MySQL入门笔记(二)
MySQL的数据类型、数据库操作、针对单表的操作以及简单的记录操作可参考:MySQL入门笔记(一)
五、子查询
子查询可简单地理解为查询中的查询,即子查询外部必然还有一层查询,并且这里的查询并非仅仅指SELECT的查询操作,而是包括INSERT、DELETE、SET等操作在内的所有操作。
1. 使用比较运算符的子查询
operand comparison_operator [{ANY | SOME | ALL}] (subquery)
operand为操作数,即参与比较运算的数;在语句的最后为subquery子查询,子查询必须写在小括号内;ANY、SOME与ALL关键字用于子查询返回结果不唯一的情况,下面通过例子说明几个关键字的作用。
例:存在下表test
+----+---------+------+| id | name | age |+----+---------+------+| 1 | John | 20 || 2 | Kity | 24 || 3 | Tommy | 26 || 4 | Jackson | 31 || 5 | Pat | 19 || 6 | Darling | 33 || 7 | Tamzin | 29 || 8 | Hoking | 21 || 9 | Obama | 22 || 10 | Bush | 25 |+----+---------+------+
现需要查询年龄大于平均值的的人,按照普通的方法,则需要先计算出年龄平均值SELECT AVG(age) FROM test;(结果为25.0000),再根据输出的结果进行查询SELECT * FROM test WHERE age > 25;;若使用子查询,则可将两步合为一步:
SELECT * FROM test WHERE age > (SELECT AVG(age) FROM test);
这就是子查询,而ANY、SOME以及ALL关键字的作用则是,当子查询返回的结果存在多条记录时,规定其比较方法,例如,现在要查询比id<=3的记录中任意一记录的age小的记录:
SELECT * FROM test WHERE age < ANY (SELECT age FROM test WHERE id <= 3);
SOME的作用与ANY相同,而ALL则是如其含义一般的“全部”,例如在上面的例子中,若将ANY改成ALL,则返回的结果的age必须大于id<=3的全部记录的age。
2. 使用[NOT] IN 的子查询
operand [NOT] IN (subquery)
[NOT] IN的作用为检测某些记录是否存在指定表中,其中IN等效于= ANY;NOT IN等效于!= ALL或者<> ALL。
例:以下两个语句结果完全一样:
SELECT * FROM test WHERE age = ANY (SELECT age FROM test WHERE id <= 3);SELECT * FROM test WHERE age IN (SELECT age FROM test WHERE id <= 3);
3. 使用[NOT] EXISTS的子查询
若子查询返回任意行,EXISTS返回1;否则为0。
例:以下操作返回结果则为0:
SELECT EXISTS (SELECT age FROM test WHERE id < 0);
六、多表操作
1. 连接
table_reference {[INNER|CROSS]JOIN | {LEFT|RIGHT}[OUTER]JOIN} table_reference ON conditional_expr
连接,如其字面含义,连接多个数据表,使其产生物理上的关系(即实际存在关系,而非仅仅为逻辑上的关系)。ON关键字用于设定其后的连接条件;{[INNER|CROSS]JOIN | {LEFT|RIGHT}[OUTER]JOIN}为连接类型,分别是INNER JOIN内连接、LEFT [OUTER] JOIN左外连接和RIGHT [OUTER] JOIN右外连接三种:
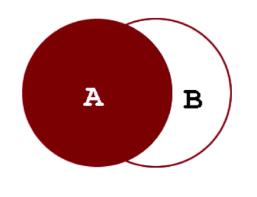
内连接为仅返回符合连接条件的记录,如下图所示,内连接返回的结果为两表的交集部分。其中JOIN、INNER JOIN和CROSS JOIN作用相同,均表示内连接。

例:存在以下两表:
users:
+----+---------+------+----------+| id | name | age | location |+----+---------+------+----------+| 1 | John | 20 | 3 || 2 | Kity | 24 | 3 || 3 | Tommy | 26 | 4 || 4 | Jackson | 31 | 3 || 5 | Pat | 19 | 4 || 6 | Darling | 33 | 2 || 7 | Tamzin | 29 | 2 || 8 | Hoking | 21 | 2 || 9 | Obama | 22 | 3 || 10 | Bush | 25 | 1 || 11 | Richard | 22 | 12 || 12 | Andy | 22 | 13 |+----+---------+------+----------+
