cluster KMeans need preprocessing scale????
Out:
n_digits: 10, n_samples 1797, n_features 64
__________________________________________________________________________________
init time inertia homo compl v-meas ARI AMI silhouette
k-means++ 0.30s 69432 0.602 0.650 0.625 0.465 0.598 0.146
random 0.23s 69694 0.669 0.710 0.689 0.553 0.666 0.147
PCA-based 0.04s 70804 0.671 0.698 0.684 0.561 0.668 0.118
__________________________________________________________________________________
print(__doc__) from time import time
import numpy as np
import matplotlib.pyplot as plt from sklearn import metrics
from sklearn.cluster import KMeans
from sklearn.datasets import load_digits
from sklearn.decomposition import PCA
from sklearn.preprocessing import scale np.random.seed(42) digits = load_digits()
data = scale(digits.data) n_samples, n_features = data.shape
n_digits = len(np.unique(digits.target))
labels = digits.target sample_size = 300 print("n_digits: %d, \t n_samples %d, \t n_features %d"
% (n_digits, n_samples, n_features)) print(82 * '_')
print('init\t\ttime\tinertia\thomo\tcompl\tv-meas\tARI\tAMI\tsilhouette') def bench_k_means(estimator, name, data):
t0 = time()
estimator.fit(data)
print('%-9s\t%.2fs\t%i\t%.3f\t%.3f\t%.3f\t%.3f\t%.3f\t%.3f'
% (name, (time() - t0), estimator.inertia_,
metrics.homogeneity_score(labels, estimator.labels_),
metrics.completeness_score(labels, estimator.labels_),
metrics.v_measure_score(labels, estimator.labels_),
metrics.adjusted_rand_score(labels, estimator.labels_),
metrics.adjusted_mutual_info_score(labels, estimator.labels_),
metrics.silhouette_score(data, estimator.labels_,
metric='euclidean',
sample_size=sample_size))) bench_k_means(KMeans(init='k-means++', n_clusters=n_digits, n_init=10),
name="k-means++", data=data) bench_k_means(KMeans(init='random', n_clusters=n_digits, n_init=10),
name="random", data=data) # in this case the seeding of the centers is deterministic, hence we run the
# kmeans algorithm only once with n_init=1
pca = PCA(n_components=n_digits).fit(data)
bench_k_means(KMeans(init=pca.components_, n_clusters=n_digits, n_init=1),
name="PCA-based",
data=data)
print(82 * '_') # #############################################################################
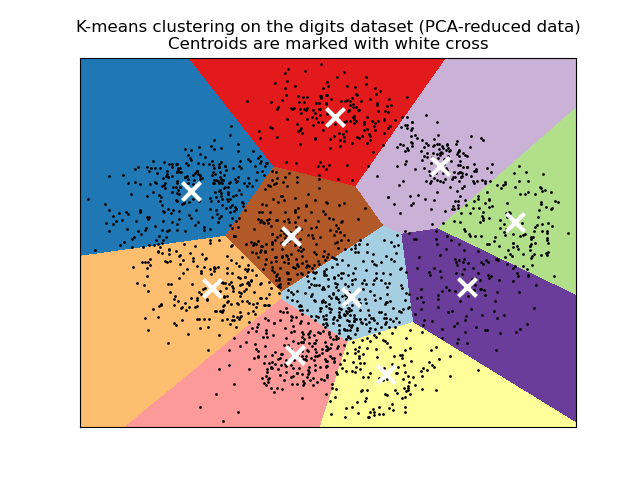
# Visualize the results on PCA-reduced data reduced_data = PCA(n_components=2).fit_transform(data)
kmeans = KMeans(init='k-means++', n_clusters=n_digits, n_init=10)
kmeans.fit(reduced_data) # Step size of the mesh. Decrease to increase the quality of the VQ.
h = .02 # point in the mesh [x_min, x_max]x[y_min, y_max]. # Plot the decision boundary. For that, we will assign a color to each
x_min, x_max = reduced_data[:, 0].min() - 1, reduced_data[:, 0].max() + 1
y_min, y_max = reduced_data[:, 1].min() - 1, reduced_data[:, 1].max() + 1
xx, yy = np.meshgrid(np.arange(x_min, x_max, h), np.arange(y_min, y_max, h)) # Obtain labels for each point in mesh. Use last trained model.
