数据库原理 - 序列5 - 事务是如何实现的? - Undo Log解析
本文节选自作者书籍《软件架构设计:大型网站技术架构与业务架构融合之道》。
作者微信公众号:架构之道与术。公众号底部菜单有书友群可以加入,与作者和其他读者进行深入讨论。也可以在京东、天猫上购买纸质书籍。
6.6 事务实现原理之2:Undo Log
6.6.1 Undo Log是否一定需要
说到Undo Log,很多人想到的只是“事务回滚”。“事务回滚”有四种场景:
场景1:人为回滚。事务执行到一半时发生异常,客户端调用回滚,通知数据库回滚,数据库回滚成功。
场景 2:宕机回滚。事务执行到一半时数据库宕机,重启,需要回滚。
场景 3:人为回滚 + 宕机回滚。客户端调用回滚,数据库开始回滚数据,回滚到一半时数据库宕机,重启,继续回滚。
场景 4:宕机回滚 + 宕机回滚。宕机重启,在回滚的过程中再次宕机。
对于这四种场景的解决方法,在上文的ARIES算法已经给出了答案,其中要用到Redo和Undo Log。这里扩展一下,除了ARIES算法,是否还有其他的方法可以做事务回滚?或者说,Undo Log是否一定需要?
回滚,就是取消已经执行的操作。无论从物理上取消,还是从逻辑上取消,只要能达到目的即可。假设Page数据都在内存里面,每个事务执行,都只在内存中修改数据,必须等到事务Commit之后写完Redo Log,再把Page数据刷盘。在这种策略下,不需要Undo Log也能实现数据回滚!因为在这种数据刷盘策略下,正好利用了“内存断电消失”的特性,磁盘上存储的全部是已经提交的数据,宕机重启,内存中还未完成的事务自然被一笔勾销了!在这种策略之下,未提交的事务不会进入Redo Log;未提交的事务,也不会刷盘,全都在内存里面。
把这个展开,就是Page数据刷盘的四种策略,如表6-10所示。下面对这四种策略进行详细分析:
表6-10 Page数据刷盘的四种策略

No Steal和Steal:指未提交的事务是否可以写入磁盘中?No Steal是未提交的事务不能写入磁盘,只能在内存中操作,等到事务提交完,再把数据一次性写入;Steal是指未提交的事务也能写入,如果事务需要回滚,再更改磁盘上的数据。
No Force和Force: 是指已经提交的事务是否必须写入磁盘?No Force是指已经提交的事务可以保留在内存里,暂时不用写入磁盘;Force是指已经提交的事务必须强制写入磁盘。
策略1:Force和No Steal。已经提交的事务必须强制写入磁盘,未提交的事务,只能保留在内存里,等事务提交后再写入磁盘,这种策略不需要Redo Log和Undo Log,仅靠数据本身就能实现原子性和持久性。但很显然不可行,未提交的事务不能写入磁盘,这还可以接受;已提交的事务必须强制写入磁盘,这需要多次I/O,性能会受影响,所以才有了RedoLog。
策略2:No Force和No Steal。已提交的事务可以不立即写入磁盘,未提交的事务只能保留在内存里。在这个策略下,只需要Redo Log即可,因为有“内存断电消失”这个天然特性。
策略3:Force/Steal。已提交的事务立即写入磁盘,未提交的事务也立即写入磁盘。这种只需要UndoLog回滚宕机时未提交的事务,不需要Redo Log。但和策略1一样,显然不可行,多次I/O的性能会受影响。
策略4:No Force/Steal。第4种策略是我们最想要的,也是InnoDB实现的策略。就是已经提交的事务可以不立即写入磁盘;未提交的事务可以立即写入磁盘,也可以延迟写入磁盘!再通俗一点,无论事务是否提交,既可以立即写入磁盘,也可以不写,写入磁盘时机任意,想什么时候写就什么时候写。
策略1和策略3因为性能问题不能接受,所以必须要有Redo Log。而策略4和策略2都可以接受,但策略4比策略2好的地方在于提高了I/O效率。因为事务没有提交,就开始写入磁盘,等到提交事务的时候,要写入磁盘的数据量会小,不然要把所有数据都累积到事务提交时再一次性写入磁盘。
