flume原理
1. flume简介
flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用。Flume 初始的发行版本目前被统称为 Flume OG(original generation),属于 cloudera。但随着 FLume 功能的扩展,Flume OG 代码工程臃肿、核心组件设计不合理、核心配置不标准等缺点暴露出来,尤其是在 Flume OG 的最后一个发行版本 0.94.0 中,日志传输不稳定的现象尤为严重,为了解决这些问题,2011 年 10 月 22 号,cloudera 完成了 Flume-728,对 Flume 进行了里程碑式的改动:重构核心组件、核心配置以及代码架构,重构后的版本统称为 Flume NG(next generation);改动的另一原因是将 Flume 纳入 apache 旗下,cloudera Flume 改名为 Apache Flume。
2. flume特点
flume是一个分布式、可靠、和高可用的海量日志采集、聚合和传输的系统。支持在日志系统中定制各类数据发送方,用于收集数据;同时,Flume提供对数据进行简单处理,并写到各种数据接受方(比如文本、HDFS、Hbase等)的能力 。
flume的数据流由事件(Event)贯穿始终。事件是Flume的基本数据单位,它携带日志数据(字节数组形式)并且携带有头信息,这些Event由Agent外部的Source生成,当Source捕获事件后会进行特定的格式化,然后Source会把事件推入(单个或多个)Channel中。你可以把Channel看作是一个缓冲区,它将保存事件直到Sink处理完该事件。Sink负责持久化日志或者把事件推向另一个Source。
flume的可靠性 :
当节点出现故障时,日志能够被传送到其他节点上而不会丢失。Flume提供了三种级别的可靠性保障,从强到弱依次分别为:end-to-end(收到数据agent首先将event写到磁盘上,当数据传送成功后,再删除;如果数据发送失败,可以重新发送。),Store on failure(这也是scribe采用的策略,当数据接收方crash时,将数据写到本地,待恢复后,继续发送),Besteffort(数据发送到接收方后,不会进行确认)。
flume的可恢复性:
还是靠Channel。推荐使用FileChannel,事件持久化在本地文件系统里(性能较差)。
3. flume的一些核心概念:
Agent使用JVM 运行Flume。每台机器运行一个agent,但是可以在一个agent中包含多个sources和sinks。
Client生产数据,运行在一个独立的线程。
Source从Client收集数据,传递给Channel。
Sink从Channel收集数据,运行在一个独立线程。
Channel连接 sources 和 sinks ,这个有点像一个队列。
Events可以是日志记录、 avro 对象等。
Flume以agent为最小的独立运行单位。一个agent就是一个JVM。单agent由Source、Sink和Channel三大组件构成,如下图:
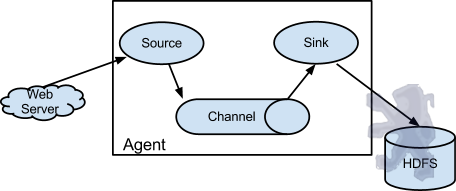
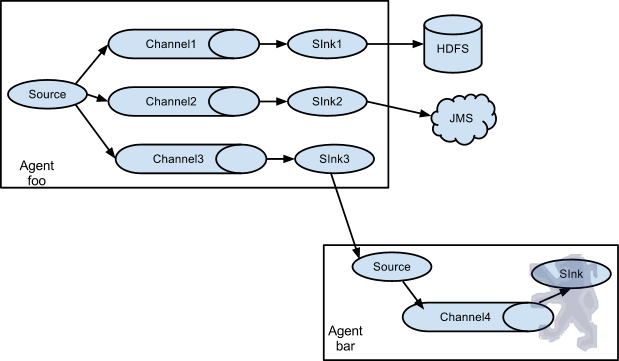
值得注意的是,Flume提供了大量内置的Source、Channel和Sink类型。不同类型的Source,Channel和Sink可以自由组合。组合方式基于用户设置的配置文件,非常灵活。比如:Channel可以把事件暂存在内存里,也可以持久化到本地硬盘上。Sink可以把日志写入HDFS, HBase,甚至是另外一个Source等等。Flume支持用户建立多级流,也就是说,多个agent可以协同工作,并且支持Fan-in、Fan-out、Contextual Routing、Backup Routes,这也正是NB之处。如下图所示:
4. 采集方案
1. 采集构架
使用flume采集日志文件的过程较简洁,只需选择恰当的source、channel和sink并且配置起来即可,若有特殊需求也可自己进行二次开发实现个人需求。

具体过程为:按照需求配置一个agent,选取适当的source和sink,然后启动该agent,开始采集日志。
1) source
flume提供多种source供用户进行选择,尽可能多的满足大部分日志采集的需求,常用的source的类型包括avro、exec、netcat、spooling-directory和syslog等。
2) channel
flume中的channel不如source和sink那么重要,但却是不可忽视的组成部分。常用的channel为memory-channel,同时也有其他类型的channel,如JDBC、file-channel、custom-channel等
