Hadoop MapReduce八大步骤以及Yarn工作原理详解
Hadoop是市面上使用最多的大数据分布式文件存储系统和分布式处理系统, 其中分为两大块分别是hdfs和MapReduce, hdfs是分布式文件存储系统, 借鉴了Google的GFS论文. MapReduce是分布式计算处理系统, 借鉴了Google的MapReduce论文.本文着重来梳理下新版也就是2.3后的Hadoop的MapReduce部分, 也就是Yarn框架, 以及MapReduce的八大步骤的详细工作.
一 新老MapReduce的介绍和对比
1.1 老版的MapReduce介绍
老版的MapReduce分为两个部分: JobTracker和TaskTracker.
JobTracker负责接收客户端提交的任务请求, 分配系统资源, 分配任务给TaskTracker, 管理任务的失败/重启等操作.
TaskTracker负责接收并执行JobTracker分配的任务, 并与JobTracker保持心跳机制, 向JobTracker报告自己任务的运行状况.
老版的MapReduce存在问题
所有的任务都在JobTracker上面进行分配, 调度和监控, 处理. 造成了过多的资源消耗, 当job比较多的时候, 增大了JobTracker机器fail的风险.
JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
1.2 新版的MapReduce介绍
新版的MapReduce也叫作Yarn框架, 其最重要的重构在于将资源分配与任务调度/监控进行了分离.
ResourceManager: 资源调度器
首先保持和NodeManager的心跳机制, 接受客户端的任务请求, 根据NodeManager报告的资源情况, 启动调度任务, 分配Container给ApplicationMaster, 监控AppMaster的存在情况, 负责作业和资源分配调度, 资源包括CPU, 内存, 磁盘, 网络等, 它不参与具体任务的分配和监控, 也不能管理具体任务的失败和重启等.
ApplicationMaster: 任务管理器
在其中一台Node机器上, 负责一个Job的整个生命周期. 包括任务的分配调度, 任务的失败和重启管理, 具体任务的所有工作全部由ApplicationMaster全权管理, 就像一个大管家一样, 只向ResourceManager申请资源, 向NodeManager分配任务, 监控任务的运行, 管理任务的失败和重启.
NodeManager: 任务处理器
负责处理ApplicationMaster分配的任务, 并保持与ResourceManager的心跳机制, 监控资源的使用情况并向RM报告进行报告, 支持RM的资源分配工作.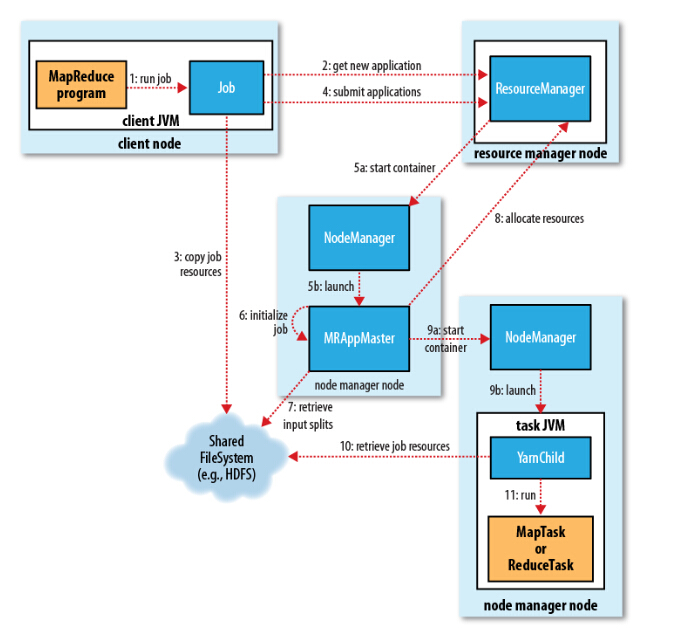
二 MapReduce工作的八大步骤详解
MapReduce的思想
MapReduce最重要的一个思想: 分而治之. 就是将负责的大任务分解成若干个小任务, 并行执行. 完成后在合并到一起. 适用于大量复杂的任务处理场景, 大规模数据处理场景.
