Python之路【第四篇】:Python基础之函数
函数的理解
面向过程:根据业务逻辑从上到下垒代码
函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
函数作用是你的程序有良好的扩展性、复用性。
同样的功能要是用3次以上的话就建议使用函数。
特殊理解:
函数可以理解为一个一个的功能块,你把一个大的功能拆分成一块一块的,用某项功能的时候就去调用某个功能块即可!
函数可以理解为:乐高积木,给你一块一块的,你可以用这些积木块组成你想要的任何功能!
函数可以调用函数!主函数的作用就是把函数进行串联、调用!函数本身是不能自己执行的如果不调用就永不执行!
#---------------------------------------------------
def func1():
pass
def func2():
pass
def func3():
pass
def func4():
pass
func1()
func2()
func3()
func4() if __name__ == '__main__':
#调用上面的函数,判断了、循环了调用等!
#函数里也可以调用函数例子:def func4(): #__name__ 这个是用来判断,如果你是把这个程序当模块导入的话它的__name__就等于这个程序的文件名,如果是手动执行这个脚本比如:python test.py 那么__name__就等于__main__ 所以,我们可以用他来做判断,如果你是手动执行我就调用函数执行if下面的语句,如果你是调用模块下面的if判断后面的语句就不执行!仅当模块使用! #如果函数当模块导入的时候,他导入的是函数的名称,内容没有被导入,当你去调用的时候他才会导入函数里的信息。
自定义函数
一、背景
在学习函数之前,一直遵循:面向过程编程,即:根据业务逻辑从上到下实现功能,其往往用一长段代码来实现指定功能,开发工程中比较常见的操作就是粘贴复制,也就是将之前实现的代码块复制到现需功能处,如下:
while True:
if cpu利用率 > 90 %:
# 发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 if 硬盘使用空间 > 90%:
# 发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 if 内存占用 >80%:
# 发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
上面的代码就是面向过程的编程,但是如果报警多了的话成百的代码需要如何操作呢?复制粘贴就会显得自己low,该如何编写呢,请看下面的代码:
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接
while True:
if cpu利用率 > 90%:
发送邮件('CPU报警')
if 硬盘使用空间 > 90%:
发送邮件('硬盘报警')
if 内存占用 > 80%:
发送邮件('内存报警')
第二个必然比第一个的重用性和可读性要好,其实就是函数式编程和面向过程编程的区别:
● 面向过程:更具需求一行一行垒加代码!逻辑乱、并切代码重复、不易修改重用性差!
● 函数式:将某功能代码封装到函数中,日后便无需重复编写,仅调用函数即可
● 面向对象:对函数进行分类和封装,让开发"更快更好更强"
二、函数式编程
函数式编程最重要的是增强代码的重用性和可读性:
# 语法 def 函数(参数1,参数2,参数3,....):
' ' '注释' ' '
函数体
return 返回的值 #函数名的定义要能反映其意义
函数的定义主要有如下要点:
● def 表示函数的关键字
● 函数名:函数的名称,日后根据函数名调用函数
● 参数:为函数体提供数据
● 函数体:函数中进行一系列的逻辑计算,如,发送邮件、计算出[11,22,45,56,45,]中的最大数等....
● 返回值:当函数执行完毕后,可以给调用者返回数据。
函数使用的原则:先定义,后调用
函数即"变量","变量"必须先定义后引用,未定义而直接函数,就相当于在引用一个不存在的变量名 #测试一
def func():
print('from foo')
bar()
func() #报错 #测试二
def abc():
print('from abc')
def func():
print('from func')
abc()
func() #正常 #测试三
def func():
print('from func')
abc() def abc():
print('from abc')
func() #不会报错 #结论:函数的使用,必须遵循原则:先定义,后调用
#我们在使用函数时,一定要明确的区分定义阶段和调用阶段 #定义阶段:
def func():
print('from func')
abc() def abc():
print('from abc')
#调用阶段
func()
函数在定义阶段都干了哪些事?