Z = kmeans.predict(np.c_[xx.ravel(), yy.ravel()]) # Put the result into a color plot
Z = Z.reshape(xx.shape)
plt.figure(1)
plt.clf()
plt.imshow(Z, interpolation='nearest',
extent=(xx.min(), xx.max(), yy.min(), yy.max()),
cmap=plt.cm.Paired,
aspect='auto', origin='lower') plt.plot(reduced_data[:, 0], reduced_data[:, 1], 'k.', markersize=2)
# Plot the centroids as a white X
centroids = kmeans.cluster_centers_
plt.scatter(centroids[:, 0], centroids[:, 1],
marker='x', s=169, linewidths=3,
color='w', zorder=10)
plt.title('K-means clustering on the digits dataset (PCA-reduced data)\n'
'Centroids are marked with white cross')
plt.xlim(x_min, x_max)
plt.ylim(y_min, y_max)
plt.xticks(())
plt.yticks(())
plt.show()
It depends on your data.
If you have attributes with a well-defined meaning. Say, latitude and longitude, then you should not scale your data, because this will cause distortion. (K-means might be a bad choice, too - you need something that can handle lat/lon naturally)
If you have mixed numerical data, where each attribute is something entirely different (say, shoe size and weight), has different units attached (lb, tons, m, kg ...) then these values aren't really comparable anyway; z-standardizing them is a best-practise to give equal weight to them.
If you have binary values, discrete attributes or categorial attributes, stay away from k-means. K-means needs to compute means, and the mean value is not meaningful on this kind of data.
from:https://stats.stackexchange.com/questions/89809/is-it-important-to-scale-data-before-clustering
Importance of Feature Scaling
Feature scaling though standardization (or Z-score normalization) can be an important preprocessing step for many machine learning algorithms. Standardization involves rescaling the features such that they have the properties of a standard normal distribution with a mean of zero and a standard deviation of one.
While many algorithms (such as SVM, K-nearest neighbors, and logistic regression) require features to be normalized, intuitively we can think of Principle Component Analysis (PCA) as being a prime example of when normalization is important. In PCA we are interested in the components that maximize the variance. If one component (e.g. human height) varies less than another (e.g. weight) because of their respective scales (meters vs. kilos), PCA might determine that the direction of maximal variance more closely corresponds with the ‘weight’ axis, if those features are not scaled. As a change in height of one meter can be considered much more important than the change in weight of one kilogram, this is clearly incorrect.
To illustrate this, PCA is performed comparing the use of data with StandardScaler applied, to unscaled data. The results are visualized and a clear difference noted. The 1st principal component in the unscaled set can be seen. It can be seen that feature #13 dominates the direction, being a whole two orders of magnitude above the other features. This is contrasted when observing the principal component for the scaled version of the data. In the scaled version, the orders of magnitude are roughly the same across all the features.
The dataset used is the Wine Dataset available at UCI. This dataset has continuous features that are heterogeneous in scale due to differing properties that they measure (i.e alcohol content, and malic acid).
The transformed data is then used to train a naive Bayes classifier, and a clear difference in prediction accuracies is observed wherein the dataset which is scaled before PCA vastly outperforms the unscaled version.
from:http://scikit-learn.org/stable/auto_examples/preprocessing/plot_scaling_importance.html
cluster KMeans need preprocessing scale????的更多相关文章
- 聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
1.用python实现K均值算法 import numpy as np x = np.random.randint(1,100,20)#产生的20个一到一百的随机整数 y = np.zeros(20) ...
- 第八次作业:聚类--K均值算法:自主实现与sklearn.cluster.KMeans调用
import numpy as np x = np.random.randint(1,100,[20,1]) y = np.zeros(20) k = 3 def initcenter(x,k): r ...
- 【原】KMeans与深度学习模型结合提高聚类效果
这几天在做用户画像,特征是用户的消费商品的消费金额,原始数据(部分)是这样的: id goods_name goods_amount 男士手袋 1882.0 淑女装 2491.0 女士手袋 345.0 ...