lname:
+----+-----------+| id | name |+----+-----------+| 1 | 北京市 || 2 | 上海市 || 3 | 广州市 || 4 | 深圳市 || 5 | 杭州市 |+----+-----------+
现进行以下操作:
SELECT * FROM users INNER JOIN lname ON users.location=lname.id;
结果为:
+----+---------+------+----------+----+-----------+| id | name | age | location | id | name |+----+---------+------+----------+----+-----------+| 1 | John | 20 | 3 | 3 | 广州市 || 2 | Kity | 24 | 3 | 3 | 广州市 || 3 | Tommy | 26 | 4 | 4 | 深圳市 || 4 | Jackson | 31 | 3 | 3 | 广州市 || 5 | Pat | 19 | 4 | 4 | 深圳市 || 6 | Darling | 33 | 2 | 2 | 上海市 || 7 | Tamzin | 29 | 2 | 2 | 上海市 || 8 | Hoking | 21 | 2 | 2 | 上海市 || 9 | Obama | 22 | 3 | 3 | 广州市 || 10 | Bush | 25 | 1 | 1 | 北京市 |+----+---------+------+----------+----+-----------+
不难看出,返回结果为users表中的第11、12条记录,以及lname表中的第5条记录以外的所有结果,原因就是这3条记录并不存在于两表的交集之中。(若觉得难以理解,往下结合左外连接与右外连接相对照,这样比较容易理解)
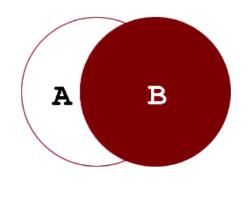
左外连接为返回左表中的全部以及右表中满足连接条件的记录,右表不存在的记录所对应的字段显示为NULL。
右外连接则为返回右表中的全部以及左表中满足连接条件的记录,左表不存在的记录所对应的字段显示为NULL。
例:仍为上述两表,现将上述查询操作中的内连接改为左外连接:
SELECT * FROM users LEFT JOIN lname ON users.location=lname.id;
输出结果为:
+----+---------+------+----------+------+-----------+| id | name | age | location | id | name |+----+---------+------+----------+------+-----------+| 10 | Bush | 25 | 1 | 1 | 北京市 || 6 | Darling | 33 | 2 | 2 | 上海市 || 7 | Tamzin | 29 | 2 | 2 | 上海市 || 8 | Hoking | 21 | 2 | 2 | 上海市 || 1 | John | 20 | 3 | 3 | 广州市 || 2 | Kity | 24 | 3 | 3 | 广州市 || 4 | Jackson | 31 | 3 | 3 | 广州市 || 9 | Obama | 22 | 3 | 3 | 广州市 || 3 | Tommy | 26 | 4 | 4 | 深圳市 || 5 | Pat | 19 | 4 | 4 | 深圳市 || 11 | Richard | 22 | 12 | NULL | NULL || 12 | Andy | 22 | 13 | NULL | NULL |+----+---------+------+----------+------+-----------+
2. 多表创建
CREATE TABLE [IF NOT EXISTS] tbl_name [(create_definition, ...)] select_statement;
在创建表的同时把查询结果写入该表中。
3. 多表删除
DELETE tbl_name[.*] [,tbl_name[.*]] ... FROM table_references [WHERE where_condition];
例:把上述例子中的表users中location字段在表lname中不存在的记录删掉(即删掉第11、12条记录):