#只检测语法,不执行代码
也就说,语法错误在函数定义阶段就会检测出来,而代码的逻辑错误只有在执行的时候才会知道
定义函数的三种形式
#1、无参:应用场景仅仅只是执行一些操作,比如与用户交互,打印
#2、有参:需要根据外部传进来的参数,才能执行相应的逻辑,比如统计长度,求最大值最小值
#3、空函数:设计代码结构
1、返回值
函数式一个功能块,该功能到底执行成功与否,需要通过返回值来告知调用者。
def test():
'''
2*x+1
:param x:整形数字
:return: 返回计算结果
'''
x=3
y=2*x+1
return y a = test()
print(a)
def 发送短信():
发送短信的代码..: if 发送成功:
return True
else:
return False while True:
# 每次执行发送短信函数,都会将返回值自动赋值给result
# 之后,可以根据result来写日志,或重发等操作 result = 发送短信()
if result == False:
记录日志,短信发送失败....
2、参数
1、形参与实参
#形参即变量名,实参即变量值,函数调用时,将值绑定到变量名上,函数调用结束,解除绑定
2、具体应用
#1、位置参数:按照从左到右的顺序定义的参数
位置形参:必选参数
位置实参:按照位置给形参传值
#2、关键字参数:安装key=value的形式定义的实参
无需按照位置为形象传值
注意的问题:
1、关键字实参必须在位置实参右面
2、对同一个形参不能重复传值
#3、默认参数:形参在定义时就已经为其赋值
可以传值也可以不传值,经常需要变得参数定义成位置形参,变成较小的参数定义成默认参数(形参)
注意的问题:
1、只在定义时赋值一次
2、默认参数的定义应该在位置形参右面
3、默认参数通常应该定义成不可变类型
#4、可变长参数:
可变长指的是实参值的个数不固定
而实参有按位置和按关键字两种形式定义,针对这两种形式的可变长,形参对应有两种解决方案来完整地存放它们,分别是*args,**kwargs # ########### *args ####################
def foo(x,y,*args):
print(x,y)
print(args)
foo(1,2,3,4,5)
输出结果:
C:\Python35\python3.exe C:/Users/ZR/PycharmProjects/python全栈开发/day15/def函数.py
1 2
(3, 4, 5) def foo(x,y,*args):
print(x,y)
print(args)
foo(1,2,*[3,4,5])
输出结果:
1 2
(3, 4, 5) def foo(x,y,z):
print(1,2,3)
foo(*[1,2,3])
输出结果:
1 2 3
# ############ **kwargs ###################
def foo(x,y,**kwargs):
print(x,y)
print(kwargs)
foo(1,y=2,a=1,b=2,c=3)
输出结果:
1 2
{'c': 3, 'a': 1, 'b': 2} def foo(x,y,**kwargs):
print(x,y)
print(kwargs)
foo(1,y=2,**{'a':1,'b':2, 'c':3})
输出结果: #更上面输出结果相同,只不过位置有所变化
1 2
{'a': 1, 'b': 2, 'c': 3} def foo(x,y,z):
print(x, y, z)
foo(**{'z':1,'x':2,'y':3})
输出结果:
2 3 1 # ##### *args + **kwargs############
def foo(x,y):
print(x,y) def wrapper(*args,**kwargs):
print('==========>')
foo(*args,**kwargs)
#5、命名关键字参数:*后定义的参数,必须被传值(有默认值的除外),且必须按照关键字实参的形式传递 def foo(x,y,*args,a=1,b,**kwargs):
print(x,y)
print(args)
print(a)
print(b)
print(kwargs)
foo(1,2,3,4,5,b=3,c=4,d=5)
输出结果:
1 2
(3, 4, 5)
1
3
{'c': 4, 'd': 5}
为什么要用参数?举例说明
如果不定义参数,用函数的话:(每个有相同功能的都写个函数,说好的代码简化呢?)
def cpu报警邮件():
# 发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 def 硬盘报警邮件():
# 发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 def 内存报警邮件():
# 发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 while True:
if CPU利用率 > 90%:
cpu报警邮件()
if 硬盘使用空间 > 90%:
硬盘报警邮件()
if 内存占用 > 80%:
内存报警邮件()
使用函数:(代码明显少了很多,把重复内用改为参数调用!)
def 发送邮件(内容)
#发送邮件提醒
连接邮箱服务器
发送邮件
关闭连接 while True: if cpu利用率 > 90%:
发送邮件('CPU报警') if 硬盘使用空间 > 90%:
发送邮件('硬盘报警') if 内存占用 > 80%:
发送邮件('内存报警')
函数的四种不同的参数:
1、普通参数
2、默认参数
3、动态参数
普通参数:
# #### 定义函数 ###############
# name 叫做函数func的形式参数,简称:形参
def func(name):
print(name) # #### 执行函数 ###############
# 'zhurui' 叫做函数func的实际参数,简称:实参
func('zhurui')
但是普通参数有个问题!你在定义参数的时候定义了几个参数,你在调用的时候必须给他几个参数否则会报错!
