分布式服务跟踪及Spring Cloud的实现
在分布式服务架构中,需要对分布式服务进行治理——在分布式服务协同向用户提供服务时,每个请求都被哪些服务处理?在遇到问题时,在调用哪个服务上发生了问题?在分析性能时,调用各个服务都花了多长时间?哪些调用可以并行执行?…… 为此,分布式服务平台就需要提供这样一种基础服务——可以记录每个请求的调用链;调用链上调用每个服务的时间;各个服务之间的拓扑关系…… 我们把这种行为称为“分布式服务跟踪”。
背景
现今业界分布式服务跟踪的理论基础主要来自于 Google 的一篇论文《Dapper, a Large-Scale Distributed Systems Tracing Infrastructure》,使用最为广泛的开源实现是 Twitter 的 Zipkin,为了实现平台无关、厂商无关的分布式服务跟踪,CNCF 发布了布式服务跟踪标准 Open Tracing。国内,淘宝的“鹰眼”、京东的“Hydra”、大众点评的“CAT”、新浪的“Watchman”、唯品会的“Microscope”、窝窝网的“Tracing”都是这样的系统。
原理
一般的,一个分布式服务跟踪系统,主要有三部分:数据收集、数据存储和数据展示。根据系统大小不同,每一部分的结构又有一定变化。譬如,对于大规模分布式系统,数据存储可分为实时数据和全量数据两部分,实时数据用于故障排查(troubleshooting),全量数据用于系统优化;数据收集除了支持平台无关和开发语言无关系统的数据收集,还包括异步数据收集(需要跟踪队列中的消息,保证调用的连贯性),以及确保更小的侵入性;数据展示又涉及到数据挖掘和分析。虽然每一部分都可能变得很复杂,但基本原理都类似。
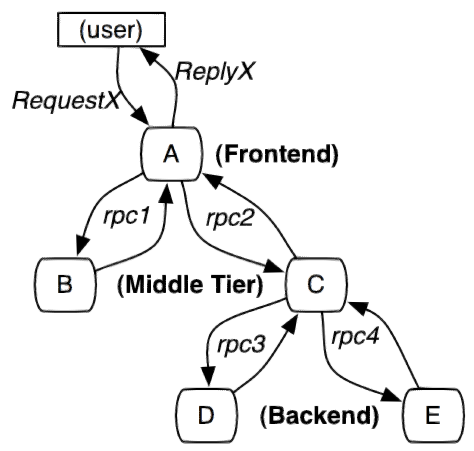
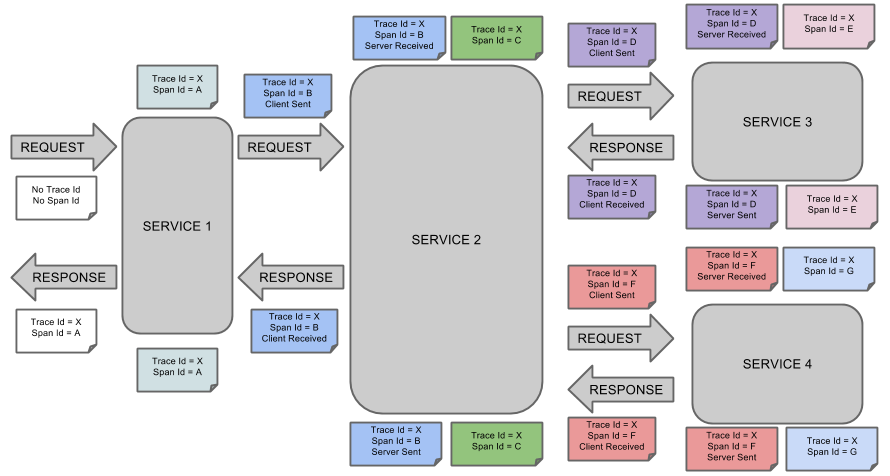
服务追踪的追踪单元是从客户发起请求(request)抵达被追踪系统的边界开始,到被追踪系统向客户返回响应(response)为止的过程,称为一个“trace”。每个 trace 中会调用若干个服务,为了记录调用了哪些服务,以及每次调用的消耗时间等信息,在每次调用服务时,埋入一个调用记录,称为一个“span”。这样,若干个有序的 span 就组成了一个 trace。在系统向外界提供服务的过程中,会不断地有请求和响应发生,也就会不断生成 trace,把这些带有span 的 trace 记录下来,就可以描绘出一幅系统的服务拓扑图。附带上 span 中的响应时间,以及请求成功与否等信息,就可以在发生问题的时候,找到异常的服务;根据历史数据,还可以从系统整体层面分析出哪里性能差,定位性能优化的目标。
实现
Spring Cloud 是基于 Java 的分布式服务平台,提供一系列的分布式服务所需的中间件。其中,用于分布式服务跟踪的模块是 Spring Cloud Sleuth。
Spring Cloud Sleuth 主要用于收集 Spring Boot 程序中的数据,即上文所说的数据收集。其包含的 spring-cloud-sleuth-zipkin 模块可以把收集到的数据发送到 zipkin 服务器。Zipkin 本身具有数据存储和展示的功能,这样,我们就可以在 Spring Boot 系统中埋入 Spring Cloud Sleuth 收集数据,在后台使用 Zipkin 服务作为数据存储和展示的服务。
使用 Zipkin 作为后台的另一个好处是,Zipkin 除了支持 Spring Cloud Sleuth 以外,还支持其他开发语言和平台的数据收集器。这使得在系统中让不同种种语言开发的服务可以共存。
首先,我们要搭建一个 Zipkin 的后台服务,然后把我们已有的 Spring Boot 服务中埋入 Spring Cloud Sleuth,最后,将 Spring Cloud Sleuth 接入 Zipkin 服务,一个非常简单的分布式服务跟踪服务就搭建起来了。