DELETE users.* FROM users INNER JOIN lname ON users.location != ALL(SELECT lname.id FROM lname);
4. 多表更新
UPDATE tables_references SET col_name1={expr1 | DEFAULT} [, col_name2={expr2 | DEFAULT}]... [WHERE where_condition];
例:存在以下两个数据表:
users:
+----+---------+------+-----------+| id | name | age | location |+----+---------+------+-----------+| 1 | John | 20 | 广州市 || 2 | Kity | 24 | 广州市 || 3 | Tommy | 26 | 深圳市 || 4 | Jackson | 31 | 广州市 || 5 | Pat | 19 | 深圳市 || 6 | Darling | 33 | 北京市 || 7 | Tamzin | 29 | 北京市 || 8 | Hoking | 21 | 北京市 || 9 | Obama | 22 | 广州市 || 10 | Bush | 25 | 上海市 |+----+---------+------+-----------+
lname:
+----+-----------+| id | name |+----+-----------+| 1 | 上海市 || 2 | 北京市 || 3 | 广州市 || 4 | 深圳市 |+----+-----------+
现将users表中的location用lname表中相应的id进行替代,操作为:
UPDATE users INNER JOIN lname ON users.location=lname.name SET users.location=lname.id;
七、运算符与函数
PS:MySQL提供的函数有很多,这里仅列举一些比较常用的函数,若需要用到其它函数,可查阅MySQL官方文档。
1. 字符函数
1.1 CONCAT(str1, str2, ...)
作用:连接多个字符串。例:SELECT CONCAT('John','Smith');输出结果为:
+------------------------+| CONCAT('John','Smith') |+------------------------+| JohnSmith |+------------------------+
1.2 CONCAT_WS(connector, str1, str2, ...)
作用与CONCAT相同,不同之处在于CONCAT_WS的第一个参数为指定连接字符串所使用的连接符。例:存在表username:
+-----------+----------+| firstname | lastname |+-----------+----------+| John | Smith || Kity | Chan |+-----------+----------+
输入命令SELECT CONCAT_WS('-', firstname, lastname) AS fullname FROM username;输出结果为:
+------------+| fullname |+------------+| John-Smith || Kity-Chan |+------------+
1.3 FORMAT(number, dec_place)
将数字格式化,返回结果为字符型。所谓格式化即将整数每3位用逗号分隔,并按照指定保留小数位数进行取舍。函数的第一个参数为进行格式化的数字,第二个参数为保留的小数位数。
例:SELECT FORMAT(156416486435.13561651,5);的输出结果为:
+----------------------------------+| FORMAT(156416486435.13561651, 5) |+----------------------------------+| 156,416,486,435.13562 |+----------------------------------+
1.4 LOWER(str)、UPPER(str)
LOWER的作用是将字符中的字母全部转换为小写,UPPER则相反。例:SELECT LOWER('TEST大写');输出结果为:
+---------------------+| LOWER('TEST大写') |+---------------------+| test大写 |+---------------------+
1.5 LEFT(str, len)、RIGHT(str, len)
