第六章 Java并发容器和框架
ConcurrentHashMap的实现原理与使用
ConcurrentHashMap是线程安全且高效的hashmap。本节让我们一起研究一下该容器是如何在保证线程安全的同时又能保证高效的操作。
为什么要使用ConcurrentHashMap
在并发编程中使用HashMap可能导致程序死循环。而使用线程安全的HashTable效率又非常低下,基于以上两个原因,便有了ConcurrentHashMap的登场机会。
(1)线程不安全的HashMap
在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率接近100%,所以在并发情况下不能使用HashMap。例如一下代码
final HashMap<String, String> map = new HashMap<>(2);
Thread thread = new Thread(new Runnable() {
@Override
public void run() {
for (int i = 0; i < 10000; i++) {
new Thread(new Runnable() {
@Override
public void run() {
map.put(UUID.randomUUID().toString(), "");
}
}, "ftf" + i).start();
}
}
}, "ftf");
thread.start;
thread.join;
HashMap在并发执行put操作时会引起死循环,是因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环形数据结构,Entry的next节点永远不会为空,就会产生死循环获取Entry.
(2)效率低下的HashTable
HashTable容器使用synchronized来保证线程安全,但在线程竞争激烈的情况下HashTable的效率非常低下。因为当一个线程访问HashTable的同步方法,其他线程也访问HashTable的同步方法时,会进入阻塞或轮询状态。
(3)ConcurrentHashMap的锁分段技术可有效提升并发访问率
HashTable容器在竞争激烈的并发环境下表现出效率低下的原因是所有访问HashTable的线程都必须竞争同一把锁,假如容器里有多把锁,每一把锁用于锁容器的一部分数据,那么当多线程访问容器里不同数据段的数据时,线程间就不会存在锁竞争,从而可以有效提高并发访问率,这就是ConcurrentHashMap所使用的锁分段技术。首先将数据分成一段一段地存储,然后给每一段数据配一把锁,当一个线程占用锁访问其中一个段数据的时候,其他数据段也能被其他线程访问。
ConcurrentHashMap的结构
ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成。Segment是一种可重入锁(ReentrantLock),在ConcurrentHashMap里扮演锁的角色;HashEntry则用于储存键值对数据。一个ConcurrentHashMap里包含一个Segment数组。Segment的结构和HashEntry类似,是一种数组和链表结构。一个Segment里包含一个HashEntry数组,每个HashEntry是一个链表结构的元素,每个Segment守护着一个HashEntry数组里的元素,当对HashEntry数组的数据进行修改时,必须首先获得与它对于的Segment锁。
ConcurrentHashMap的初始化
ConcurrentHashMap初始化方法是通过initialCapacity,loadFactor和concurrencyLevel等几个参数来初始化Segment数组、段偏移量segmentShift、段掩码segmentMask和每个segment里的HashEntry数组来实现的。
初始化segments数组:让我们来看一下初始化segments数组的源代码
if(concurrencyLevel > MAX_SEGMENTS) concurrencyLevel = MAX_SEGMENTS
int sshift = 0;
int ssize = 1;
while (ssize < DEFAULT_CONCURRENCY_LEVEL) {
++sshift;
ssize <<= 1;
}
int segmentShift = 32 - sshift;
int segmentMask = ssize - 1;
this.segments = Segment.newArray(ssize);
由上面代码可知,segments数组的长度ssize是通过concurrencyLevel计算得出的。为了能通过按位与的散列算法来定位segments数组的索引,必须保证segments数组的长度是2的N次方,所以必须计算出一个大于或等于concurrencyLevel的最小的2的N次方值来作为segments数组的长度。concurrencyLevel的最大值是65535,这意味着segments数组的长度最大为65536,对应的二进制是16位。
初始化segmentShift和segmentMask:这两个全局变量需要在定位segment时的散列算法里使用,sshift等于ssize从1向左移位的次数,在默认情况下concurrencyLevel等于16,1需要向左移位移动4次,所以sshift等于4。segmentShift用于定位参与散列运算的位数,segmentShift等于32减去sshift,所以等于28,这里之所以用32是因为ConcurrentHashMap里的hash()方法输出的最大数是32位的。segmentMask是散列运算的掩码,等于ssize减1,即15,掩码的二进制各个位的值都是1.因为ssize的最大长度是65536,所以segmentShift最大值是16,segmentMask最大值是65535,对应的二进制是16位,每个位都是1.