def func(name,age):
print(name,age) func('william') 报错提示:
TypeError: func() missing 1 required positional argument: 'age' 其正确的写法是:
def func(name,age):
print(name,age) func('william',24) 输出结果:
william 24
默认参数:
在你没有给他指定参数的时候它就会使用默认参数!
def func(name, age = 24):
print('%s:%s' %(name,age)) # 指定参数:
func('william', 32)
输出结果:
william:24 # 使用默认参数
func('william')
输出结果:
william:27
三、局部变量与全局变量
在子程序中定义的变量成为局部变量,在程序的一开始定义的变量称为全局变量。
全局变量作用域是整个程序,局部变量作用域是定义该变量的子程序。
当全局变量与局部变量同名时:
在定义局部变量的子程序内,局部变量起作用;在其他地方全局变量起作用。
name='simon' #全局变量 def change_name():
name='牛逼的人物' #局部变量
print('change_name',name) change_name()
print(name)
输出结果:
C:\Python35\python3.exe G:/python_s3/day15/全局变量与局部变量.py
change_name 牛逼的人物
simon #输出结果要想让全局变量改变成局部变量需要在作用域中加 global name,相当于指针跟引用
代码如下:
name='simon' #全局变量 def change_name():
global name
name='牛逼的人物' #局部变量
print('change_name',name) change_name()
print(name) 输出结果:
C:\Python35\python3.exe G:/python_s3/day15/全局变量与局部变量.py
change_name 牛逼的人物
牛逼的人物
name = 'simon'
def test1():
#name = '孙悟空'
global name #将全局变量引用过来,已经声明,name就是全局的那个变量
print('我要搞', name)
def test2():
name = '基'
print('我要搞', name)
#如果函数的内部无 global关键字,优先读取局部变量,能读取全局变量,无法对全局变量重新赋值 NAME='fff',但是对于可变类型,可以对内部元素进行操作
#如果函数中有global关键字,变量本质上就是全局的那个变量,可读取可赋值
test1()
test2()
注意:
全局变量变量名大写
局部变量变量名小写
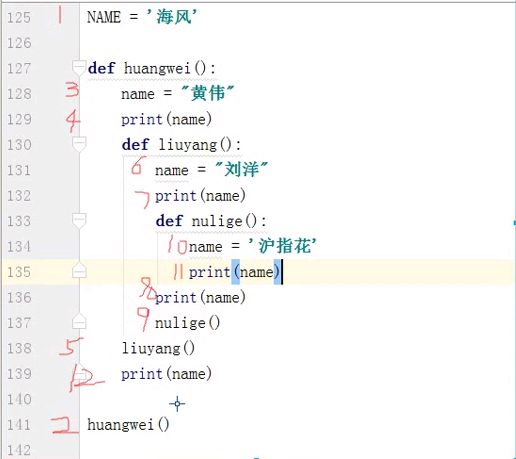
def huangwei():
name = '黄伟'
print(name)
def liuyang():
name = '刘洋'
print(name)
def nulige():
name = '沪指花'
print(name)
print(name)
nulige()
liuyang()
print(name) huangwei()
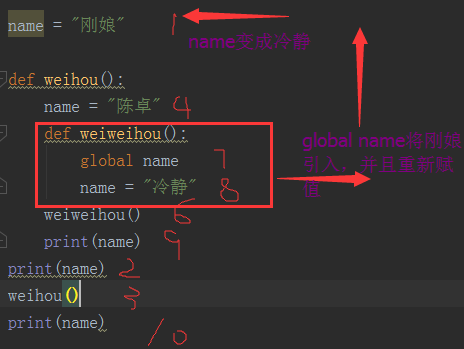
def weihou():
name = "陈卓"
def weiweihou():
global name
name = "冷静"
weiweihou()
print(name)
print(name)
weihou()
print(name) 输出结果: C:\Python35\python3.exe G:/python_s3/day15/全局变量与局部变量.py
刚娘
陈卓
冷静
代码运行示例图:
使用nonlocal 指定上一级变量
name = "刚娘"
def weihou():
name = "陈卓"
def weiweihou():
nonlocal name #nonlocal,指定上一级变量
name = "冷静"
weiweihou()
print(name)
print(name)
weihou()
print(name) 运行结果:
C:\Python35\python3.exe G:/python_s3/day15/全局变量与局部变量.py
刚娘
冷静
刚娘
四、递归
在函数内部,可以调用其他函数。如果一个函数在内部调用自身
def calc(n):
print(n)
if int(n/2) == 0:
return n
return calc(int(n/2))
calc(10) 输出结果:
C:\Python35\python3.exe G:/python_s3/day15/全局变量与局部变量.py
10
5
2
1
__author__ = 'zhurui'
import time person_list=['zhurui','caiyunjie','yuanhao','simon','william','zcz']
def ask_way(person_list):
print('-'*60)
if len(person_list) == 0:
return '没人知道'
person=person_list.pop(0)
if person == 'simon':
return '%s说:我知道,东方财富网就在东方财富大厦A座,下肇嘉浜路地铁站就是' %person