LEFT的作用是获取字符串从左边算起指定位数的字符,RIGHT则相反。例:SELECT LEFT('MyFunction', 5);输出结果为:
+-----------------------+| LEFT('MyFunction', 5) |+-----------------------+| MyFun |+-----------------------+
1.6 LENGTH(str)
获取字符串长度。
1.7 LTRIM(str)、RTRIM(str)、TRIM()
LTRIM的作用是删除字符串的前导空格(即字符串前面的空格),RTRIM是删除字符串的后续空格(即字符串后面的空格);
TRIM的用法有两种,一是参数仅指定一个字符串TRIM(str),则删除该字符串的前导和后续空格;还有一种用法则是可指定删除字符串的前导或后续的指定字符TRIM({LEADING | TRAILING | BOTH} del_char FROM str),LEADING为前导,TRAILING为后续,BOTH则为两者均删除。
例:SELECT LENGTH(' TEST ');的输出结果为:
+---------------------+| LENGTH(' TEST ') |+---------------------+| 9 |+---------------------+
加上TRIM函数后:SELECT LENGTH(TRIM(' TEST '));
+---------------------------+| LENGTH(TRIM(' TEST ')) |+---------------------------+| 4 |+---------------------------+
另外,若输入命令SELECT TRIM(LEADING ',' FROM ',test,');,输出结果为:
+---------------------------------+| TRIM(LEADING ',' FROM ',test,') |+---------------------------------+| test, |+---------------------------------+
1.8 REPLACE(str, ori_str, sub_str)
将字符串中的某段字符替换成另外一段字符。例:输入命令SELECT REPLACE('asdfasdf', 'as', 'df');,结果为:
+---------------------------------+| REPLACE('asdfasdf', 'as', 'df') |+---------------------------------+| dfdfdfdf |+---------------------------------+
1.9 SUBSTRING(str, i[, j])
作用是截取字符串str从第i个字符开始算起长度为j的字符串,若不指定j,则从第i位截取到末尾。i可以为负值,此时则从字符串的末尾往前算,例如-3则为倒数第3个字符算起。
1.10 [NOT] LIKE
作用是在一个字符型字段中检索包含指定子字符串的字符串,需要配合通配符进行使用。MySQL中LIKE语句的通配符有:百分号(%)、下划线(_)和ESCAPE。
%表示任意字符串,例如'%ab%'表示含有'ab'的任意字符串,可以是aabc、lab、abo等等;下划线表示任意单个字符,例如'ae_a'可以表示aeba、aeoa等等;若需要查询%或下划线,则通过ESCAPE加转义字符。
例:查询表users中name字段为'李'开头的记录:
SELECT * FROM users WHERE name LIKE '李%';
查询表users中name字段为'xiao%'开头的记录:
SELECT * FROM users WHERE name LIKE '李/%%' ESCAPE '/';
紧随转义字符后面的一个%或一个下划线不作为通配符,其它的依旧为通配符。
2. 数值运算符和函数
2.1 CEIL(num)、FLOOR(num)
分别为向上取整和向下取整。
2.2 ROUND(num[, m])
四舍五入。可仅指定进行四舍五入的数字,也可以通过第二个参数同时指定取舍的小数位数。
2.3 POWER(num, m)
幂运算,计算num的m次方。
2.4 TRUNCATE(num, m)
数字截取。m为正值时,将num保留m位小数,m为负值时,则从整数位个位算起m位为0,同时保留整数。不作四舍五入,而直接截取。例如TRUNCATE(23.63, 0) = 23、TRUNCATE(459.23, -1) = 450。
2.5 DIV
整数除法,即将普通除法得到的结果保留整数位,例如5 DIV 4 = 1。
2.6 MOD
取余运算,例如5 MOD 4 = 1。
3. 比较运算符和函数
3.1 [NOT] BETWEEN...AND...
