Selenium2+python自动化14-iframe【转载】
前言
有很多小伙伴在拿163作为登录案例的时候,发现不管怎么定位都无法定位到,到底是什么鬼呢,本篇详细介绍iframe相关的切换
以http://mail.163.com/登录页面10为案例,详细介绍switch_to_frame使用方法.
一、frame和iframe区别
Frame与Iframe两者可以实现的功能基本相同,不过Iframe比Frame具有更多的灵活性。 frame是整个页面的框架,iframe是内嵌的网页元素,也可以说是内嵌的框架
Iframe标记又叫浮动帧标记,可以用它将一个HTML文档嵌入在一个HTML中显示。它和Frame标记的最大区别是在网页中嵌入 的<Iframe></Iframe>所包含的内容与整个页面是一个整体,而<Frame>< /Frame>所包含的内容是一个独立的个体,是可以独立显示的。另外,应用Iframe还可以在同一个页面中多次显示同一内容,而不必重复这段内 容的代码。
二、163登录界面
1.打开http://mail.163.com/登录页面10
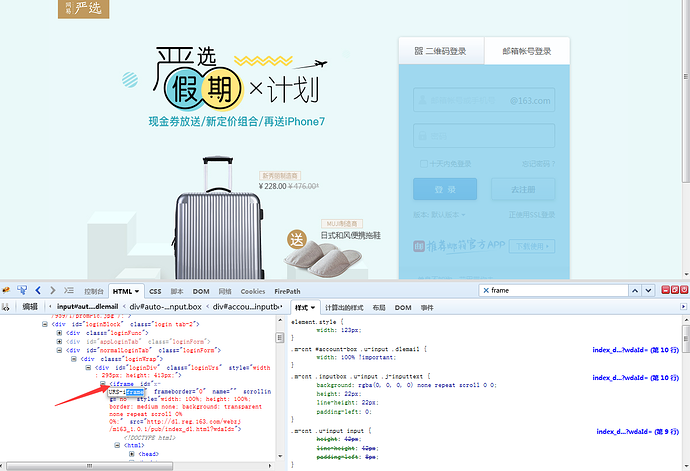
2.用firebug定位登录框
3.鼠标停留在左下角(定位到iframe位置)时,右上角整个登录框显示灰色,说明iframe区域是整个登录框区域
4.左下角箭头位置显示iframe属性<iframe id="x-URS-iframe" frameborder="0" name=""
三、切换iframe
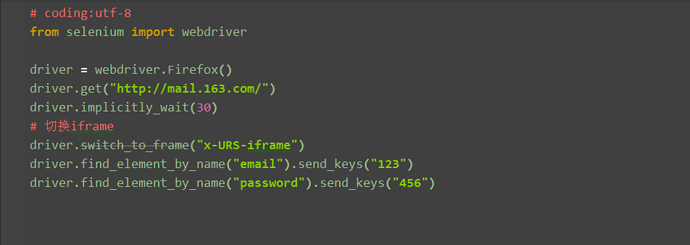
1.由于登录按钮是在iframe上,所以第一步需要把定位器切换到iframe上
2.用switch_to_frame方法切换,此处有id属性,可以直接用id定位切换
四、如果iframe没有id怎么办?
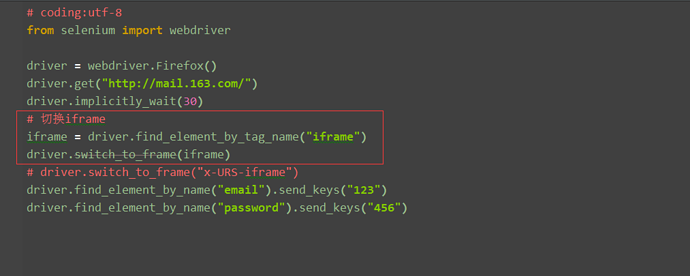
1.这里iframe的切换是默认支持id和name的方法的,当然实际情况中会遇到没有id属性和name属性为空的情况,这时候就需要先定位iframe
2.定位元素还是之前的八种方法同样适用,这里我可以通过tag先定位到,也能达到同样效果
QQ交流群:232607095
(版权所有:"yoyoketang"微信公众号)
五、释放iframe
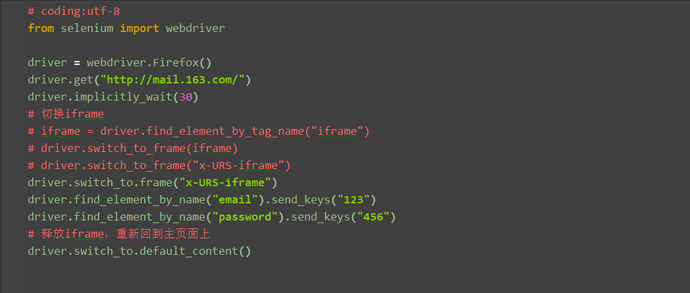
1.当iframe上的操作完后,想重新回到主页面上操作元素,这时候,就可以用switch_to_default_content()方法返回到主页面
六、如何判断元素是否在iframe上?