print('hi 美男[%s],敢问路在何方' % person)
print('%s回答道:我不知道,但你慧眼识珠,我去帮你问问%s...' % (person,person_list) )
time.sleep(3)
res = ask_way(person_list)
print('%s问的结果是: %res' %(person,res))
return res res = ask_way(person_list)
print(res)
运行结果如下:
C:\Python35\python3.exe G:/python_s3/day15/全局变量与局部变量.py
------------------------------------------------------------
hi 美男[zhurui],敢问路在何方
zhurui回答道:我不知道,但你慧眼识珠,我去帮你问问['caiyunjie', 'yuanhao', 'simon', 'william', 'zcz']...
------------------------------------------------------------
hi 美男[caiyunjie],敢问路在何方
caiyunjie回答道:我不知道,但你慧眼识珠,我去帮你问问['yuanhao', 'simon', 'william', 'zcz']...
------------------------------------------------------------
hi 美男[yuanhao],敢问路在何方
yuanhao回答道:我不知道,但你慧眼识珠,我去帮你问问['simon', 'william', 'zcz']...
------------------------------------------------------------
yuanhao问的结果是: 'simon说:我知道,东方财富网就在东方财富大厦A座,下肇嘉浜路地铁站就是'es
caiyunjie问的结果是: 'simon说:我知道,东方财富网就在东方财富大厦A座,下肇嘉浜路地铁站就是'es
zhurui问的结果是: 'simon说:我知道,东方财富网就在东方财富大厦A座,下肇嘉浜路地铁站就是'es
simon说:我知道,东方财富网就在东方财富大厦A座,下肇嘉浜路地铁站就是 Process finished with exit code 0
递归特性:
1.必须有一个明确的结束条件
2.每次进入更深一层递归时,问题规模相比上次递归都应有所减少
3.递归效率不高,递归层次过多会导致栈溢出(在计算机中,函数调用是通过栈(stack)这种数据结构实现的,每当进入一个函数调用,栈就会加一层栈帧,每当函数返回,栈就会减一层帧。由于栈的大小不是无限的,所以,递归调用的次数过多,会导致栈溢出)
五、作用域
示例代码如下:
#1、作用域即范围
- 全局范围(内置名称空间与全局名称空间属于该范围):全局存活,全局有效
- 局部范围(局部名称空间属于该范围):临时存活,局部有效
#2、作用域关系是在函数定义阶段就已经固定的,与函数的调用位置无关,如下
x = 1
def f1():
def f2():
print(x)
return f2
x = 100
def f3(func):
x=2
func()
x = 10000
f3(f1()) 结果:
C:\Python35\python3.exe G:/python_s3/day16/作用域.py
10000 #3、查看作用域:globals(),locals() LEGB 代表名字查找顺序: locals -> enclosing function -> globals -> __builtins__
locals 是函数内的名字空间,包括局部变量和形参
enclosing 外部嵌套函数的名字空间(闭包中常见)
globals 全局变量,函数定义所在模块的名字空间
builtins 内置模块的名字空间
六、匿名函数
代码如下:
#1、 代码方式一
def calc(x):
return x+1
res = calc(10)
print(res)
输出结果为:
C:\Python35\python3.exe G:/python_s3/day16/匿名函数.py
11 #2、用lambda方式表达
print (lambda x:x+1) #代表单纯的输出内存地址
func=lambda x:x+1
print (func(10))
输出结果为:
<function <lambda> at 0x00000000006EE0D0>
11
#表达方式1
name = 'simon'
def change_name(x):
return name+'_sb' res = change_name(name)
print(res) #lambda方式表达:
name='simon'
func = lambda x:x+'_sb'
print(func(name)) 输出结果:
C:\Python35\python3.exe G:/python_s3/day16/匿名函数.py
simon_sb
simon_sb
匿名函数补充:
f = lambda x,y,z:(x+1,y+1,z+1)
print(f(1,2,3))
输出结果为:
C:\Python35\python3.exe G:/python_s3/day16/匿名函数.py
(2, 3, 4)
七、函数式编程
11 高阶函数
满足俩个特性任意一个即为高阶函数
1、函数的传入参数是一个函数名
2、函数的返回值是一个函数名