判断是否在指定范围内。例如SELECT 10 BETWEEN 0 AND 10,结果为1,即true。
3.2 [NOT] IN()
判断是否在给定的若干个值的范围内。BETWEEN...AND...判断的是一个连续的区间,而IN则是数轴上的几个点。例如SELECT 6 IN(1, 2, 3, 4);结果为0,即false。
3.3 IS [NOT] NULL
判断是否为空。例如SELECT '' IS NULL,结果为0。
4. 日期时间函数
4.1 NOW()、CURDATE()、CURTIME()
分别是当前日期和时间、当前日期、当前时间。例如输入命令SELECT NOW();,结果为:
+---------------------+| NOW() |+---------------------+| 2017-03-06 10:21:17 |+---------------------+
4.2 DATE_ADD(ori_date, INTERVAL add_date {YEAR | MONTH | WEEK | DAY |...})
日期变化,add_date可以为负值。例如SELECT DATE_ADD('2017-03-06', INTERVAL -2 MONTH);,结果为:
+-------------------------------------------+| DATE_ADD('2017-03-06', INTERVAL -2 MONTH) |+-------------------------------------------+| 2017-01-06 |+-------------------------------------------+
4.3 DATEDIFF(date1, date2)
计算两个日期的差值。例如SELECT DATEDIFF('2016-01-01', NOW());,结果为(今天日期为2017-03-06):
+-------------------------------+| DATEDIFF('2016-01-01', NOW()) |+-------------------------------+| -430 |+-------------------------------+
4.4 DATE_FORMAT(date, format)
将日期date按照指定格式输出。常用格式有年份的%y、%Y,月份的%m、%M,日期的%D、%d,要注意,区分大小写。
例:SELECT DATE_FORMAT(NOW(), '%d/%m/%y');,结果为:
+--------------------------------+| DATE_FORMAT(NOW(), '%d/%m/%y') |+--------------------------------+| 06/03/17 |+--------------------------------+
SELECT DATE_FORMAT(NOW(), '%D/%M/%Y');,结果为:
+--------------------------------+| DATE_FORMAT(NOW(), '%D/%M/%Y') |+--------------------------------+| 6th/March/2017 |+--------------------------------+
5. 信息函数
| 名称 | 作用 |
|---|---|
| CONNECTION_ID() | 返回当前线程的id |
| DATABASE() | 返回当前正在使用的数据库名称 |
| LAST_INSERT_ID() | 返回最后插入的记录的ID |
| USER() | 返回当前用户 |
| VERSION() | 返回当前数据库的版本信息 |
LAST_INSERT_IN()使用注意:使用的对象数据表必须含有一个自动编号的字段。若最新一次插入操作同时插入多条记录,则返回多条记录中的第一个id而非最后一个id。例如最后一次操作中插入了id为8和9的两条记录,则使用LAST_INSERT_ID返回的id为8。
6. 聚合函数
| 名称 | 作用 |
|---|---|
| AVG() | 计算平均值 |
| COUNT() | 计数 |
| MAX() | 比较得到最大值 |
| MIN() | 比较得到最小值 |
| SUM() | 求和 |
聚合函数使用注意:在MySQL中不允许使用聚合函数直接进行数值运算,其参数要求为数据表中的某字段名称。例如SELECT AVG(1, 2, 3);这一命令则会报错,正确用法应为SELECT AVG(age) FROM users;。
7. 加密函数
7.1 MD5(str)
对字符串进行散列,一般用于一些普通的不需要解密的数据加密。例:SELECT MD5('MyPassword');,结果为:
+----------------------------------+| MD5('MyPassword') |+----------------------------------+| 48503dfd58720bd5ff35c102065a52d7 |+----------------------------------+
7.2 PASSWORD(str)
用法与MD5()基本一致,一般用于给用户密码进行加密。
8. 自定义函数
8.1 变量
(1)用户变量:以"@"开始,定义方法为@var_name,例如定义一个变量temp并让其等于10:SET @temp = 10;。需要注意,使用变量时需要连着"@"。用户变量跟mysql客户端是绑定的,设置的变量,只对当前用户使用的客户端生效。
(2)全局变量:定义时,以如下两种形式出现,SET GLOBAL 变量名或者SET @@GLOBAL.var_name。对所有客户端生效,只有具有super权限才可以设置全局变量。
(3)会话变量:只对连接的客户端有效。
