《构建之法》教学笔记——Python中的效能分析与几个问题
《构建之法:现代软件工程》中第2章对效能分析进行了介绍,基于的工具是VSTS。由于我教授的学生中只有部分同学选修了C#,若采用书中例子讲解,学生可能理解起来比较困难。不过所有这些学生都学习过Python,因此我就基于书中对效能分析的介绍,结合Python效能分析工具的文档以及互联网上的博客,准备了一份关于效能分析的讲座,内容如下。
什么是效能分析?
这部分的讲解和书中类似。不过有两个问题:
- 为什么是效能不是效率,两者之间究竟有什么区别?这是学生提出的问题。个人觉得二者之间的差别不大。
- 效能分析是否包括内存优化?也就是程序的运行需要更少的内存。如果不包括的话,是基于什么样的考虑呢?
效能分析的目标
VSTS提供了方便的效能分析工具,让我们能很快地找到程序的效能瓶颈,从而能有的放矢,改进程序。——《构建之法:现代软件工程》
非常赞同这句话,并且认为效能分析的目标其实就是做到 有的放矢 。时间是很宝贵的资源,如果不经过分析立马开始进行程序效能的优化提升,可能花了1天时间所获得的优化效果还抵不上经过效能分析后改动两三行代码代码所获得的优化效果。
效能分析的方法
1. 抽样(Sampling)
根据《构建之法》的描述,抽样是指效能分析工具会时不时看一看这个程序运行在哪个函数内,并记录下来。程序结束后,效能分析工具就能得出一个关于程序运行时间的大致印象。
2. 代码注入(Instrumentation)
根据《构建之法》的描述,代码注入是指将检测代码加入到每一个函数中,检测代码会记录程序运行的一举一动,程序的各个效能数据都可以被精确的测量。
3. 抽样与代码注入的优缺点比较
根据《构建之法》的描述,我总结出如下表格。
| 方法 | 是否需要改动程序 | 运行速度 | 是否可以找到程序瓶颈 | 能否得出精确数据 | 能否准确表示调用关系树 | 是否影响程序运行 |
|---|---|---|---|---|---|---|
| 抽样 | 否 | 较快 | 可以 | 否 | 否 | 否 |
| 代码注入 | 是 | 相对抽样方法较慢 | 可以 | 能 | 能 | 是 |
4. Python中的效能分析方法
一般的做法是,先用抽样方法找到效能瓶颈所在,然后对特定的模块用代码注入的方法进行详细分析。——《构建之法:现代软件工程》
在Python中的效能分析方法和《构建之法》中描述的有些不一样。 在Python中进行效能分析用到的工具是cProfile。在Python自带的关于cProfile的帮助文档中,有一段是介绍确定性效能分析(Deterministic Profiling)的,根据文中所述,个人理解,这应该是指代码注入方法。其中的一段描述非常重要,且给我带来了一个很大的疑惑。
In Python, since there is an interpreter active during execution, the presence of instrumented code is not required to do deterministic profiling. Python automatically provides a hook (optional callback) for each event. In addition, the interpreted nature of Python tends to add so much overhead to execution, that deterministic profiling tends to only add small processing overhead in typical applications. The result is that deterministic profiling is not that expensive, yet provides extensive run time statistics about the execution of a Python program. ——《Python 2.7.5 documentation》
全文大致意思如下(非专业翻译):
在Python中,由于程序执行期间解释器是处于激活状态的,因此注入程序中的代码是无需进行确定性分析的。Python中的每个事件都自带钩子(可选回调函数)。另外,Python解释性编程语言的本质趋向于给程序添加许多执行开销以致于确定性分析趋向于在典型应用中仅仅添加少量的处理开销。结果就是,确定性分析给Python程序执行提供广泛的运行时统计,却没有那么高昂的代价。
也就是说,在Python中代码注入方法并不会产生太大的开销,原因是因为Python是一种解释型编程语言。解释型的编程语言有一些特性使得代码注入方式的效能分析并不会增加Python程序的运行时间。我的困惑是: 究竟是解释型编程语言的什么特性导致代码注入方式的效能分析不会增加Python程序的运行时间?