例一:不可变:不用变量保存状态,不修改变量
#非函数式
a = 1
def incr_test1():
global a
a+=1
return a
incr_test1()
print(a)
输出结果:
C:\Python35\python3.exe G:/python_s3/day16/匿名函数.py
2 #函数式
n=1
def incr_test2(n):
return n+1
print(incr_test2(2))
print (n) 输出结果:
C:\Python35\python3.exe G:/python_s3/day16/匿名函数.py
3
1
简单小结:
八、内置函数
#空,None,0的布尔值为False,其余都为True
print(bool(''))
print(bool(None))
print(bool(0))
C:\Python35\python3.exe G:/python_s3/day16/内置函数.py
False
False
False #bytes()函数,转换成二进制
name='你好'
print(bytes(name,encoding='utf-8'))
print(bytes(name,encoding='utf-8').decode('utf-8')) #decode是将前面处理的编码再解码,还原成原来
print(bytes(name,encoding='gbk'))
print(bytes(name,encoding='gbk').decode('gbk')) print(bytes(name,encoding='ascii')) #ascii不能编码中文
C:\Python35\python3.exe G:/python_s3/day16/内置函数.py
b'\xe4\xbd\xa0\xe5\xa5\xbd'
你好
b'\xc4\xe3\xba\xc3'
你好
max函数小结:
1、max函数处理的是可迭代对象,相当于一个for循环取出每个元素进行比较,注意,不同类型之间不能进行比较
2、每个元素间进行比较,是从每个元素的第一个位置依次比较,如果这一个位置分出大小,后面的都不需要比较了,直接得出这俩元素的大小
#空,None,0的布尔值为False,其余都为True
# print(bool(''))
# print(bool(None))
# print(bool(0)) # #bytes()函数,转换成二进制
# name='你好'
# print(bytes(name,encoding='utf-8'))
# print(bytes(name,encoding='utf-8').decode('utf-8')) #decode是将前面处理的编码再解码,还原成原来
# print(bytes(name,encoding='gbk'))
# print(bytes(name,encoding='gbk').decode('gbk'))
#
# print(bytes(name,encoding='ascii')) #ascii不能编码中文 #chr()函数
# print(chr(97))
# print(dir(dict))
# print(divmod(10,36))
# dic ={'name':'alex'}
# print(dic)
# #可hash的数据类型即不可变类型,不可hash的类型即可变数据类型
# name='simon'
# print(hash(name)) # print(help(all))
#
# print(bin(10)) #10进制->2进制
# print(hex(12))
# print(oct(12)) #10进制转8进制
#
# print(isinstance(1,int)) # l=[1,3,100,-1,-2,4]
# print(max(l))
# print(min(l)) #zip()函数,相当于拉链的作用
# print(list(zip(('a','b','c'),(1,2,3))))
# print(list(zip(('a','b','c'),(1,2,3))))
# print(list(zip(('a','b','c','d'),(1,2,3))))
#
# p={'name':'alex','age':18,'gender':'none'}
# print(list(zip(p.keys(),p.values()))) #不加list,只会输出内存地址
# # print(list(p.keys()))
# # print(list(p.values()))
#
# print(list(zip('hello','12345'))) #zip方法里传两个参数,都是序列类型(列表,元祖,字符串) # l=[1,3,100,-1,-2,4]
# print(max(l))
# print(min(l)) people=[
{'name':'alex','age':1000},
{'name':'wupeiqi','age':10000},
{'name':'yuanhao','age':9000},
{'name':'simon','age':18},
] print('-------->',max(people,key=lambda dic:dic['age'])) # age_dic={'age1':18,'age4':20,'age3':100,'age2':30}