搭建 Zipkin 最简单的办法是直接使用 Zipkin 官方的 Docker 镜像。Zipkin 的存储引擎也是可以配置的,启动 Zipkin 时,如果没有配置 Zipkin 的存储引擎,那么默认 Zipkin 把数据存在内存中。这里,由于我们已经有了一个 MySQL 的高可用环境,所以配置 MySQL 为 Zipkin 的存储引擎。
# 下载镜像
docker pull openzipkin/zipkin
# 运行镜像,并指定存储引擎
docker run -d -p 9411:9411 -e MYSQL_USER=root -e MYSQL_PASS=password -e MYSQL_HOST=192.168.0.8 -e STORAGE_TYPE=mysql openzipkin/zipkin
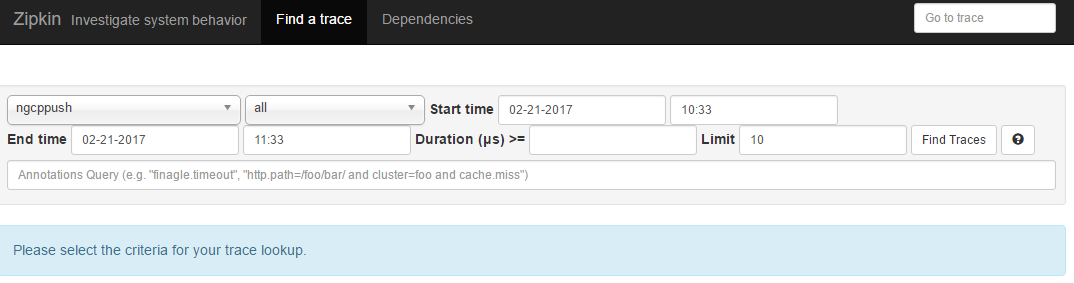
Zipkin 运行起来后,可以通过浏览器访问 9411 端口,确认 Zipkin 的运行状态。
接下来需要改造已有的 Spring Boot 服务。
首先,在 pom.xml 中引入 Spring Cloud Sleuth。因为使 zipkin 模块,所以只引入 spring-cloud-starter-zipkin即可。版本使用 Spring Cloud 统一管理。
<dependencyManagement>
<dependencies>
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-dependencies</artifactId>
<version>Camden.SR5</version>
<type>pom</type>
<scope>import</scope>
</dependency>
</dependencies>
</dependencyManagement>
...
<dependency>
<groupId>org.springframework.cloud</groupId>
<artifactId>spring-cloud-starter-zipkin</artifactId>
</dependency>
使用环境变量,或者直接在 application.properties、application.yml或 bootstrap.yml 配置文件中配置必要的属性。
spring.zipkin.baseUrl=http://zipkin.host.com:9411/
spring.sleuth.sampler.percentage=1.0
至此,Spring Boot 程序就可以把访问记录到 Zipkin 服务器中。
有些时候,譬如,访问第三方 API,或者数据库操作等场合,我们也希望在其中添加一些调用信息。那么可以手工插入一些代码来实现(俗称“埋点”)。
首先,在需要添加的类中注入Tracer。
import org.springframework.cloud.sleuth.Span;
import org.springframework.cloud.sleuth.Tracer;
...
@Autowired
private Tracer tracer;
然后,在调用之前,插入代码。
// 创建一个 span
final Span span = tracer.createSpan("3rd_service");
try {
span.tag(Span.SPAN_LOCAL_COMPONENT_TAG_NAME, "3rd_service");
span.logEvent(Span.CLIENT_SEND);
// 这里时调用第三方 API 的代码
} finally {
...