- 【原】KMeans与深度学习自编码AutoEncoder结合提高聚类效果
这几天在做用户画像,特征是用户的消费商品的消费金额,原始数据(部分)是这样的: id goods_name goods_amount 男士手袋 1882.0 淑女装 2491.0 女士手袋 345.0 ...
- RFM模型的变形LRFMC模型与K-means算法的有机结合
应用场景: 可以应用在不同行业的客户分类管理上,比如航空公司,传统的RFM模型不再适用,通过RFM模型的变形LRFMC模型实现客户价值分析:基于消费者数据的精细化营销 应用价值: LRFMC模型构建之 ...
- 吴裕雄 数据挖掘与分析案例实战(14)——Kmeans聚类分析
# 导入第三方包import pandas as pdimport numpy as np import matplotlib.pyplot as pltfrom sklearn.cluster im ...
- 131.005 Unsupervised Learning - Cluster | 非监督学习 - 聚类
@(131 - Machine Learning | 机器学习) 零. Goal How Unsupervised Learning fills in that model gap from the ...
- Kmeans应用
1.思路 应用Kmeans聚类时,需要首先确定k值,如果k是未知的,需要先确定簇的数量.其方法可以使用拐点法.轮廓系数法(k>=2).间隔统计量法.若k是已知的,可以直接调用sklearn子模块 ...
- Scikit-Learn模块学习笔记——数据预处理模块preprocessing
preprocessing 模块提供了数据预处理函数和预处理类,预处理类主要是为了方便添加到 pipeline 过程中. 数据标准化 标准化预处理函数: preprocessing.scale(X, ...
随机推荐
- 源码安装Apache,报错:Cannot use an external APR with the bundled APR-util
一般在第一次源码安装是没有问题的,在版本变化情况下在次源码安装可能会遇到此问题: apache2.0.x与apache2.2.x在apr有很大区别,前者为依赖公用apr,后者依赖于自身的apr.一般前 ...
- js实现table内 某列的内容进行即时筛选
往往有些时候,我们把数据从数据库读取出来,显示到table里面,而此时来了个新需求,要在一个搜索框内输入关键字,表格的内容进行即时的筛选. 而即时触发进行数据库的查询,再回调显示,就显得慢,拖累服务器 ...
- 爬虫入门【6】Selenium用法简介
Selenium 是什么? 一句话,自动化测试工具.它支持各种浏览器,包括 Chrome,Safari,Firefox 等主流界面式浏览器. 如果你在这些浏览器里面安装一个 Selenium 的插件, ...
- EasyNVR无插件直播服务器播放页面的集成----单独的播放器样式
背景需求: EasyNVR自身拥有独立的客户端体系,安卓和IOS拥有各自独立的APP, 安卓下载地址:https://fir.im/EasyNVR: IOS下载可直接在APPstore搜索EasyNV ...
- 详解Maven项目利用java service wrapper将Java程序生成Windows服务
在项目的开发中,有时候需要将Java应用程序打包成Windows服务,我们就直接可以通过windows的服务来启动和关闭java程序了. 本博文将通过有两种方法实现该功能,手动创建法和Maven自动打 ...
- POJ 1584 A Round Peg in a Ground Hole【计算几何=_=你值得一虐】
链接: http://poj.org/problem?id=1584 http://acm.hust.edu.cn/vjudge/contest/view.action?cid=22013#probl ...
- iOS 添加震动效果
开发过程中,有时候会碰到点击按钮或者某个动画会配合震动效果:下面介绍iOS开发过程中的震动添加: 导入:#import <AudioToolbox/AudioToolbox.h> 在需要出 ...
- 三款查看class文件结构的工具
classpy JavaClassViewer jclasslib
- greenlet和gevent模块的区别?
协程是一中多任务实现方式,它不需要多个进程或线程就可以实现多任务. yield能实现协程,不过实现过程不易于理解,greenlet是在这方面做了改进,通过switch. greenlet可以实现协程, ...
- Bootstrap 第一天
Bootstrap第一天 1.什么是Bootstrap? Bootstrap是由两位设计开发的. Bootstrap主要是前端的框架(HTML.CSS.JS). 2.为什么使用Boot ...