初始化每个segment:输入参数initalCapacity是ConcurrentHashMap的初始化容量,loadfactor是每个segment的负载因子,在构造方法里需要通过两个参数来初始化数组中的每个segment。
定位segment
既然ConcurrentHashMap使用分段锁Segment来保护不同段的数据,那么在插入和获取元素的时候,必须先通过散列算法定位到segment。ConcurrentHashMap会首先使用Wang/Jenkins hash的变种算法对元素的hashCode进行一次再散列。之所以进行再散列,目的是减少散列冲突,使元素能够均匀地分布在不同的Segment上,从而提高容器的存取效率。假如散列的质量差到极点,那么所有的元素都在一个Segment中,不仅存取元素缓慢,分段锁也会失去意义。
默认情况下segmentShift为28,segmentMask为15,再散列后的数量最大是32位二进制数据,向右无符号移动28位,意思是让高4位参与到散列运算中,(hash>>>segmentShit)&segmentMask的运算结果分别是4,15,7和8,可以看到散列值没有发生冲突。
ConcurrentHashMap的操作
get操作:Segment的get操作实现非常简单和高效。先经过一次再散列,然后使用这个散列值通过散列运算定位到Segment,再通过散列算法定位到元素,代码如下
public V get(Object key){
int hash = hash(key.hashCode());
return segmentFor(hash).get(key,hahsh)
}
get操作的高效之处在于整个get过程不需要加锁,除非读到的值是空才会加锁重读。它的get方法里将要使用的共享变量都定义成volatile类型,如用于统计当前Segment大小的count字段和用于存储值的HashEntry的value,定义成volatile的变量,能够在线程之间保持可见性,能够被多线程同时读,并且保证不会读到过期的值,但是只能被单线程写(有一种情况可以被多线程写,就是写入的值不依赖与原值),在get操作里只需要读不需要写共享变量count和value,所以可以不用加锁。之所以不会读到过期的值,是因为根据Java内存模型的happen before原则,对volatile字段的写入操作先于读操作,即使两个线程同时修改和获取volatile变量,get操作也能拿到最新的值,这是用volatiel替换锁的经典应用场景。
transient volatile int count;
volatile V value;
在定位元素的代码里我们可以发现,定位HashEntry和定位Segment的散列算法虽然一样,都与数组的长度减去1再相“与”,但是想“与”的值不一样,定位segment使用的是元素的hashcode通过再散列后得到的值的高位,而定位HashEntry直接使用的是再散列后的值。其目的是避免两次散列后的值一样,虽然元素在Segment里散列开了,但是却没有再HashEntry里散列开。
put操作:由于put方法里需要对共享变量进行写入操作,所以为了线程安全,在操作共享变量时必须加锁。put方法首先定位到Segment,然后再Segment里进行插入操作。插入操作需要经历两个步骤,第一步判断是否需要对Segment里的HashEntry数组进行扩容,第二步添加元素的位置,然后将其放在HashEntry里。
(1)是否需要扩容:在插入元素前会先判断Segment里的HashEntry数组是否超过容量,如果超过阙值,则对数组进行扩容。值得一提的是,Segment的扩容判断比HashMap更恰当,因为HashMap是在插入元素后判断元素是否已经到达容量的,如果达到了就进行扩容,但是很有可能扩容之后没有新元素插入,这时HashMap就进行了一次无效的扩容,
(2)如何扩容:在扩容的时候,首先会创建一个容量是原来容量两倍的数组,然后将原数组里的元素进行再散列后插入到新的数组里。为了高效,ConcurrentHashMap不会对整个容器进行扩容,而只对某个segment进行扩容。
(3)size操作:如果要统计整个ConcurrentHashMap里元素的大小,就必须统计所有Segment里元素的大小后求和。Segment里的全局变量count是一个colatile变量,那么在多线程场景下,是不是直接把所有的Segment的count相加就可以得到整个ConcurrentHashMap大小呢?不是的,虽然相加时可以获取每个Segment的count最新值,但是可能累加前使用count发生了变化,那么统计结果就不准了。所以,最安全的做法是在统计size的时候把所有Segment的put,remone和clean方法全部锁住,但是这种做法显然非常抵消。因为在累加count操作过程中,之前累加过的count发生变化的几率非常小,所以ConcurrentHashMap的做法是先尝试2次通过不锁住Segment的方式来统计各个Segment大小,如果统计的过程中,容器的count发生了变化,则再采用加锁的方式来统计所有Segment大小。ConcurrentHashMap如何判断统计时候发生了变化呢?使用modCount变量,在put,remove和clean方法里操作元素前都会将变成modCount进行加1,那么在统计size前后比较modCount是否发生变化,从而得知容器的大小是否发生变化。