鉴于以上情况,在Python中进行效能分析,直接使用代码注入方法即可。使用的工具就是cProfile。
cProfile的使用方法
关于cProfile的基本使用方法,已经有不少博客解释说明,可以参考这个:应用python的性能测量工具cProfile。还有官方文档:26.4. The Python Profilers。
Python中使用cProfile进行效能分析的示例
模仿《构建之法》中统计词频的程序,我用Python写了一个可以进行词频统计的程序(未经过全面测试)。程序代码如下:
from string import punctuation
def process_file(dst):
try:
f = open(dst)
except IOError, s:
print s
return None
try:
bvffer = f.read()
except:
print "Read File Error!"
return None
f.close()
return bvffer
def process_buffer(bvffer):
if bvffer:
word_freq = {}
for item in bvffer.strip().split():
word = item.strip(punctuation+' ')
if word in word_freq.keys():
word_freq[word] += 1
else:
word_freq[word] = 1
return word_freq
def output_result(word_freq):
if word_freq:
sorted_word_freq = sorted(word_freq.items(), key=lambda v: v[1], reverse=True)
for item in sorted_word_freq[:10]:
print item
if __name__ == "__main__":
import argparse
parser = argparse.ArgumentParser()
parser.add_argument('dst')
args = parser.parse_args()
dst = args.dst
bvffer = process_file(dst)
word_freq = process_buffer(bvffer)
output_result(word_freq)
然后进入命令行并进入程序所在目录后输入以下命令:
python -m cProfile word_freq.py semeval-sts/2016/postediting.test.txt
其中 semeval-sts/2016/postediting.test.txt 是一个句子语义相似度计算语料库, 大小775K 。 太小的话看不出优化效果 。之后会得到如下分析结果:
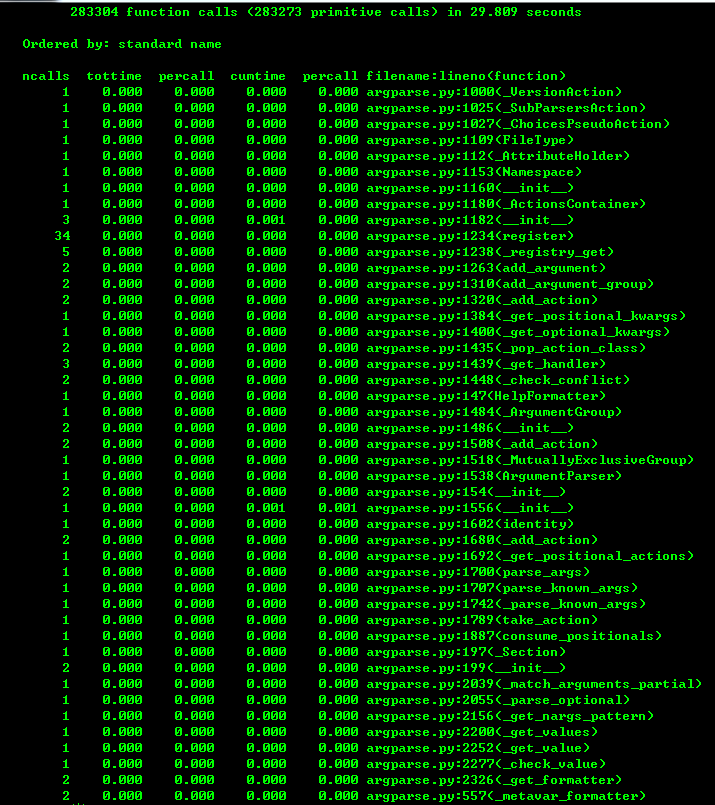
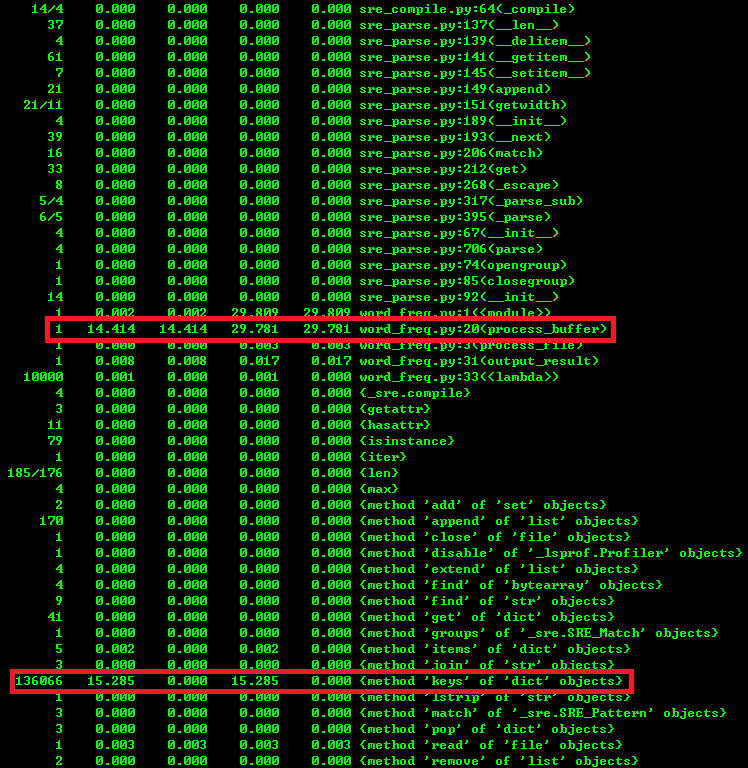
如图1所示, 总共有283304次函数调用,程序总共耗时29.809秒 。如图3所示, 字典的keys方法被调用的次数为136066次,花费的总时间为15.285秒 。仔细观察代码发现函数process_buffer函数中有一行代码:
if word in word_freq.keys():
该代码在for循环中,有多少单词,这个循环就会执行多少遍,每次进行条件判断的时候都要执行一次字典的keys方法,所以耗时很多。于是把keys去除,该行代码变为:
if word in word_freq:
再次进行效能分析,进入命令行,输入如上一样的命令:
python -m cProfile word_freq.py semeval-sts/2016/postediting.test.txt
首先,感觉程序瞬间就结束了,不像上面的程序运行了一段时间才显示结果。其次程序的函数调用次数和总运行时间减少了。如下图:
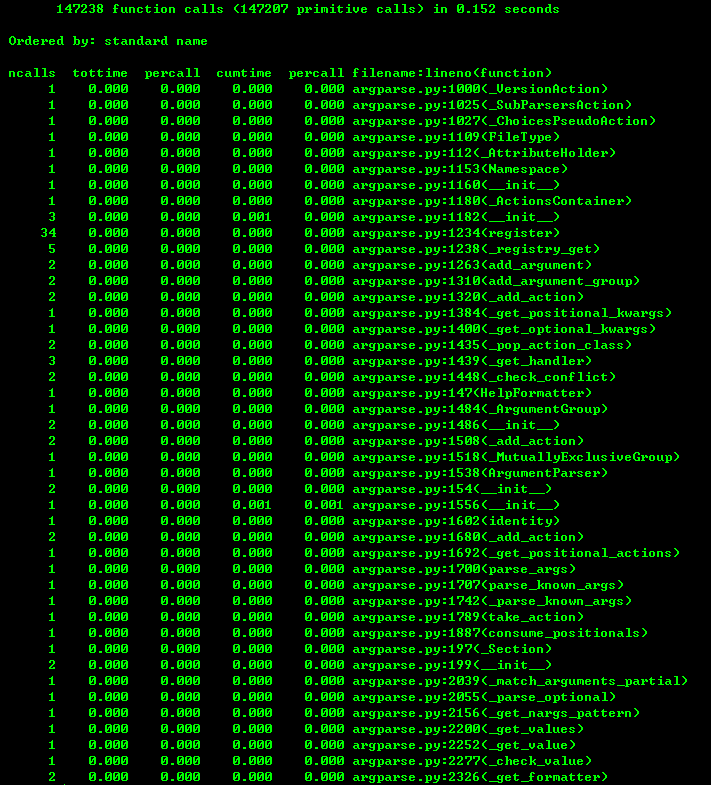
程序总共有147238次函数调用,耗时0.152秒 。
经过以上过程我们实现了对程序的优化,只需简单的去除一些代码就可以,而且效果非常显著。这就是效能分析的意义!
《构建之法》教学笔记——Python中的效能分析与几个问题的更多相关文章
- 学习笔记--python中使用多进程、多线程加速文本预处理
一.任务描述 最近尝试自行构建skip-gram模型训练word2vec词向量表.其中有一步需要统计各词汇的出现频率,截取出现频率最高的10000个词汇进行保留,形成常用词词典.对于这个问题,我建立了 ...
- 【构建之法教学项目】一个简单的基于C#的电子商务系统演练场景的代码示例
电子商务平台,是一个历史悠久而又充满挑战的行业,他和社交一起成为中国互联网市场的两极.电子商务系统是一个非常复杂的系统,他实现了人与物.人与人的链接,同时也需要大量的技术来支撑,实现系统的高可用.这些 ...