(4)局部变量:用DECLARE进行定义,作用范围在begin到end语句块之间。
8.2 简单结构(函数体只有一个执行语句)
CREATE FUNCTION function_name([par_definition1] [, par2_definition2] ...)RETURNS data_typeRETURN function_oper;
函数名后面指定参数列表,可以为空;RETURES后面指定返回值类型;RETURN后面跟具体的函数内容,注意返回类型需与RETURNS后面指定的类型一致。
例:自定义一个函数,求两个整数的平均值:
CREATE FUNCTION myAvg(a SMALLINT, b SMALLINT)RETURNS SMALLINTRETURN (a+b)/2;
输入命令SELECT myAvg(8,4);,结果为:
+------------+| myAvg(8,4) |+------------+| 6 |+------------+
8.3 复合结构(函数体有多个执行语句)
DELIMITER new_terminatorCREATE FUNCTION function_name([par_definition1] [, par2_definition2] ...)RETURNS data_typeBEGINfunction_oper1;RETURN function_oper2;END new_terminator
与简单结构不同的地方有二,第一是当出现多个执行语句时,前面的执行语句末尾的';'会被认为是终止符,导致出错,因此首先需要通过DELIMITER关键字指定新的终止符;第二则是简单结构中执行语句只有一句,因此该语句必须为能够直接跟在RETURN后面的、返回值符合要求的语句,而复合结构中存在多个语句,因此需要以BEGIN开始,以RETURN返回值,以END结束。
例:定义一个函数,可向users表(含有id、name两个字段)插入一条记录,并返回该记录的ID:
DELIMITER $$CREATE FUNCTION addUser(name VARCHAR(20))RETURNS VARCHAR(20)BEGININSERT users(name) VALUES(name);RETURN LAST_INSERT_ID();END$$DELIMITER ;
将终止符重新指定为分号,并加入第一条记录:
mysql> DELIMITER ;mysql> SELECT addUser('John');+-----------------+| addUser('John') |+-----------------+| 1 |+-----------------+
8.4 删除自定义函数
DROP FUNCTION [IF EXISTS] function_name;
八、存储过程
CREATE [DEFINER = {user | CURRENT_USER}] PROCEDURE sp_name ([{IN | OUT | INOUT} proc_parameter[, ...]]) [characteristic ...] routine_body;
创建存储过程的语法结构与自定义函数非常相似,仅仅是多了[DEFINER = {user | CURRENT_USER}]这一选项,DEFINER用于指定存储过程的创建用户,可不写。IN表示该参数的值必须在调用存储过程时指定,用IN修饰的参数相当于函数中的形式参数;OUT表示该参数的值可以被存储过程改变,并且可以返回,用OUT修饰的参数相当于用于存储返回值的变量;INOUT表示该参数的调用时指定,并且可以被改变和返回。
例1. 创建一个不带参数的存储过程,用于显示数据库版本信息:
CREATE PROCEDURE showver() SELECT VERSION();
存储过程的调用方法是CALL sp_name([proc_parameter[, ...]]);,若无参数,可省略小括号。
例2. 创建一个带有IN类型参数的存储过程,用于删除表users中的指定id的记录:
DELIMITER $$CREATE PROCEDURE delUser(IN id SMALLINT UNSIGNED)BEGINDELETE FROM users WHERE users.id = id;END $$DELIMITER ;
例3. 创建一个带有IN类型参数和OUT类型参数的存储过程,用于删除表users中的指定id的记录并返回剩余记录数量:
DELIMITER $$CREATE PROCEDURE removeUser(IN id SMALLINT UNSIGNED, OUT num SMALLINT UNSIGNED)BEGINDELETE FROM users WHERE users.id = id;SELECT COUNT(id) FROM users INTO num;END $$DELIMITER ;
调用时使用命令CALL removeUser(8,@num);。
删除存储过程的操作是DROP PROCEDURE [IF EXISTS] sp_name;
MySQL入门笔记(二)的更多相关文章
- MySQL入门笔记
MySQL入门笔记 版本选择: 5.x.20 以上版本比较稳定 一.MySQL的三种安装方式: 安装MySQL的方式常见的有三种: · rpm包形式 · 通用二进制 ...
- MySQL入门笔记(一)
一.数据类型 1. 整型 2. 浮点型 3. 字符型 4. 日期时间型 二.数据库操作 1. 创建库 CREATE {DATABASE | SCHEMA} [IF NOT EXISTS] db_nam ...
- MySQL入门笔记 - 视图
参考书籍<MySQL入门很简单> 1.视图定义 视图是从一个或者多个表中导出来的虚拟的表,透过这个窗口可以看到系统专门提供的数据,使用户可以只关心对自己有用的数据,方便用户对数据操作,同时 ...