ConcurrentLinkedQueue
在并发编程中,有时候需要使用线程安全的队列。如果要实现一个线程安全的队列有两种方式:一种是使用阻塞算法,另一种是使用非阻塞算法。使用阻塞算法的队列可以用一个锁(入队和出队用同一把锁)或两个锁(入队和出队用于不同的锁)等方式实现。非阻塞的实现方式则可以使用循环CAS的方式实现。
ConcurrentLinkedQueue是一个基于链接节点的无界线程安全队列,它采用先进先出的规则对节点进行排序,当我们添加一个元素的时候,它会添加到队列的尾部;当我们获取一个元素时候,它会返回队列头部的元素。它采用了“wait-free”算法(即CAS算法)来实现,概算在Michael&Scoft算法上进行了一些修改。
ConcurrentLinkedQueue的结构
ConcurrentLinkedQueue由head节点和tail节点组成,每个节点(node)由节点元素(item)和指向下一个节点(next)的引用组成,节点和节点之间就是通过这个next关联起来,从而组成一张链接结构的队列。默认情况下head节点存储的元素为空,tail节点等于head节点。
private transient volatile Node<E> tail = head;
入队列
(1)入队列的过程
入队列就是将入队节点添加到队列的尾部。为了方便理解入队时队列的变化,以及head节点和tail几点的变化,这里以一个示例来展开介绍。假设我们想在一个队列依次插入4个节点,每添加一个节点就做了一个队列的快照图,如下
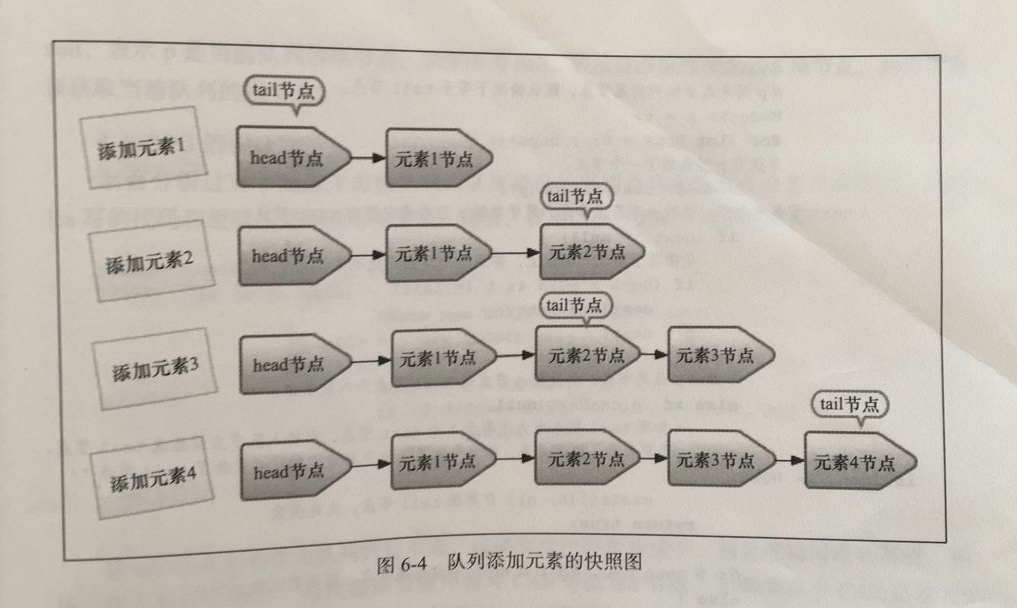
- 添加元素1。队列更新head节点的next节点为元素1节点。又因为tail节点默认情况下等于head节点,所以它们的next节点都指向元素的1节点
- 添加元素2。队列首先设置元素1节点的next节点为元素2节点,然后更新tail节点指向元素2节点
- 添加元素3。设置tail节点的next节点为元素3节点
- 添加元素4。设置元素3的next几点为元素4节点,然后将tail节点指向元素4节点
通过调试入队过程并观察head节点和tail节点的变化,发现入队主要做两件事情:
第一是将入队节点设置成当前队列尾节点的下一个节点;
第二是更新tail节点,如果tail节点的next节点不为空,则将入队节点设置成tail节点,反之,则将入队及诶单设置成tail节点的next节点,所以节点不总是尾节点。
如果是多线程进入入队,我们通过源码来详细分析它是如何使用CAS算法来入队的
/**
* Inserts the specified element at the tail of this queue.
* As the queue is unbounded, this method will never return {@code false}.
*
* @return {@code true} (as specified by {@link Queue#offer})
* @throws NullPointerException if the specified element is null
*/
public boolean offer(E e) {
checkNotNull(e);
final Node<E> newNode = new Node<E>(e); for (Node<E> t = tail, p = t;;) {
Node<E> q = p.next;
if (q == null) {
// p is last node
if (p.casNext(null, newNode)) {
// Successful CAS is the linearization point
// for e to become an element of this queue,
// and for newNode to become "live".
if (p != t) // hop two nodes at a time
casTail(t, newNode); // Failure is OK.
return true;
}
// Lost CAS race to another thread; re-read next
}
else if (p == q)
// We have fallen off list. If tail is unchanged, it
// will also be off-list, in which case we need to
// jump to head, from which all live nodes are always
// reachable. Else the new tail is a better bet.
p = (t != (t = tail)) ? t : head;
else
// Check for tail updates after two hops.