也正是因为现代的数据库用的都是第4种,是最灵活的一种数据刷盘策略。在这种策略下,为了实现事务的原子性和持久性,才有了如此复杂的Redo Log和Undo Log机制,才有了上面的ARIES算法。
除了在宕机恢复时对未提交的事务进行回滚,Undo Log还有两个核心作用:
(1)实现ACID中I(隔离性)。
(2)高并发。
6.6.2 Undo Log(MVCC)
在多线程编程中,读写的并发问题有三种策略,如表6-9所示。
表6-11 并发读写的三种策略
在JDK的JUC代码中,有CopyOnWriteArrayList和CopyOnWriteArraySet 两个类,有兴趣的读者可以阅读源码来理解CopyOnWrite的思想。
对比上面表格的三种并发策略可以知道,从上到下,并发度越来越高。而InnoDB用的就是CopyOnWrite思想,是在Undo Log里面实现的。每个事务修改记录之前,都会先把该记录拷贝一份出来,拷贝出来的这个备份存在Undo Log里。因为事务有唯一的编号ID,ID从小到大递增,每一次修改,就是一个版本,因此Undo Log维护了数据的从旧到新的每个版本,各个版本之间的记录通过链表串联。

也正因为每条记录都有多版本,才很容易实现事务ACID属性中的I(隔离性)。事务要并发,多个事务要读写同一条记录,为了实现第二个、第三个隔离级别,就不能让事务读取到正在修改的数据,而只能读取历史版本。
也正因为有了MVCC这种特性,通常的select语句都是不加锁的,读取的全部是数据的历史版本,从而支撑高并发的查询。这种读,专业术语叫作“快照读”,与之相对应的是“当前读”。表6-10列举了快照读和当前读对应的SQL语句,快照读就是最常用的select语句,当前读包括了加锁的select语句和insert/update/delete语句。
表6-12 快照读与当前读对应的SQL语句

6.6.3 Undo Log不是Log
了解Undo Log的功能后,进一步来看Undo Log的结构。其实Undo Log这个词有很大的迷惑性,它其实不是Log,而是数据。为什么这么说?
(1)Undo Log并不像Redo Log一样按照LSN的编号,从小到大依次执行append操作。Undo Log其实没有顺序,多个事务是并行地向Undo Log中随机写入的。
(2)一个事务一旦Commit之后,数据就“固化”了,固化之后不可能再回滚。这意味着Undo Log只在事务Commit过程中有用,一旦事务Commit了,就可以删掉UndoLog。具体来说:
对于insert记录,没有历史版本数据,因此insert的Undo Log只记录了该记录的主键ID,当事务提交之后,该Undo Log就可以删除了;
对于update/delete记录,因为MVCC的存在,其历史版本数据可能还被当前未提交的其他事务所引用,一旦未提交的事务提交了,其对应的Undo Log也就可以删除了。
所以,更应该把UndoLog叫作记录的“备份数据”,即在事务未提交之前的时间里的“备份数据”!提交事务后,没有其他事务引用历史版本了,就可以删除了。
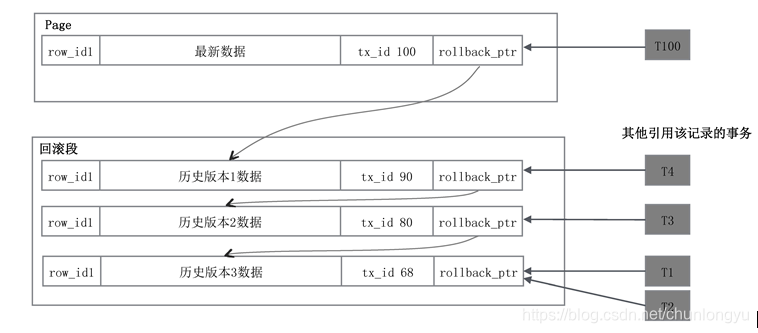
下面来看这个“备份数据”是怎么操作的。如图6-18所示,Page中的每条记录,除了自身的主键ID和数据外,还有两个隐藏字段:一个是修改该记录的事务ID,一个是rollback_ptr,用来串联所有的历史版本。假设该记录被tx_id为68、80、90、100的四个事务修改了四次,该数据就有四个版本,通过rollback_ptr从新到旧串联起来。