Map负责“分”,即把复杂的任务分解为若干个“简单的任务”来并行处理。可以进行拆分的前提是这些小任务可以并行计算,彼此间几乎没有依赖关系。
Reduce负责“合”,即对map阶段的结果进行全局汇总。
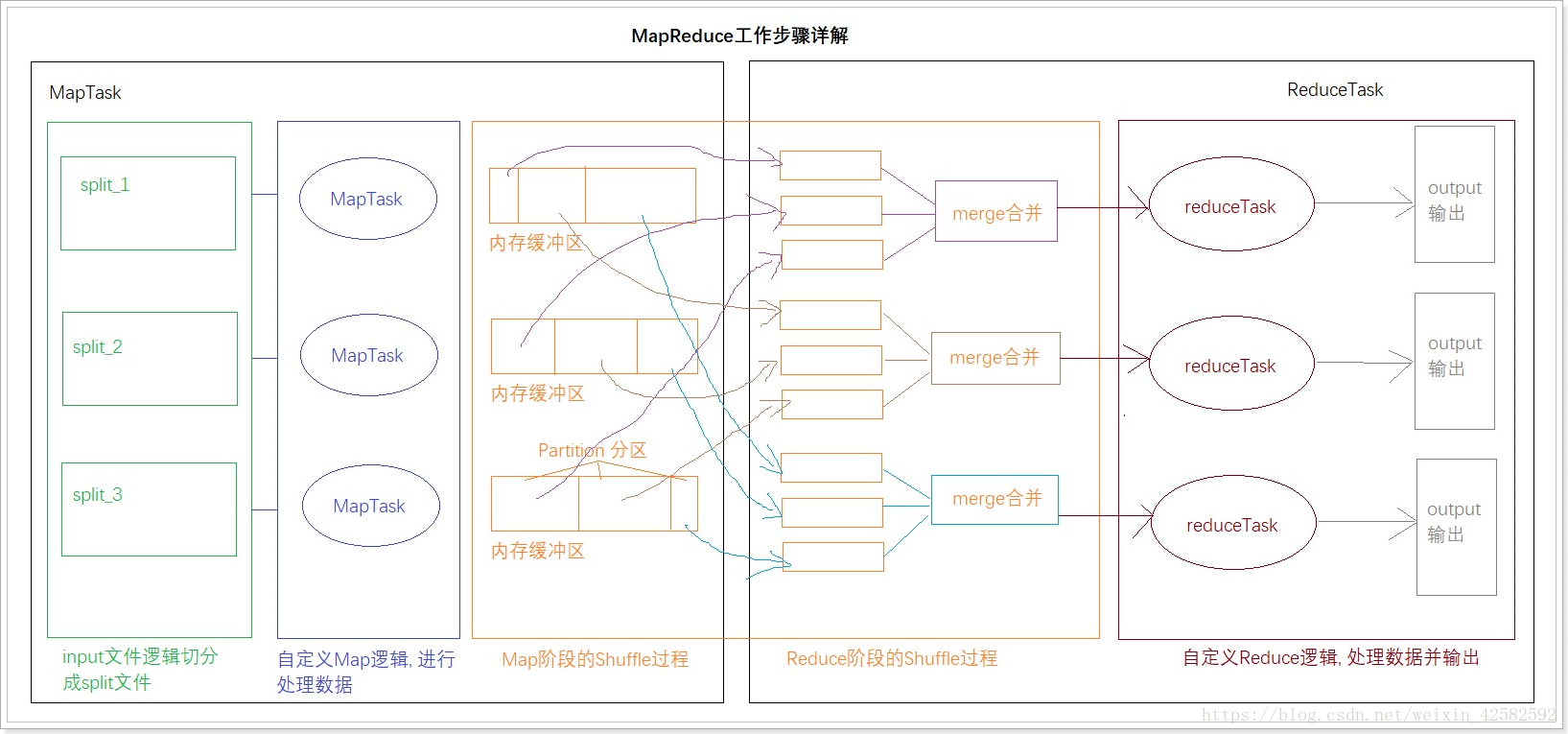
从上图可以看出来, 在客户端提交计算任务后, 首先要读取这个文件, 默认情况下, 一个block块就会有一个Maptask进行处理. 处理完成后通过Shuffle阶段, 经过一系列分区, 排序, 规约, 分组, 进入reduce端, reduce端经过处理后, output输出处理结果即可. 这就是MapReduce的一个大致工作流程.
MapReduce的八大步骤:
Map阶段:
第一步: 通过FileInputFormat读取文件, 解析文件成为key, value对, 输出到第二步.