p = (p != t && t != (t = tail)) ? t : q;
}
}
从源代码角度来看,整个入队过程主要做两件事情:
第一是定位出尾节点;
第二是使用CAS算法将入队节点设置成尾节点的next节点,如不成功则重试
(2)定位尾节点
tail节点并不总是尾节点,所以每次入队都必须先通过tail节点来找到尾节点,尾节点可能是tail节点,也可能是tail节点的next节点,代码中循环体中的第一个if就是判断tail是否有next节点,有则表示next节点的可能是尾节点。获取tail节点的next节点需要注意的是p节点等于p的next节点情况,只有一种可能就是p节点和p的next节点都等于空,表示这个队列刚刚初始化,正准备添加节点,所以需要返回head节点,获取p节点的next节点代码如下
final Node<E> succ(Node<E> p) {
Node<E> next = p.next;
return (p == next) ? head : next;
}
(3)设置入队节点为尾节点
p.casNext(null, n)方法用于将入队及诶单设置为当前队列尾尾节点的next节点,如果p是null,表示p是当前队列的尾节点,如果不为null,表示有其他线程更新了尾节点,则需要重新获取当前队列的尾节点
(4)hops的设计意图
上面分析过对于先进先出的队列入队所要做的事情是将入队节点设置成尾节点,dong lea写的代码和逻辑还是稍微有点复杂,那么我们用一下方式来实现是否可行?
public boolean offer(E e){
if(e == null) throw new NullPointerException();
Node<E> n = new Node<E>(e);
for(;;){
Node<E> t = tail;
if(t.casNext(null, n) && casTail(t, n)) return true;
}
}
让tail节点永远作为队列的尾节点,这样实现代码了非常少,而且逻辑清晰和易懂。但是,这么做有一个缺点,每次都需要使用循环CAS更新tail节点。如果能减少CAS更新tail节点的次数,就能提高入队的效率,所有dong lea使用hops变量来控制并减少tail节点的更新频率,并不是每次节点入队后都将tail节点更新成尾节点,而是当tail节点和尾节点的距离大于等于常量HOPS的值(默认等于1)时才更新tail节点,tail和尾节点的距离越长,使用CAS更新tail节点的次数就会越少,但是距离越长带来的负面效果就是每次入队时定位尾节点的时间就越长,因为循环体需要多循环一次来定位出尾节点,但是这样仍然能提高入队的效率,因为从本质上来看它通过增加对volatile变量的读操作来减少对volatile变量的写操作,而对volatile变量的写操作开销要远远大于读操作,所以入队效率会有所提升。
注意:入队方法永远返回true,所以不要通过返回值判断入队是否成功
出队列
出队列的就是从队列里返回一个节点元素,并清空该节点对元素的引用。每个节点出队的快照如下
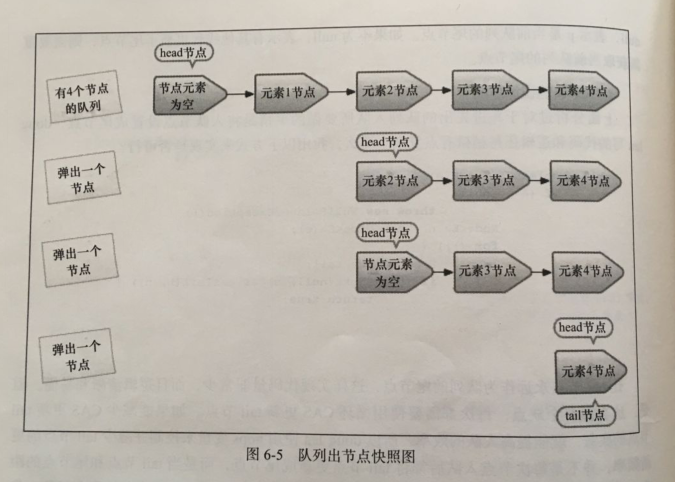
由图可知,并不是每次出队时都更新head节点,当head节点里有元素时,直弹出head节点里的元素,而不会更新head节点。只有当head节点里没有元素时,出队操作才会更新head节点。这种做法也是通过hops变量来减少使用CAS更新head节点的消耗,从而提高出队效率。
Java中的阻塞队列
什么是阻塞队列
阻塞队列(BlockingQueue)是一个支持两个附加操作的队列,这两个附加的操作支持阻塞的插入和移除方法。
(1)支持阻塞的插入方法:意思是当队列满时,队列会阻塞插入元素的线程,直到队列不满
(2)支持阻塞的移除方法:意思是在队列为空时,获取元素的线程会等待队列变为非空
阻塞队列常用语生产者和消费者的场景,生产者向队里里添加元素,消费者是从队列里取元素的线程。阻塞队列就是生产者存放元素,消费者获取元素的容器。
在阻塞队列不可用时,这两个附加操作提供了4种处理方式
| 方法/处理方式 | 抛出异常 | 返回特殊值 | 一直阻塞 | 超时退出 |
| 插入方法 | add(e) | offer(e) | put(e) | offer(e, time, unit) |
| 移除方法 | remove() | poll() | take() | poll(time, unit) |
| 检查方法 | element() | peek() | 不可用 | 不可用 |
抛出异常:当队列满时,如果再插入元素,会抛出IllegalStateException异常。当队列空时,从队列里获取元素会抛出NoSuchElementException异常
返回特殊值:当往队列插入元素时,会返回元素是否插入成功,成功返回true。如果是移除方法,则是从队列里取出一个元素,如果没有则返回null
一直阻塞:当阻塞队列满时,如果生产者往队列里put元素,队列会一直阻塞生产者,知道队里可用或者响应中断退出。当队列为空时,如果消费者从队列里take元素,队列会阻塞消费者线程,直到队列不为空
超时退出:当阻塞队列满时,如果生产者往队里里插入元素,队列会阻塞生产者线程一段时间,如果超过了指定的时间,生产者线程就会退出
注意:如果是无界阻塞队列,队里不可能会出现满的情况,所以使用put或offer方法永远不会被阻塞,而且使用offer方法时,该方法永远返回true
Java里的阻塞队列