# print(max(age_dic.values()))
# print((max(age_dic.keys()),max(age_dic.values()))) age_dic={'alex_age':18,'wupeiqi_age':20,'zsc_age':100,'lhf_age':30}
# print(max(age_dic.values()))
#默认比较的是字典的key
# print(max(age_dic)) # for item in zip(age_dic.values(),age_dic.keys()): #(18.'alex_age') (20,'wupeiqi_age')
# print(item) # print(list(max(zip(age_dic.values(),age_dic.keys()))))
#
# l = [
# (5,'e'),
# (1,'b'),
# (3,'a'),
# (4,'d'),
# ]
# print(list(max(l)))
# # l1=['a10','b12','c10',100] #不同类型之间不能进行比较
# l1=['a10','b12','c10'] #不同类型之间不能进行比较
# print(list(max(l)))
# print(max(l1)) #总结
#1、max的比较,传入的类型为可迭代类型
#2、max的比较,从第一个位置开始比较,如果已经比较出大小,不会再比较后面的位置,直接输出结果 # print(chr(97))
# print(ord('a')) #pow()函数:
print(pow(2,3)) #2**3
print(pow(3,3,2)) #3**3/2 #reversed()函数,使结果反转
# l=[1,2,3,4]
# print(list(reversed(l)))
#
# #round()函数:四舍不入函数
# print(round(3.5))
#
# #set()函数:
# print(set('hello')) #selict()函数:切片
# l='hello'
# # print(l[3:5])
# s1=slice(3,5)
# s2=slice(1,4,2)
# print(l[s1])
# print(l[s2])
# print(s2.start)
# print(s2.stop)
# print(s2.step) #sorted()函数: # l=[3,2,1,5,7]
# l1=[3,2,'a',1,5,7]
# print(sorted(l))
# print(sorted(l1)) #程序本质就是在比较大小,不同类型之间不可以比较大小 people=[
{'name':'alex','age':1000},
{'name':'wupeiqi','age':10000},
{'name':'yuanhao','age':9000},
{'name':'simon','age':18},
] print(sorted(people,key=lambda dic:dic['age'])) name_dic={
'abyuanhao':900,
'alex':200,
'wupei':300,
} print(sorted(name_dic))
print(sorted(name_dic,key=lambda key:name_dic[key]))
print(sorted(zip(name_dic.values(),name_dic.keys()))) #str()函数
print(str('l'))
print(str({'a':1})) #sum()函数
l=[1,2,3,4]
print(sum(l))
print(sum(range(5)))
p=range(10)
print(sum(p)) #type()函数
l=[1,2,3,4]
print('>>>>>>>',type(l)) msg='123'
if type(msg) is str:
msg=int(msg)
msg+=1
print(msg) #var()函数 def test():
msg='人么容量为进入高温热将来惹我居然我给我'
# print(locals())
print(vars())
test() #import ----->sys-------->__import__()
#__import__()函数: #可以导入字符串
# import 'test' #不能导入字符串
Python之路【第四篇】:Python基础之函数的更多相关文章
- python之路第四篇(基础篇)
一.冒泡算法实现: 方法一: li = [13,33,12,80,66,1] print li for m in range(4): num1 = li[m] num2 = li[m+1] if nu ...
- 【Python之路】第九篇--Python基础之线程、进程和协程
进程与线程之间的关系 线程是属于进程的,线程运行在进程空间内,同一进程所产生的线程共享同一内存空间,当进程退出时该进程所产生的线程都会被强制退出并清除.线程可与属于同一进程的其它线程共享进程所拥有的全 ...
- Python之路第四天,基础(4)-装饰器,迭代器,生成器
装饰器 装饰器(decorator)是一种高级Python语法.装饰器可以对一个函数.方法或者类进行加工.在Python中,我们有多种方法对函数和类进行加工,比如在Python闭包中,我们见到函数对象 ...
- 【Python之路】第一篇--Linux基础命令
pwd 命令 查看”当前工作目录“的完整路径 pwd -P # 显示出实际路径,而非使用连接(link)路径:pwd显示的是连接路径 . 表示当前目录 .. 表示上级目录 / 表示根目录 ls ...