第二步: 自定义Map逻辑, 处理key1, value1, 将其转换为key2, value2, 输出到第三步.
Shuffle阶段:
第三步: 对key2, value2进行分区.
第四步: 对不同分区内的数据按照相同的key进行排序.
第五步: 分组后的数据进行规约(combine操作),降低数据的网络拷贝(可选步骤)
第六步: 对排序后的数据, 将相同的key的value数据放入一个集合中, 作为value2.
Reduce阶段:
第七步: 对多个map的任务进行合并, 排序. 自定义reduce逻辑, 处理key2, value2, 将其转换为key3, value3, 进行输出.
第八步: 通过FileOutputFormat输出处理后的数据, 保存到文件.
在这里插入图片描述
MapTask运行机制详解
整个MapTask的简要概述:
首先一个文件被split逻辑切分成了多个split文件(切片), 通过FileInputFormat的RecordReader按行(也可以自定义)读取内容给map进行处理, 数据被map处理结束后交给OutputCollector收集器, 对其结果key进行分区 (默认使用Hash分区), 然后写入内存缓冲区(buffer), 每个MapTask都有一个内存缓冲区, 收集map处理结果, 缓冲区很小需要重复利用, 每次缓冲区快满的时候就会将临时文件写入到磁盘中, 在内存缓冲区中会进行排序, 规约, 当整个MapTask任务结束后, 合并这些磁盘中的临时文件, 生成最终的输出文件, 等待reduceTask拉取.
详细步骤:
首先,读取数据组件InputFormat(默认TextInputFormat)会通过getSplits方法对输入目录中文件进行逻辑切片规划得到splits,有多少个split就对应启动多少个MapTask。split与block的对应关系默认是一对一。
将输入文件切分为splits之后,由RecordReader对象(默认LineRecordReader)进行读取,以\n作为分隔符,读取一行数据,返回<key,value>。Key表示每行首字符偏移值,value表示这一行文本内容。
读取split返回<key,value>,进入用户自己继承的Mapper类中,执行用户重写的map函数。RecordReader读取一行这里调用一次。
map逻辑完之后,将map的每条结果通过context.write进行collect数据收集。在collect中,会先对其进行分区处理,默认使用HashPartitioner。
分区的作用就是根据key或value及reduce的数量来决定当前的这对输出数据最终应该交由哪个reduce task处理。默认对key hash后再以reduce task数量取模。默认的取模方式只是为了平均reduce的处理能力,如果用户自己对Partitioner有需求,可以订制并设置到job上。
接下来,会将数据写入内存,内存中这片区域叫做环形缓冲区,缓冲区的作用是批量收集map结果,减少磁盘IO的影响。我们的key/value对以及Partition的结果都会被写入缓冲区。当然写入之前,key与value值都会被序列化成字节数组。
环形缓冲区其实是一个数组,数组中存放着key、value的序列化数据和key、value的元数据信息,包括partition、key的起始位置、value的起始位置以及value的长度。环形结构是一个抽象概念。
缓冲区是有大小限制,默认是100MB。当map task的输出结果很多时,就可能会撑爆内存,所以需要在一定条件下将缓冲区中的数据临时写入磁盘,然后重新利用这块缓冲区。
这个从内存往磁盘写数据的过程被称为Spill,译为溢写。这个溢写是由单独线程来完成,不影响往缓冲区写map结果的线程。所以整个缓冲区有个溢写的比例, 这个比例默认是0.8,也就是当缓冲区的数据已经达到阈值(buffer size * spill percent = 100MB * 0.8 = 80MB),溢写线程启动,锁定这80MB的内存,执行溢写过程。Map task的输出结果还可以往剩下的20MB内存中写,互不影响。
当溢写线程启动后,需要对这80MB空间内的key做排序(Sort)。排序是MapReduce模型默认的行为,这里的排序也是对序列化的字节做的排序。如果job设置过Combiner,那么现在就是使用Combiner的时候了。将有相同key的key/value对的value加起来,减少溢写到磁盘的数据量。Combiner会优化MapReduce的中间结果,所以它在整个模型中会多次使用。
那哪些场景才能使用Combiner呢?从这里分析,Combiner的输出是Reducer的输入,Combiner绝不能改变最终的计算结果。Combiner只应该用于那种Reduce的输入key/value与输出key/value类型完全一致,且不影响最终结果的场景。比如累加,最大值等。Combiner的使用一定得慎重,如果用好,它对job执行效率有帮助,反之会影响reduce的最终结果。
合并溢写文件:Ø每次溢写会在磁盘上生成一个临时文件(写之前判断是否有combiner),如果map的输出结果真的很大,有多次这样的溢写发生,磁盘上相应的就会有多个临时文件存在。当整个数据处理结束之后开始对磁盘中的临时文件进行merge合并,因为最终的文件只有一个,写入磁盘,并且为这个文件提供了一个索引文件,以记录每个reduce对应数据的偏移量。
ReduceTask运行机制详解
简要概述: Reduce大致分为copy、sort、reduce三个阶段,重点在前两个阶段。reduceTask会启动Fetcher线程去Copy属于自己的的文件, 首先将文件放入内存缓冲区, 当copy来的文件到达一定阈值, 就会合并文件到磁盘, 然后在磁盘中生成了众多的溢写文件。直到没有map端的数据时才结束, 然后合并磁盘中的文件, 生成最终的文件.