1.定位到元素后,切换到firepath界面
2.看firebug工具左上角,如果显示Top Window说明没有iframe
3.如果显示iframe#xxx这样的,说明在iframe上,#后面就是它的id
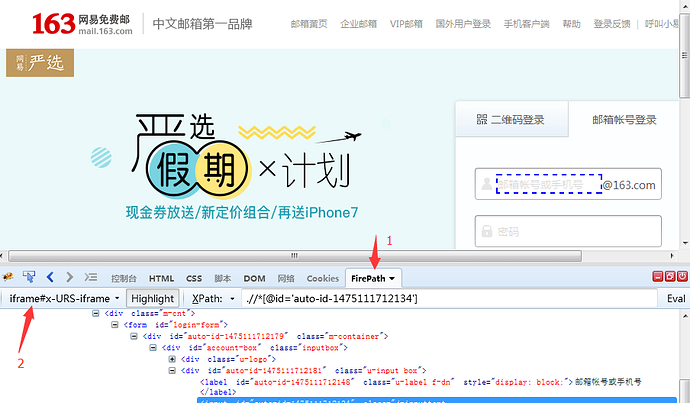
七、如何解决switch_to_frame上的横线呢?
1.先找到官放的文档介绍
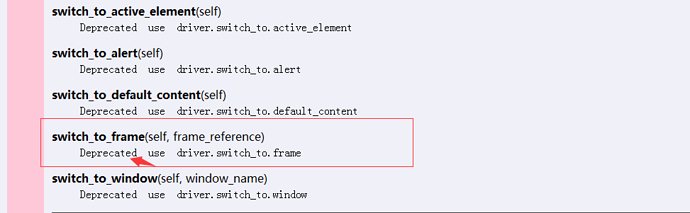
2.官方已经不推荐上面的写法了,用这个写法就好了driver.switch_to.frame()
八、参考代码如下
# coding:utf-8
from selenium import webdriver
driver = webdriver.Firefox()
driver.get("http://mail.163.com/")
driver.implicitly_wait(30)
# 切换iframe
# iframe = driver.find_element_by_tag_name("iframe")
# driver.switch_to_frame(iframe)
# driver.switch_to_frame("x-URS-iframe")
driver.switch_to.frame("x-URS-iframe")
driver.find_element_by_name("email").send_keys("123")
driver.find_element_by_name("password").send_keys("456")
# 释放iframe,重新回到主页面上
driver.switch_to.default_content()
Selenium2+python自动化14-iframe【转载】的更多相关文章
- Selenium2+python自动化24-js处理富文本(带iframe)【转载】
前言 上一篇Selenium2+python自动化23-富文本(自动发帖)解决了富文本上iframe问题,其实没什么特别之处,主要是iframe的切换,本篇讲解通过js的方法处理富文本上iframe的 ...
- Selenium2+python自动化33-文件上传(send_keys)【转载】
前言 文件上传是web页面上很常见的一个功能,自动化成功中操作起来却不是那么简单. 一般分两个场景:一种是input标签,这种可以用selenium提供的send_keys()方法轻松解决: 另外一种 ...
- Selenium2+python自动化24-js处理富文本(带iframe)
前言 上一篇Selenium2+python自动化23-富文本(自动发帖)解决了富文本上iframe问题,其实没什么特别之处,主要是iframe的切换,本篇讲解通过js的方法处理富文本上iframe的 ...