- Python之路(第四篇):Python基本数据类型列表、元组、字典
一.列表 1.列表 list ,是一个类,li = [1,2,"nicholas"] li是通过list类创建的对象. 2.list特点: 用中括号括起来,用逗号分割每个元素,列表 ...
- Python之路(第八篇)Python内置函数、zip()、max()、min()
一.python内置函数 abs() 求绝对值 例子 print(abs(-2)) all() 把序列中每一个元素做布尔运算,如果全部都是true,就返回true, 但是如果是空字符串.空列表也返回t ...
- Python之路(第五篇) Python基本数据类型集合、格式化、函数
一.变量总结 1.1 变量定义 记录某种状态或者数值,并用某个名称代表这个数值或状态. 1.2 变量在内存中的表现形式 Python 中一切皆为对象,数字是对象,列表是对象,函数也是对象,任何东西都是 ...
- 【Python之路】特别篇--Python正则表达式
正则表达式的基础 正则表达式并不是Python的一部分. 正则表达式是用于处理字符串的强大工具,拥有自己独特的语法以及一个独立的处理引擎,效率上可能不如str自带的方法,但功能十分强大. 得益于这一点 ...
- 【Python之路】特别篇--Python面向对象(进阶篇)
上一篇<Python 面向对象(初级篇)>文章介绍了面向对象基本知识: 面向对象是一种编程方式,此编程方式的实现是基于对 类 和 对象 的使用 类 是一个模板,模板中包装了多个“函数”供使 ...
- Python之路(第七篇)Python作用域、匿名函数、函数式编程、map函数、filter函数、reduce函数
一.作用域 return 可以返回任意值例子 def test1(): print("test1") def test(): print("test") ret ...
随机推荐
- Thread部分总结以及小例子
Thread总结:一直以来用thread比较多,一般会在同步以及ui中用到.以下对于经常用作为简单介绍.一 实现方法: 一种直接new thread,另外一种是实现Runnable接口,在创建thre ...
- 写个批处理脚本来帮忙干活--遍历文件夹&字符串处理
这次打算写几篇关于脚本方面的博客,主要是记录一下 Gradle 脚本和批处理脚本的一些写法,方便后续查阅. 前言 平常开发过程中,一些较为重复的手工性工作,如果能让脚本来帮忙处理,自然是最好的,刚好之 ...
- 基于 WebRTC 创建一款多人联机游戏
本项目的目标旨在尽可能少用服务器资源的前提下研发一款在线多人游戏,同时期望在一个用户的浏览器上运行游戏,同时让另一个玩家来连接.此外还希望程序尽可能简单以便于在博客中分析. 运用的技术 在我刚接触 P ...
- QM5_Didstribution
Basic Concepts Probability distribution Discrete distribution (离散分布) The distribution of the discret ...
- 获得指定数据库中指定块表中所有实体的id
该函数也使用外部指定图纸中的数据库中的块 Int getIdsByDwgBlkName(AcDbDatabase *pDwg, CString strBlkName, AcDbObjectIdArra ...
- 【bzoj1758】[Wc2010]重建计划
Description Input 第一行包含一个正整数N,表示X国的城市个数. 第二行包含两个正整数L和U,表示政策要求的第一期重建方案中修建道路数的上下限 接下来的N-1行描述重建小组的原有方案, ...
- bzoj 4565 状压区间dp
我还以为我状压很好...... 噗!!! 果然我区间很差... f[i][j][s]表示i~j段,合并后的状态为s所得的最大收益 枚举i,j,k,s. f[i][j][s<<1]=max( ...
- BZOJ_2946_[Poi2000]公共串_后缀数组+二分答案
BZOJ_2946_[Poi2000]公共串_后缀数组+二分答案 Description 给出几个由小写字母构成的单词,求它们最长的公共子串的长度. 任务: l 读入单 ...
- BZOJ_3307_雨天的尾巴_线段树合并+树上差分
BZOJ_3307_雨天的尾巴_线段树合并 Description N个点,形成一个树状结构.有M次发放,每次选择两个点x,y 对于x到y的路径上(含x,y)每个点发一袋Z类型的物品.完成 所有发放后 ...
- C#进度框
1.方法一:使用线程 功能描述:在用c#做WinFrom开发的过程中.我们经常需要用到进度条(ProgressBar)用于显示进度信息.这时候我们可能就需要用到多线程,如果不采用多线程控制进度条,窗口 ...