然后,三个历史版本分别被其他不同的事务读取。为什么会出现不同的事务读取到不同的版本呢?因为T1、T2最先,此时历史版本3是最新的,还没有历史版本1、2;之后该记录被修改,产生了历史版本2,然后出现了T3;之后该记录又被修改,产生了历史版本1,然后出现了T4。每个事务读取的都是这个事务执行时最新的历史版本。
这些历史版本什么时候可以删除呢?在T1、T2提交之后,历史版本3就可以删除了;在T3提交之后,历史版本2就可以删除了,依此类推。
图6-18 Undo Log逻辑结构
注意:在这里有一个专业名词,叫“回滚段”,很多描述Undo Log的文章花大篇幅描述它。但本书作者不想解释这个名词,因为它不仅不会帮助我们对原理的理解,还会把简单问题复杂化。说得通俗一点,就是修改记录之前先把记录拷贝一份出来,然后拷贝出来的这些历史版本形成一个链表,仅此而已。
6.6.4 Undo Log与Redo Log的关联
Undo Log本身也要写入磁盘,但一个事务修改多条记录,产生多条Undo Log,不可能同步写入磁盘,所以遇到了开篇讲Write-Ahead时的问题。如何解决Undo Log需要多次写入磁盘的效率问题呢?
Redo Log记录的是对数据的修改,凡是对数据的修改,都必须记入Redo Log。可以把Undo Log也当作数据!在内存中记录Undo Log,异步地刷盘,宕机重启,用Redo Log恢复Undo Log。
拿一个事务来举例:
start transaction
update表1某行记录
delete表1某行记录
insert表2某行记录
commit把Undo Log和Redo Log加进去,此事务类似下面伪代码所示:
start transaction
写Undo Log1: 备份该行数据(update)
update表1某行记录
写Redo Log1
Undo Log2:备份该行数据(insert)
delete 表1某行记录
写Redo Log2
Undo Log3:该行的主键ID(delete)
insert表2某行记录
写Redo Log3
commit在这里,所有Undo Log和Redo Log的写入都可以只在内存中进行,只要保证Commit之后Redo Log落盘即可,Undo Log可以一直保留在内存里,之后异步刷盘。
文章太长,未完待续,接下来的1篇,会继续分析Undo Log。
数据库原理 - 序列5 - 事务是如何实现的? - Undo Log解析的更多相关文章
- 数据库原理 - 序列4 - 事务是如何实现的? - Redo Log解析(续)
> 本文节选自<软件架构设计:大型网站技术架构与业务架构融合之道>第6.4章节. 作者微信公众号:> 架构之道与术.进入后,可以加入书友群,与作者和其他读者进行深入讨论.也可以 ...
- 数据库原理 - 序列3 - 事务是如何实现的? - Redo Log解析
6.5 事务实现原理之1:Redo Log 介绍事务怎么用后,下面探讨事务的实现原理.事务有ACID四个核心属性:A:原子性.事务要么不执行,要么完全执行.如果执行到一半,宕机重启,已执行的一半要回滚 ...
- 数据库原理 - 序列7 - Binlog与主从复制
本文节选自作者书籍<软件架构设计:大型网站技术架构与业务架构融合之道>.作者微信公众号:架构之道与术.公众号底部菜单有书友群可以加入,与作者和其他读者进行深入讨论.也可以在京东.天猫上购买 ...
- 数据库篇:mysql事务原理之MVCC视图+锁
前言 数据库的事务特性 数据并发读写时遇到的一致性问题 mysql事务的隔离级别 MVCC的实现原理 锁和隔离级别 关注公众号,一起交流,微信搜一搜: 潜行前行 1 数据库的事务特性 原子性:同一个事 ...
- Java进阶专题(二十六) 数据库原理研究与优化
前言 在一个大数据量的系统中,这些数据的存储.处理.搜索是一个非常棘手的问题. 比如存储问题:单台服务器的存储能力及数据处理能力都是有限的, 因此需要增加服务器, 搭建集群来存储海量数据. 读写性能问 ...