JDK提供了7种阻塞队列:
- ArrayBlockingQueue:一个由数组结构组成的有界阻塞队列
- LinkedBlockingQueue:一个由链表结构组成的有界阻塞队列
- PriorityBlockingQueue:一个支持优先级排序的无界阻塞队列
- DelayQueue:一个使用优先级队列实现的无界阻塞队列
- SynchronousQueue:一个不存储元素的阻塞队列
- LinkedTransferQueue:一个由链表结构组成的无界阻塞队列
- LingkedBlockingDeque:一个由链表结构组成的双向阻塞队列
ArrayBlockingQueue
ArrayBlockingQueue是一个用数组实现的有界阻塞队列,此队列按照先进先出(FIFO)的原则对元素进行排序。默认情况下不保证线程公平的访问队列。
LinkedBlockingQueue
LinkedBlockingQueue是一个用链表实现的有界阻塞队列。此队列的默认和最大长度为Integer.MAX_VALUE。此队列按照先进先出的原则对元素进行排序
PriorityBlockingQueue
PriorityBlockingQueue是一个支持优先级的无界阻塞队列。默认情况下元素采取自然顺序升序排列。也可以自定义类实现cpmpareTo()方法来指定元素排序规则,或者初始化PriorityBlockingQueue时,指定构造参数Comparator来对元素进行排序,需要注意的是不能保证同优先级元素的顺序
DelayQueue
DelayQueue是一个支持延时获取元素的无界阻塞队列。队列使用PriorityQueue来实现。队列中的元素必须实现Delayed接口,在创建元素时可以指定多久才能从队列中获取当前元素。只有在延迟期满时才能从队列中提取元素
DelayQueue非常有用,可以运用在以下场景:
- 缓存系统的设计:可以用DelayQueue保存缓存元素的有效期,使用一个线程循环查询DelayQueue,一旦能从DelayQueue中获取元素时,表示缓存有效期到了
- 定时任务调度:使用DelayQueue保存当天将会执行的任务和执行时间,一旦从DelayQueue中获取到任务就开始执行,比如TimeQueue就是使用DelayQueue实现的
SynchronousQueue
SynchronousQueue是一个不存储元素的阻塞队列。每一个put操作必须等待一个take操作,否则不能继续添加元素。
它支持公平访问队列,默认情况下现场采用非公平性策略访问队列。使用以下构造方法可以创建公平性访问SynchronousQueue,如果设置成true,则等待的线程会采用先进先出的顺序访问队列。SynchronousQueue可以看成是一个传球手,负责把生产者线程处理的数据直接传递给消费者线程。队列本身并不存储任何元素,非常适合传递性创建。SynchronousQueue的吞吐量高于LinkedBlockingQueue和ArrayBlockingQueue
LinkedTransferQueue
LinkedTransferQueue是一个由链表结构组成的无界阻塞TransferQueue队列。相对于其他阻塞队列,LinkedTransferQueue多了tryTransfer和transfer方法
(1)tryTransfer
tryTransfer方法是用来试探生产者传入的元素是否能直接传给消费者。如果没有消费者等待接受元素,则返回false。和transfer方法的区别是tryTransfer方法无论消费者是否接受,方法立即返回,而transfer方法是必须等到消费者消费了才返回。
对于带有时间限制的tryTransfer(E e,long timeout, TimeUnit unit)方法,试图把生产者传入的元素直接传给消费者,但是如果没有消费者消费该元素则等待知道的时间再返回,如果超时还没有消费元素则返回false,反之返回true
(2)transfer
如果当前有消费者正在等待接受元素(消费者使用take()方法或带时间限制的poll()方法),transfer方法可以把生产者传入的元素立刻transfer(传输)给消费者。如果没有消费者在等待接受元素,transfer方法将会存放在队列的tail节点,并等到该元素被消费者消费了才返回。
LingkedBlockingDeque
LingkedBlockingDeque是一个由链表结构组成的双向阻塞队列。所谓双向队列指的是可以从队列的两端插入和移出元素,双向队列因为多了一个操作队列的入口,在多线程同时入队时,也就减少了一半的竞争。相比其他阻塞队列,LingkedBlockingDeque多了addFirst,addLast,offerFirst,offerLast,peekFirst和peekLast等方法,以First单词结尾的方法,表示插入。获取(peek)或移除双端队列的第一个元素。以Last单词结尾的方法,表示插入、获取或移除双端队列的最后一个元素。另外,插入方法add等同于addLast,移除方法remove等效于removeFirst。但是take方法却等同于takeFirst,不知道是不是JDK的bug,使用时还是用带有First和Last后缀的方法更清楚。
在初始化LingkedBlockingDeque时可以设置容量防止其过度膨胀。另外,双向阻塞队列可以运用在“工作窃取”模式中
阻塞队列的实现原理
如果队列是空的,消费者会一直等待,当生产者添加元素时,消费者是如何知道当前队列有元素的呢?