详细步骤:
Copy阶段,简单地拉取数据。Reduce进程启动一些数据copy线程(Fetcher),通过HTTP方式请求maptask获取属于自己的文件。
Merge阶段。这里的merge如map端的merge动作,只是数组中存放的是不同map端copy来的数值。Copy过来的数据会先放入内存缓冲区中,这里的缓冲区大小要比map端的更为灵活。merge有三种形式:内存到内存;内存到磁盘;磁盘到磁盘。默认情况下第一种形式不启用。当内存中的数据量到达一定阈值,就启动内存到磁盘的merge。与map 端类似,这也是溢写的过程,这个过程中如果你设置有Combiner,也是会启用的,然后在磁盘中生成了众多的溢写文件。第二种merge方式一直在运行,直到没有map端的数据时才结束,然后启动第三种磁盘到磁盘的merge方式生成最终的文件。
合并排序。把分散的数据合并成一个大的数据后,还会再对合并后的数据排序。
对排序后的键值对调用reduce方法,键相等的键值对调用一次reduce方法,每次调用会产生零个或者多个键值对,最后把这些输出的键值对写入到HDFS文件中。
MapReduce Shuffle过程
map阶段处理的数据如何传递给reduce阶段,是MapReduce框架中最关键的一个流程,这个流程就叫shuffle。
shuffle: 洗牌、发牌——(核心机制:数据分区,排序,分组,规约,合并等过程)。
shuffle是Mapreduce的核心,它分布在Mapreduce的map阶段和reduce阶段。一般把从Map产生输出开始到Reduce取得数据作为输入之前的过程称作shuffle。
Collect阶段:将MapTask的结果输出到默认大小为100M的环形缓冲区,保存的是key/value,Partition分区信息等。
Spill阶段:当内存中的数据量达到一定的阀值的时候,就会将数据写入本地磁盘,在将数据写入磁盘之前需要对数据进行一次排序的操作,如果配置了combiner,还会将有相同分区号和key的数据进行排序。
Merge阶段:把所有溢出的临时文件进行一次合并操作,以确保一个MapTask最终只产生一个中间数据文件。
Copy阶段:ReduceTask启动Fetcher线程到已经完成MapTask的节点上复制一份属于自己的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到一定的阀值的时候,就会将数据写到磁盘之上。
Merge阶段:在ReduceTask远程复制数据的同时,会在后台开启两个线程对内存到本地的数据文件进行合并操作。
Sort阶段:在对数据进行合并的同时,会进行排序操作,由于MapTask阶段已经对数据进行了局部的排序,ReduceTask只需保证Copy的数据的最终整体有效性即可。
Shuffle中的缓冲区大小会影响到mapreduce程序的执行效率,原则上说,缓冲区越大,磁盘io的次数越少,执行速度就越快。缓冲区的大小可以通过参数调整, 参数:mapreduce.task.io.sort.mb 默认100M.
Hadoop MapReduce八大步骤以及Yarn工作原理详解的更多相关文章
- 块级格式化上下文(block formatting context)、浮动和绝对定位的工作原理详解
CSS的可视化格式模型中具有一个非常重要地位的概念——定位方案.定位方案用以控制元素的布局,在CSS2.1中,有三种定位方案——普通流.浮动和绝对定位: 普通流:元素按照先后位置自上而下布局,inli ...