- MySQL入门笔记 - 数据类型
参考书籍<MySQL入门很简单> 数据类型是数据的一种属性,可以决定数据的存储方式.有效范围和相应的限制. 1.整数类型 1.1 MySQL的整数类型 MySQL中int类型和inte ...
- MySQL入门笔记 - 数据库概述
参考书籍<MySQL入门很简单> 1.数据库 数据库(DataBase)是一个存储数据的仓库,将数据按照特定的规律存储在磁盘上. 2.数据存储方式 数据存储方式分为3个阶段:人工管理阶段. ...
- MySQL入门笔记一
MySQL应用笔记 一MySQL关系型数据库.开源,中小型公司常用类型的数据库Oracle 大型公司常用数据库 MySQL基本的命令一. 创建.删除.查看数据库(database)创建库creat ...
- mySql入门-(二)
最近刚刚开始学习Mysql,然而学习MySql必经的一个过程就是SQL语句,只有按照文档从头开始学习SQL语句.学习的过程是痛苦的,但是学完的成果是甘甜的. SQL 语法 所有的 SQL 语句都以下列 ...
- MySQL入门(二)
一 MySQL概述 MySQL是一个很受欢迎的开源数据库,当我从Oracle转来做MySQL的时候,感觉最深刻的一点就是,这家伙居然是Server和Storage分开的!而且更不能忍的是,它竟然是插件 ...
- Mysql查询(笔记二)
1.两结构相同的表数据间移植 Inset into 表一 Select 字段1,字段2,....字段n from表二 建立数据库时设置数据库编码 create database 数据库名 charse ...
随机推荐
- php读取文件内容的三种方法
<?php //**************第一种读取方式***************************** 代码如下: header("content-type:text/h ...
- 携程Apollo(阿波罗)配置中心在.NET Core项目快速集成
.NET Core的支持文档大体上可以参考文档.Net客户端使用指南:https://github.com/ctripcorp/apollo/wiki/.Net%E5%AE%A2%E6%88%B7%E ...
- 织梦默认编辑器 按下回车生成br标签改为生成p标签
找到文件 \include\ckeditor\config.js 把 config.enterMode = CKEDITOR.ENTER_BR; config.shiftEnterMode = CKE ...
- 老男孩Python全栈开发(92天全)视频教程 自学笔记08
day8课程内容: 文件操作 f=open('小重山','r',encoding='utf8') #以读的方式打开文件 data=f.read() print(data) f.close() # ...
- 2017CCPC 网络选拔赛1003 Ramsey定理
Ramsey定理 任意6个人中,一定有三个人互为朋友,或者互相不是朋友. 证明 这里我就不证明了.下面链接有证明 鸽巢原理 Ramsey定理 AC代码 #include <stdio.h> ...
- float 与 display:inline-block
float: 1.会导致高度塌陷 <style type="text/css"> li{ float:left; height:200px; width:200px; ...
- NewLife.XCode 上手指南2018版(一)代码生成
目录 NewLife.XCode 上手指南2018版(一)代码生成 NewLife.XCode 上手指南2018版(二)增 NewLife.XCode 上手指南2018版(三)查 NewLife.XC ...
- hadoop配置遇到问题的解决
1. ssh localhost: 不能登陆:将错误提示中的文件全部删除.原因:登陆过远程主机 2. 问题: 伪分布式datanode启动不了:在datanode的log日志文件出现以下错误提示: ...
- 常用u-boot命令详解(全)
U-boot发展到现在,他的命令行模式已经非常接近Linux下的shell了,命令行模式模式下支持"Tab"键的命令补全和命令的历史记录功能.而且如果你输入的命令的前几个字符和别的 ...
- Android安全开发之WebView中的大坑
0X01 About WebView 在Android开发中,经常会使用WebView来实现WEB页面的展示,在Activiry中启动自己的浏览器,或者简单的展示一些在线内容等.WebView功能强大 ...