使用通知模式实现。所谓通知模式,就是当生产者往满的队列里添加元素时会阻塞住生产者,当消费者消费了一个队列中的元素后,会通知生产者当前队列可用。通过查看JDK源码发现ArrayBlockingQueue使用了Condition来实现
/** Condition for waiting takes */
private final Condition notEmpty; /** Condition for waiting puts */
private final Condition notFull; public ArrayBlockingQueue(int capacity, boolean fair) {
if (capacity <= 0)
throw new IllegalArgumentException();
this.items = new Object[capacity];
lock = new ReentrantLock(fair);
notEmpty = lock.newCondition();
notFull = lock.newCondition();
} /**
* Inserts the specified element at the tail of this queue, waiting
* for space to become available if the queue is full.
*
* @throws InterruptedException {@inheritDoc}
* @throws NullPointerException {@inheritDoc}
*/
public void put(E e) throws InterruptedException {
checkNotNull(e);
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == items.length)
notFull.await();
enqueue(e);
} finally {
lock.unlock();
}
} public E take() throws InterruptedException {
final ReentrantLock lock = this.lock;
lock.lockInterruptibly();
try {
while (count == 0)
notEmpty.await();
return dequeue();
} finally {
lock.unlock();
}
} /**
* Inserts element at current put position, advances, and signals.
* Call only when holding lock.
*/
private void enqueue(E x) {
// assert lock.getHoldCount() == 1;
// assert items[putIndex] == null;
final Object[] items = this.items;
items[putIndex] = x;
if (++putIndex == items.length)
putIndex = 0;
count++;
notEmpty.signal();
}
Fork/Join框架
什么是Fork/Join框架
Fork/Join框架是Java7提供的一个用于并行执行任务的框架,是一个把大任务分割成若干个小任务,最终汇总每个小任务结果后得到大任务结果的框架。
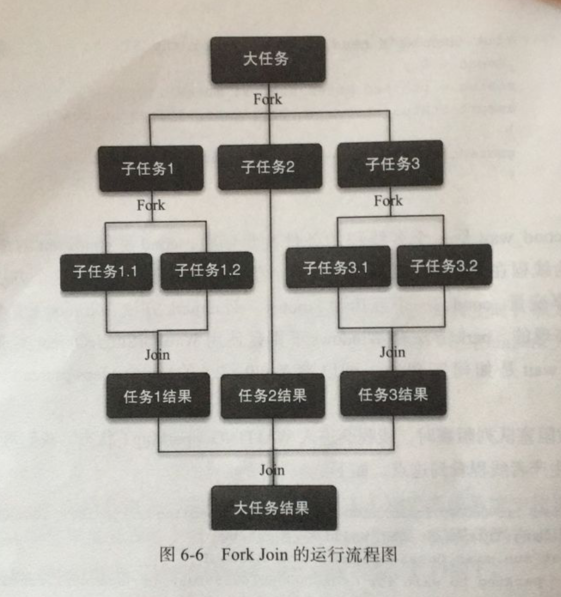
工作窃取算法
工作窃取算法(work-stealing)是指某个线程从其他队列里窃取任务来执行。
优点:充分利用线程进行并行计算,减少了线程间的竞争
缺点:在某些情况下还是存在竞争,比如双端队列里只有一个任务时。并且该算法会消耗了更多的系统资源,比如创建多个线程和多个双端队列
Fork/Join框架的设计
步骤1:分割任务。首先我们需要有一个fork类来把大任务分割成子任务,有可能子任务还是很大,所以还需要不停地分割,直到分割出的子任务足够小
步骤2:执行任务并合并结果。分割的子任务分别放在双端队列里,然后几个启动线程分别从双端队列里获取任务执行。子任务执行完的结果都统一放在一个队列里,启动一个线程从队列里拿数据,然后合并这些数据
Fork/Join使用两个类来完成以上两个事情。
- ForkJoinTask:我们要使用Fork/Join框架,必须首先创建一个Fork/Join任务。它提供在任务中执行fork()和join()操作的机制。通常情况下,我们不需要直接继承ForkJoinTask类,只需要继承它的子类,Fork/Join框架提供了以下两个子类
- RecursiveAction:用于没有返回结果的任务
- RecursiveTask:用于有返回结果的任务
- ForkJoinPool:ForkJoinTask需要通过ForkJoinPool来执行
任务分割出的子任务会添加到当前工作线程所维护的双端队列中,进入队里的头部。当一个工作线程的队列里暂时没有任务时,它会随机从其他工作线程的队列的尾部获取一个任务。
Fork/Join框架的异常处理
ForkJoinTask在执行的时候可能会抛出异常,但是我们没办法在主线程里直接捕获异常,所有ForkJoinTask提供了isCompletedAbnormally()方法来检查任务是否已经抛出异常或已经被取消了,并且可以通过ForkJoinTask的getException方法获取异常。getException方法返回Throwable对方,如果任务被取消了则返回CancellationException。如果任务没有完成或者没有抛出异常则返回null