- log4j-over-slf4j工作原理详解
log4j-over-slf4j工作原理详解 摘自:https://blog.csdn.net/john1337/article/details/76152906 置顶 2017年07月26日 17: ...
- Hadoop yarn工作流程详解
yarn是什么?1.它是一个资源调度及提供作业运行的系统环境平台 资源:cpu.mem等 作业:map task.reduce Task yarn产生背景?它是从hadoop2.x版本才引入1.had ...
- MapReduce工作原理详解
文章概览: 1.MapReduce简介 2.MapReduce有哪些角色?各自的作用是什么? 3.MapReduce程序执行流程 4.MapReduce工作原理 5.MapReduce中Shuffle ...
- Hadoop学习之路(8)Yarn资源调度系统详解
文章目录 1.Yarn介绍 2.Yarn架构 2.1 .ResourceManager 2.2 .ApplicationMaster 2.3 .NodeManager 2.4 .Container 2 ...
- Spark Streaming初步使用以及工作原理详解
在大数据的各种框架中,hadoop无疑是大数据的主流,但是随着电商企业的发展,hadoop只适用于一些离线数据的处理,无法应对一些实时数据的处理分析,我们需要一些实时计算框架来分析数据.因此出现了很多 ...
- Java虚拟机工作原理详解 (一)
一.类加载器 首先来看一下java程序的执行过程. 从这个框图很容易大体上了解java程序工作原理.首先,你写好java代码,保存到硬盘当中.然后你在命令行中输入 javac YourClassNam ...
- Java虚拟机工作原理详解
原文地址:http://blog.csdn.net/bingduanlbd/article/details/8363734 一.类加载器 首先来看一下java程序的执行过程. 从这个框图很容易大体上了 ...
- ASP.NET页面与IIS底层交互和工作原理详解
转载自:http://www.cnblogs.com/lidabo/archive/2012/03/13/2393200.html 第一回: 引言 我查阅过不少Asp.Net的书籍,发现大多数作者都是 ...
随机推荐
- liunx安装telnet
安装环境:CentOS 6.4 一.安装telnet 1.检测telnet-server的rpm包是否安装 [root@localhost ~]# rpm -qa telnet-server 若无 ...
- java的几个特性
前言 本文主要介绍java语言的三个特性:类型协变和逆变,动态代理和静态代理,注解. 协变和逆变 借用Treant的博文,逆变与协变用来描述类型转换(type transformation)后的继承关 ...
- [置顶]
kubernetes将外部服务映射为内部服务
在实际应用中,一般不会把mysql这种重IO.有状态的应用直接放入k8s中,而是使用专用的服务器来独立部署.而像web这种无状态应用依然会运行在k8s当中,这时web服务器要连接k8s管理之外的数据库 ...
- 分享三个USB抓包软件---Bus Hound,USBlyzer 和-USBTrace
Bus Hound官方下载地址:http://perisoft.net/bushound/Bus Hound 简易使用手册:bus_hound5.0中文使用说明.pdf (246 K) 下载次数:9 ...
- Maven够用就好
学习maven.仅仅要知道pom.dependency.coordination就能够了,剩下的就是学习一个一个的plugin的Goal 配置maven 下载 http://maven.apac ...
- Node.js 读取博客首页并获得文章标题
app.js // 内置http模块,提供了http服务器和客户端功能 var http=require("http"); // 内置文件处理模块 var fs=require(' ...
- react-native 项目实战 -- 新闻客户端(5) -- 完善首页列表数据
1.Home.js: /** * 首页 */ import React, { Component } from 'react'; import { AppRegistry, StyleSheet, T ...
- react-native 项目实战 -- 新闻客户端(4) -- 请求网络数据
1.Home.js /** * 首页 */ import React, { Component } from 'react'; import { AppRegistry, StyleSheet, Te ...
- Cache和Buffer的区别(转载)
1. Cache:缓存区,是高速缓存,是位于CPU和主内存之间的容量较小但速度很快的存储器,因为CPU的速度远远高于主内存的速度,CPU从内存中读取数据需等待很长的时间,而 Cache保存着CPU刚 ...
- 用SwiftGen管理UIImage等的String-based接口
代码地址如下:http://www.demodashi.com/demo/12149.html 问题现状 平时我们使用UIImage,UIFont,UIColor会遇到很多String-based的接 ...