}
最后,在调用之后的 finally 中(确保异常后也被调用到),插入代码。
span.tag(Span.SPAN_PEER_SERVICE_TAG_NAME, "3rd_service");
span.logEvent(Span.CLIENT_RECV);
tracer.close(span);
通过埋点我们可以生成任意详细的调用记录,我们就可以看到哪里还欠缺监控,需要手工埋点;哪里调用时间过长,是影响性能的瓶颈;以及哪些调用可以并行,优化性能降低响应时间。
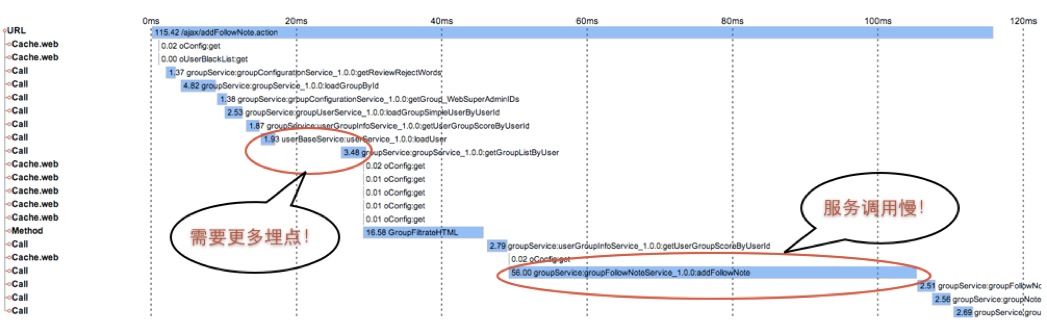
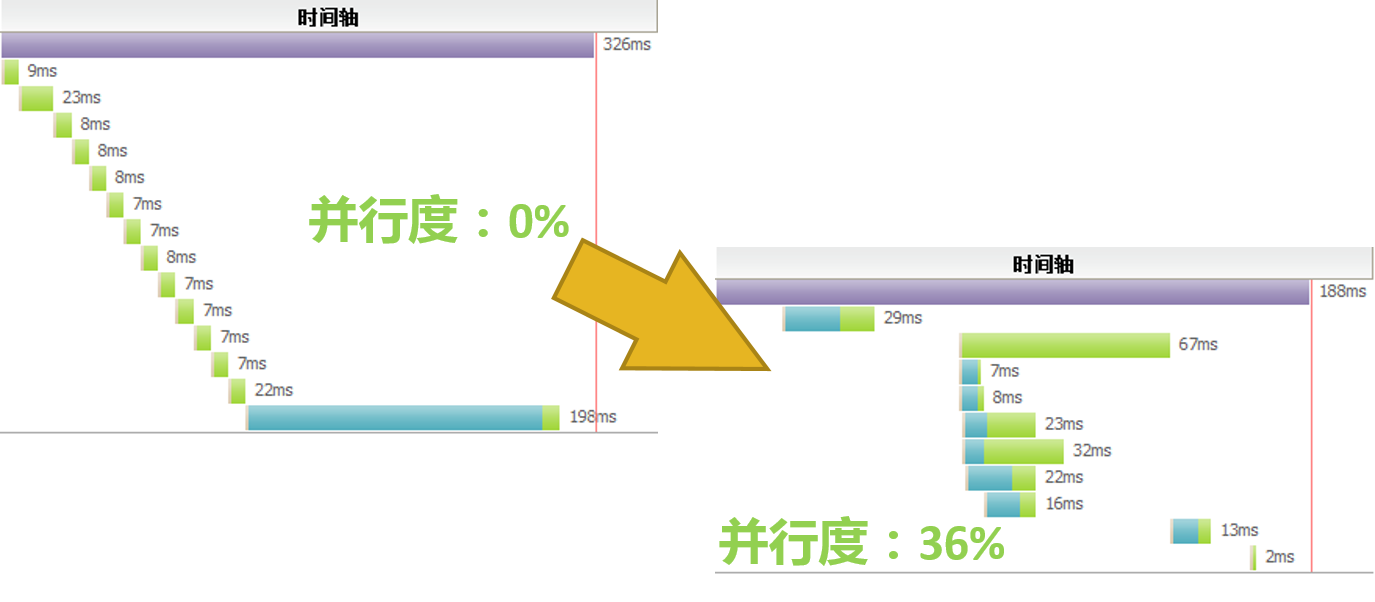
http://daixiaoyu.com/distributed-tracing.html
分布式服务跟踪及Spring Cloud的实现的更多相关文章
- 第11章 分布式服务跟踪: Spring Cloud Sleuth
通常一个由客户端发起的请求在后端系统中会经过多个不同的微服务调用来协同产生最后的请求结果, 在复杂的微服务架构系统中, 几乎每一个前端请求都会形成一条复杂的分布式服务调用链路, 在每条链路中任何一个依 ...