Fork/Join框架的实现原理
ForkJoinPool由ForkJoinTask数组和ForkJoinWorkerThread数组组成,ForkJoinTask数组负责将存放程序提交给ForkJoinPool的任务,而ForkJoinWorkerThread数组负责执行这些任务
(1)ForkJoinTask的fork方法实现原理
当我们调用ForkJoinTask的fork方法时,程序会调用ForkJoinWorkerThread的pushTask方法异步地执行这个任务,然后立即返回结果。pushTask方法把当前任务存放在ForkJoinTask数组队列里。然后再调用ForkJoinPool的signalWork()方法唤醒或创建一个工作线程来执行任务。
(2)ForkJoinTask的join方法实现原理
join方法的主要作用是阻塞当前线程并等待获取结果。首先它调用了doJoin()方法,通过doJoin()方法得到当前任务的状态来判断返回什么结果,任务状态有4种:已完成(NORMAL)、被取消(CANCELLED)、信号(SIGNAL)和出现异常(EXCEPTIONAL)
- 如果任务状态是已完成,则直接返回任务结果
- 如果任务状态是被取消,则直接抛出CancellationException
- 如果任务时抛出异常,则直接抛出对应异常
在doJoin()方法里,首先通过查看任务的状态,看任务是否已经执行完成,如果执行完成,则直接返回任务状态;如果没有执行完,则从任务数组里取出任务并执行。如果任务顺利执行完成,则设置任务状态为NORMAL,如果出现异常,则记录异常。并将任务状态设置为EXCEPTIONAL
使用 Fork/Join框架
让我们通过一个简单的需求来使用Fork/Join框架,需求是:计算1+2+3+4的结果
使用Fork/Join框架首先要考虑到时如何分割任务,如果希望每个子任务最多执行两个数相加,那么我们设置分割的阙值是2,由于是4个数字相加,所以Fork/Join框架会把这个任务fork成两个子任务,子任务一负责计算1+2,子任务而负责3+4,然后join两个子任务的结果。因为是有结果的任务,所以必须继承ResursiveTask,实现代码如下:
public class CountTask extends RecursiveTask<Integer> {
private static final int THRESHOLD = 2;//阙值
private int start;
private int end;
public CountTask(int start, int end){
this.start = start;
this.end = end;
}
@Override
protected Integer compute() {
int sum = 0;
//如果任务足够小就计算任务
boolean canCompute = (end - start) <= THRESHOLD;
if(canCompute){
for (int i = start; i <= end; i++) {
sum += i;
}
}else {
//如果任务大于阙值,就分裂成两个子任务计算
int middle = (start + end) / 2;
CountTask leftTask = new CountTask(start, middle);
CountTask rightTask = new CountTask(middle + 1, end);
//执行子任务
leftTask.fork();
rightTask.fork();
//等待子任务执行完,并得到其结果
int leftResult = leftTask.join();
int rightResult = rightTask.join();
//合并子任务
sum = leftResult + rightResult;
}
return sum;
}
public static void main(String[] args) {
ForkJoinPool forkJoinPool = new ForkJoinPool();
//生成一个计算任务,负责计算1+2+3+4
CountTask countTask = new CountTask(1, 4);
//执行一个任务
Future<Integer> result = forkJoinPool.submit(countTask);
try {
System.out.println(result.get());
}catch (InterruptedException e){
}catch (ExecutionException e){
}
}
}
通过这个例子,我们进一步理解ForkJoinTask,ForkJoinTask与一般任务的主要区别在于它需要实现compute方法,在这个方法里,首先需要判断任务是否足够小,如果足够小就直接执行任务。反之就必须分割成两个子任务,每个子任务在调用fork方法时,又会进入compute方法,看着当前子任务是否需要继续分割成子任务,如果不需要继承分割,则执行当前子任务并返回结果。使用join方法会等待子任务执行完并得到其结果。
第六章 Java并发容器和框架的更多相关文章
- 《Java并发编程的艺术》第6/7/8章 Java并发容器与框架/13个原子操作/并发工具类
第6章 Java并发容器和框架 6.1 ConcurrentHashMap(线程安全的HashMap.锁分段技术) 6.1.1 为什么要使用ConcurrentHashMap 在并发编程中使用Has ...