- 学习打卡day12&构建之法阅读笔记第一篇
今天浅读了<构建之法>的前四章,稍微有一些个人的见解与感受 第一点即是开篇提及到的算法与数据结构这门学科开设的必要,大二上学期学习了这门课程,就我个人目前接触到的层面来看,几乎可以说用不太 ...
- 《python源代码剖析》笔记 python中的List对象
本文为senlie原创,转载请保留此地址:http://blog.csdn.net/zhengsenlie 1.PyListObject对象 --> 变长可变对象,可看作vector<Py ...
- week1读构建之法-读书笔记
最开始听见杨老师说邹欣老师这个名字总觉得很熟悉,后来看见博客上老师的头像恍然大悟,原来机缘巧合已经在微博上关注邹老师许久,一直觉得邹老师是个很有意思的人,兴趣一定十分广泛,看了老师的书确实能感觉到邹老 ...
- [笔记]Python中模块互相调用的例子
python中模块互相调用容易出错,经常是在本地路径下工作正常,切换到其他路径来调用,就各种模块找不到了. 解决方法是通过__file__定位当前文件的真实路径,再通过sys.path.append( ...
- python中xrange用法分析
本文实例讲述了python中xrange用法.分享给大家供大家参考.具体如下: 先来看如下示例: >>> x=xrange(0,8) >>> print x xra ...
- [笔记] Python 中JSON数据的读写
前言 JSON(JavaScript Object Notation,JavaScript对象表示法)是一种轻量级的数据交换语言 JSON是独立于语言的文本格式, JSON 数据格式与语言无关 JSO ...
- 《python源代码剖析》笔记 python中的Dict对象
本文为senlie原创,转载请保留此地址:http://blog.csdn.net/zhengsenlie 1.PyDictObject对象 --> C++ STL中的map是基于RB-tre ...
随机推荐
- Array.from()
es6 Array.from() 方法将两类对象转为真正的数组 用法:用于将两类对象转为真正的数组:类似数组的对象和可遍历(iterable)的对象(包含ES6新增的数据结构Set和Map); 说明: ...
- 新建.Net Core应用程序后引用项一直黄色感叹号怎么办?
我们在vs中创建.Net Core应用程序后,引用项可能出现黄色感叹号,正常情况下,这种黄色感叹号时能在项目创建成功之后迅速消失的,可也有些时候一直不消失,怎么办? 我们可以选中异常的项目,然后右键菜 ...
- Asp.Net WebApi 调试利器“单元测试”
当我们编辑好一个WebApi应用程序后,需要对该Api接口进行调试,传统的调试办法是在方法内设置断点,然后用PostMan等http工具模拟访问进行查看WebAPI的运行情况,但这种除了效率较低还进行 ...
- httpclient案例二(调用百度地图的接口)
一,class T package com.http.test; import org.junit.Test; import com.http.BaiduMapProxyService; import ...
- 一个题目涉及到的50个Sql语句
原博客地址 http://blog.csdn.net/maco_wang/article/details/6281484 Student(S#,Sname,Sage,Ssex) 学生表 Course( ...
- 改数据库编码latin1为utf8
因为建数据库的时候没有选utf8,所以默认是latin1 在网上查了好多资料 ,试了很多种方法,都不奏效,有用的一个竟然要一列一列的改, 最后在评论里发现了这个,抱着试一试的心态竟然成功改过来了,在这 ...
- 关系型数据库工作原理-数据库查询器(翻译自Coding-Geek文章)
本文翻译自Coding-Geek文章:< How does a relational database work>.原文链接:http://coding-geek.com/how-data ...
- CDN和CDN加速原理
随着互联网的发展,用户在使用网络时对网站的浏览速度和效果愈加重视,但由于网民数量激增,网络访问路径过长,从 而使用户的访问质量受到严重影响.特别是当用户与网站之间的链路被突发的大流量数据拥塞时,对于异 ...
- c语言基础知识
进制: l 碾(nian)除法:十进制转为几进制则除几,从下往上看余数 (十进制转二进制,十进制转八进制,十进制转十六进制) l 几进制转化为十进制:直接乘以几的次方数: l binary: ...
- 深入理解Java虚拟机(第2版) 笔记目录
本篇为读深入理解Java虚拟机(第2版)一书的笔记目录. Java 运行期数据区 Java 垃圾回收算法 Java 内存分配策略 Java 类文件结构 Java 加载.链接.初始化 Java 类加载器