- 分布式服务追踪:Spring Cloud Sleuth
最近在学习Spring Cloud的知识,现将分布式服务追踪:Spring Cloud Sleuth 的相关知识笔记整理如下.[采用 oneNote格式排版]
- Spring Cloud第九篇 | 分布式服务跟踪Sleuth
本文是Spring Cloud专栏的第九篇文章,了解前八篇文章内容有助于更好的理解本文: Spring Cloud第一篇 | Spring Cloud前言及其常用组件介绍概览 Spring Cl ...
- 【Spring Cloud】Spring Cloud之Spring Cloud Sleuth,分布式服务跟踪(1)
一.Spring Cloud Sleuth组件的作用 为微服务架构增加分布式服务跟踪的能力,对于每个请求,进行全链路调用的跟踪,可以帮助我们快速发现错误根源以及监控分析每条请求链路上的性能瓶颈等. 二 ...
- 微服务架构-选择Spring Cloud,放弃Dubbo
Spring Cloud 在国内中小型公司能用起来吗?从 2016 年初一直到现在,我们在这条路上已经走了一年多. 在使用 Spring Cloud 之前,我们对微服务实践是没有太多的体会和经验的.从 ...
- 微服务架构集大成者—Spring Cloud (转载)
软件是有生命的,你做出来的架构决定了这个软件它这一生是坎坷还是幸福. 本文不是讲解如何使用Spring Cloud的教程,而是探讨Spring Cloud是什么,以及它诞生的背景和意义. 1 背景 2 ...
- springcloud 分布式服务跟踪sleuth+zipkin
原文:https://www.jianshu.com/p/6ef0b76b9c26 分布式服务跟踪需求 随着分布式服务越来越多,调用关系越来越复杂,组合接口越来越多,要进行分布式服务跟踪监控的需求也越 ...
- spring boot 2.0.3+spring cloud (Finchley)7、服务链路追踪Spring Cloud Sleuth
参考:Spring Cloud(十二):分布式链路跟踪 Sleuth 与 Zipkin[Finchley 版] Spring Cloud Sleuth 是Spring Cloud的一个组件,主要功能是 ...
- spring-cloud-sleuth分布式服务跟踪
通过之前的 Spring Cloud 组件学习, 实际上我们已经能够通过使用它们搭建起一 个基础的微服务架构系统来实现业务需求了. 但是, 随着业务的发展, 系统规模也会变得越来越大, 各微服务间的调 ...
随机推荐
- android 开发从入门到精通
Android-Tips This is an awesome list of tips for android. If you are a beginner, this list will be t ...
- Google主推-Android开发利器——Android Studio,这可能是最全的AS教程!
Android Studio使用手册 "工欲善其事必先利其器" 作为一个Android开发人员来说,一款好的开发工具也是相当重要的,在相当长的时间礼,Google都是基于Eclip ...
- OpenNMS安装手册
一. 系统需求Windows Server 2008 R2 SP1 64位JDK 8 update 5 for Windows 64位PostgreSQL 9.3.5 for Windows 64位O ...
- Tomcat的缺省是多少,怎么修改
Tomcat的缺省端口号是8080. 修改Tomcat端口号: 1.找到Tomcat目录下的conf文件夹 2.进入conf文件夹里面找到server.xml文件 3.打开server.xml文件 ...
- redis+twemproxy实现redis集群
Redis+TwemProxy(nutcracker)集群方案部署记录 转自: http://www.cnblogs.com/kevingrace/p/5685401.html Twemproxy 又 ...
- 实现CString的Format功能,支持跨平台
#include <string>#include <stdio.h> #include <stdarg.h> std::string& std_strin ...
- 怎样看Mac的日志
Mac自带的日志查看工具Console,注意Console和Terminal不是一码事,后者是CLI环境,前者是GUI日志查看工具.在应用里面搜索Console即可找到,里面的界面和Windows的日 ...
- html5 file upload and form data by ajax
html5 file upload and form data by ajax 最近接了一个小活,在短时间内实现一个活动报名页面,其中遇到了文件上传. 我预期的效果是一次ajax post请求,然后在 ...
- JAVAEE——BOS物流项目13:Quartz概述、创建定时任务、使用JavaMail发送邮件、HighCharts概述、实现区域分区分布图
1 学习计划 1.Quartz概述 n Quartz介绍和下载 n 入门案例 n Quartz执行流程 n cron表达式 2.在BOS项目中使用Quartz创建定时任务 3.在BOS项目中使用Jav ...
- SpringBoot Whitelabel Error Page This application has no explicit mapping for /error, so you are seeing this as a fallback.
使用SpringBoot写HelloWorld,当配置好启动类后,再创建新的controller或其它类,启动项目后访问对应的映射名,页面显示: Whitelabel Error Page This ...