- JAVA并发编程的艺术 Java并发容器和框架
ConcurrentHashMap ConcurrentHashMap是由Segment数组结构和HashEntry数组结构组成. 一个ConcurrentHashMap里包含一个Segment数组, ...
- Java并发容器和框架
ConcurrentHashMap 在多线程环境下,使用HashMap进行put操作会引起死循环,导致CPU利用率近100%.因为多线程会导致HashMap的Entry链表形成环形数据结构,一旦形成环 ...
- Java 并发编程——Executor框架和线程池原理
Eexecutor作为灵活且强大的异步执行框架,其支持多种不同类型的任务执行策略,提供了一种标准的方法将任务的提交过程和执行过程解耦开发,基于生产者-消费者模式,其提交任务的线程相当于生产者,执行任务 ...
- Java 并发编程——Executor框架和线程池原理
Java 并发编程系列文章 Java 并发基础——线程安全性 Java 并发编程——Callable+Future+FutureTask java 并发编程——Thread 源码重新学习 java并发 ...
- (转)java并发编程--Executor框架
本文转自https://www.cnblogs.com/MOBIN/p/5436482.html java并发编程--Executor框架 只要用到线程,就可以使用executor.,在开发中如果需要 ...
- 【Java 并发】Executor框架机制与线程池配置使用
[Java 并发]Executor框架机制与线程池配置使用 一,Executor框架Executor框架便是Java 5中引入的,其内部使用了线程池机制,在java.util.cocurrent 包下 ...
- java 并发容器一之BoundedConcurrentHashMap(基于JDK1.8)
最近开始学习java并发容器,以补充自己在并发方面的知识,从源码上进行.如有不正确之处,还请各位大神批评指正. 前言: 本人个人理解,看一个类的源码要先从构造器入手,然后再看方法.下面看Bounded ...
- Java并发编程系列-(5) Java并发容器
5 并发容器 5.1 Hashtable.HashMap.TreeMap.HashSet.LinkedHashMap 在介绍并发容器之前,先分析下普通的容器,以及相应的实现,方便后续的对比. Hash ...
随机推荐
- js动态添加和删除标签
html代码 <h1>动态添加和删除标签</h1> <div id="addTagTest"> <table> <thead& ...
- 解决fasterxml中string字符串转对象json格式错误问题
软件152 尹以操 springboot中jackson使用的包是fasterxml的.可以通过如下代码,将一个形如json格式string转为一个java对象: com.fasterxml.jack ...
- Flume-NG启动过程源码分析(三)(原创)
上一篇文章分析了Flume如何加载配置文件的,动态加载也只是重复运行getConfiguration(). 本篇分析加载配置文件后各个组件是如何运行的? 加载完配置文件订阅者Application类会 ...
- [eBook]Inside Microsoft Dynamics AX 2012 R3发布
最近一本关于Microsoft Dynamics AX 2012开发的书<Inside Microsoft Dynamics AX 2012 R3> 发布. Book Descriptio ...
- Hive数据导入——数据存储在Hadoop分布式文件系统中,往Hive表里面导入数据只是简单的将数据移动到表所在的目录中!
转自:http://blog.csdn.net/lifuxiangcaohui/article/details/40588929 Hive是基于Hadoop分布式文件系统的,它的数据存储在Hadoop ...
- vue项目中如何将工具函数模块化导出
如下所示,utils文件夹下的js里都是封装好的工具函数, 如formatDate.js内容如下: export default (day)=>{ var tmpDate = day ? new ...
- 【.Net】Byte,Stream,File的转换
引言 文件的传输和读写通常都离不开Byte,Stream,File这个类,这里我简单封装一下,方便使用. 帮助类 public static class FileHelper { / ...
- BEC listen and translation exercise 6
能听懂自己的录音,说明发音还行,可惜听不懂... Another problem is that the members of the Biramichi fishing cooperative ar ...
- url字符串中含中文的转码方法
凡是用get方法的,url里含中文的,都需要调用上面的函数进行编码.要不然会被当成二进制截断. //URL编码 +(NSString*)urlEncode:(NSString *)str { int ...
- CCControlSwitch 、CCControlSlider、CCControlButton
/* *bool hasMoved(); 这里获取的不是开关是否正在被用户拨动,而是开关最终的状态是由用户手动拨动开关进行的, *还是用户点击开关进行的状态更改 */ CCControlSwitch* ...