- [转]undo log与redo log原理分析
数据库通常借助日志来实现事务,常见的有undo log.redo log,undo/redo log都能保证事务特性,这里主要是原子性和持久性,即事务相关的操作,要么全做,要么不做,并且修改的数据能得 ...
- InnoDB事务日志(redo log 和 undo log)详解
数据库通常借助日志来实现事务,常见的有undo log.redo log,undo/redo log都能保证事务特性,undolog实现事务原子性,redolog实现事务的持久性. 为了最大程度避免数 ...
- mysql事务(一)——redo log与undo log
数据事务 即支持ACID四大特性. A:atomicity 原子性——事务中所有操作要么全部执行成功,要么全部执行失败,回滚到初始状态 C:consistency 一致性—— ...
- 数据库原理-事务隔离与多版本并发控制(MVCC)
刚来美团实习,正好是星期天,不得不说,其内部的资料很丰富,看了部分文档后,对数据库事务这块更理解了.数据库事务的ACID,大家都知道,为了维护这些性质,主要是隔离性和一致性,一般使用加锁这种方式.同时 ...
随机推荐
- C# .NET Web API 如何自訂 ModelBinder
各位好!這次要來替大家介紹的是如何在 .NET Web API 中自訂一個 ModelBinder 透過自定義的 ModelBinder 我們可以很簡單的將 QueryString 傳過來的參數綁定 ...
- SAP MM 标准采购组织的分配对于寄售采购订单收货的影响
SAP MM 标准采购组织的分配对于寄售采购订单收货的影响 PO 4100004022 是一个寄售的采购订单, 采购组织是CSAS, 工厂代码SZSP.采购信息记录也是有的, MIGO试图对该采购订单 ...
- Centos 配置开机启动脚本启动 docker 容器
Centos 配置开机启动脚本启动 docker 容器 Intro 我们的 Centos 服务器上部署了好多个 docker 容器,因故重启的时候就会导致还得手动去手动重启这些 docker 容器,为 ...
- DataPipeline丨新型企业数据融合平台的探索与实践
文 |刘瀚林 DataPipeline后端研发负责人 交流微信 | datapipeline2018 一.关于数据融合和企业数据融合平台 数据融合是把不同来源.格式.特点性质的数据在逻辑上或物理上有机 ...
- 计算器模拟器中的情怀——Free42简介
说到情怀,我首先想聊几句电子计算器的历史.电子计算器这种东西,在最近这几十年的人类发展中,曾经起到过相当重要的作用,尤其是在七十年代到九十年代初这个时期,大型的全功能电脑贵得要命,有钱有时也买不到,而 ...
- Java Excel导入导出(实战)
一.批量导入(将excel文件转成list) 1. 前台代码逻辑 1)首先在html页面加入下面的代码(可以忽略界面的样式) <label for="uploadFile" ...
- 如何创建应用程序包(C ++)
备注 如果您要创建UWP应用程序包,请参阅使用MakeAppx.exe工具创建应用程序包. 了解如何使用打包API为Windows应用商店应用创建应用包. 如果要手动创建桌面应用程序包,还可以使用使用 ...
- #Java学习之路——基础阶段二(第一篇)
我的学习阶段是跟着CZBK黑马的双源课程,学习目标以及博客是为了审查自己的学习情况,毕竟看一遍,敲一遍,和自己归纳总结一遍有着很大的区别,在此期间我会参杂Java疯狂讲义(第四版)里面的内容. 前言: ...
- jdk安装 java环境配置
登录http://www.oracle.com,下载JDK(J2SE) JDK 1.0,1.1,1.2,1.3,1.4 1.5 (JDK5.0) à支持注解.支持泛型 1.6(JDK6.0) à Se ...
- 老毛桃pe安装系统
1.准备一个空白U盘,插入电脑. 2.下载老毛桃pe 3.下载完成后,打开老毛桃,默认制作成系统盘,傻瓜操作,无需修改参数 4.打开浏览器,下载要安装的系统 www.msdn.itellyou.cn ...