- Selenium2+python自动化61-Chrome浏览器(chromedriver)【转载】
前言 selenium2启动Chrome浏览器是需要安装驱动包的,但是不同的Chrome浏览器版本号,对应的驱动文件版本号又不一样,如果版本号不匹配,是没法启动起来的. 一.Chrome遇到问题 1. ...
- Selenium2+python自动化23-富文本(自动发帖)【转载】
前言 富文本编辑框是做web自动化最常见的场景,有很多小伙伴遇到了不知道无从下手,本篇以博客园的编辑器为例,解决如何定位富文本,输入文本内容 一.加载配置 1.打开博客园写随笔,首先需要登录,这里为了 ...
- Selenium2+python自动化59-数据驱动(ddt)【转载】
前言 在设计用例的时候,有些用例只是参数数据的输入不一样,比如登录这个功能,操作过程但是一样的.如果用例重复去写操作过程会增加代码量,对应这种多组数据的测试用例,可以用数据驱动设计模式,一组数据对应一 ...
- Selenium2+python自动化54-unittest生成测试报告(HTMLTestRunner)【转载】
前言 批量执行完用例后,生成的测试报告是文本形式的,不够直观,为了更好的展示测试报告,最好是生成HTML格式的. unittest里面是不能生成html格式报告的,需要导入一个第三方的模块:HTMLT ...
- Selenium2+python自动化55-unittest之装饰器(@classmethod)【转载】
前言 前面讲到unittest里面setUp可以在每次执行用例前执行,这样有效的减少了代码量,但是有个弊端,比如打开浏览器操作,每次执行用例时候都会重新打开,这样就会浪费很多时间. 于是就想是不是可以 ...
- Selenium2+python自动化52-unittest执行顺序【转载】
前言 很多初学者在使用unittest框架时候,不清楚用例的执行顺序到底是怎样的.对测试类里面的类和方法分不清楚,不知道什么时候执行,什么时候不执行. 本篇通过最简单案例详细讲解unittest执行顺 ...
随机推荐
- 解决boostrap-table有水平和垂直滚动条时,滚动条滑到最右边表格标题和内容单元格无法对齐的问题
问题:boostrap-table有水平和垂直滚动条时,滚动条不高的时候(滚动高度比较大的时候没有问题),滚动条滑到最右边表格标题和内容单元格无法对齐的问题 问题原因:bootstrap-table源 ...
- Javascript 属性高级写法
http://www.cnblogs.com/YuanSong/p/3899287.html
- 剑指Offer - 九度1518 - 反转链表
剑指Offer - 九度1518 - 反转链表2013-11-30 03:09 题目描述: 输入一个链表,反转链表后,输出链表的所有元素.(hint : 请务必使用链表) 输入: 输入可能包含多个测试 ...
- mac虚拟机上(centos系统)设置联网
前面介绍了mac安装虚拟机VirtualBox,并在虚拟机上装上了centos,这里在说明一下联网问题. 首先打开centos系统,并输入命令$ ip addr 可得到如下: 发现找不到ip地址,这时 ...
- day01--python基础1
# 01讲 - Windows下执行程序,必须加 PYTHON.在LINUX下,可以不指明是PYTHON.但是,执行钱许给予hello.py执行权限. - 其次,只要变成可执行程序,必须第一行事前 ...
- glance参数
Image service property keys https://docs.openstack.org/python-glanceclient/latest/cli/property-keys. ...
- Leetcode 665.非递减数列
非递减数列 给定一个长度为 n 的整数数组,你的任务是判断在最多改变 1 个元素的情况下,该数组能否变成一个非递减数列. 我们是这样定义一个非递减数列的: 对于数组中所有的 i (1 <= i ...
- Vue-cli 本地开发请求https 接口 DEPTH_ZERO_SELF_SIGNED_CERT
环境:npm run dev 本地开发连接后台的开发环境的接口. 贴上proxyTable 的转发(代理?反向?这个具体叫什么不明白...) proxyTable: { "/api" ...
- 爬虫:Scrapy10 - Link Extractors
Link Extractors 适用于从网页(scrapy.http.Response)中抽取会被 follow 的链接的对象. Scrapy 默认提供 2 种可用的 Link Extractor,但 ...
- 第一次软件工程作业补充plus
一.代码的coding地址:coding地址. 二.<构建之法>读后问题以及感言(补充): 1.对于7.3MSF团队模型,7.2.6保持敏捷,预期和适应变化,中的"我们是预期变化 ...