSuchMethodError: ognl.SimpleNode.isEvalChain(Lognl/OgnlContext;)Z a ...
- js中的string.format函数代码
String.prototype.format = function(args) { if (arguments.length > 0) { var result = this; if (arg ...
- Struts2学习小结
1 基础 使用:导入 jar 包,配置 web.xml,并引入 struts.xml 文件 DMI:动态方法调用,调用时使用!分隔 action 名与方法名,如 index ! add.action, ...