3) sink
flume的sink也有很多种,常用的包括avro、logger、HDFS、hbase以及file-roll等,除此之外还有其他类型的sink,如thrift、IRC、custom等。
5. flume日志处理
Flume不止可以采集日志,还可以对日志进行简单的处理,在source处可以通过interceptor对日志正文处的重要内容进行过滤提取,在channel处可以通过header进行分类,将不同类型的日志投入不同的通道中,在sink处可以通过正则序列化来将正文内容进行进一步的过滤和分类。
1) Flume Source Interceptors
Flume可以通过interceptor将重要信息提取出来并且加入到header中,常用的interceptor有时间戳、主机名和UUID等,用户也可以根据个人需求编写正则过滤器,将某些特定格式的日志内容过滤出来,以满足特殊需求。
2) Flume Channel Selectors
Flume可以根据需求将不同的日志传输进不同的channel,具体方式有两种:复制和多路传输。复制就是不对日志进行分组,而是将所有日志都传输到每个通道中,对所有通道不做区别对待;多路传输就是根据指定的header将日志进行分类,根据分类规则将不同的日志投入到不同的channel中,从而将日志进行人为的初步分类。
3) Flume Sink Processors
Flume在sink处也可以对日志进行处理,常见的sink处理器包括custom、failover、load balancing和default等,和interceptor一样,用户也可以根据特殊需求使用正则过滤处理器,将日志内容过滤出来,但和interceptor不同的是在sink处使用正则序列化过滤出的内容不会加入到header中,从而不会使日志的header显得过于臃肿。
6. 常见agent 组件使用说明
6.1 常见source
1) avro source
avro可以监听和收集指定端口的日志,使用avro的source需要说明被监听的主机ip和端口号,下面给出一个具体的例子
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = avro
a1.sources.r1.channels = c1
a1.sources.r1.bind = 0.0.0.0
a1.sources.r1.port = 4141
2) exec source
exec可以通过指定的操作对日志进行读取,使用exec时需要指定shell命令,对日志进行读取,下面给出一个具体的例子:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = exec
a1.sources.r1.command = tail -F /var/log/secure
a1.sources.r1.channels = c1
3) spooling-directory source
spo_dir可以读取文件夹里的日志,使用时指定一个文件夹,可以读取该文件夹中的所有文件,需要注意的是该文件夹中的文件在读取过程中不能修改,同时文件名也不能修改。下面给出一个具体的例子:
agent-1.channels = ch-1
agent-1.sources = src-1
agent-1.sources.src-1.type = spooldir
agent-1.sources.src-1.channels = ch-1
agent-1.sources.src-1.spoolDir = /var/log/apache/flumeSpool
agent-1.sources.src-1.fileHeader = true
4) syslog source
syslog可以通过syslog协议读取系统日志,分为tcp和udp两种,使用时需指定ip和端口,下面给出一个udp的例子:
a1.sources = r1
a1.channels = c1
a1.sources.r1.type = syslogudp
a1.sources.r1.port = 5140
a1.sources.r1.host = localhost
a1.sources.r1.channels = c1
6.2 常见channel
Flume的channel种类并不多,最常用的是memory channel,下面给出例子:
a1.channels = c1
a1.channels.c1.type = memory
a1.channels.c1.capacity = 10000
a1.channels.c1.transactionCapacity = 10000
a1.channels.c1.byteCapacityBufferPercentage = 20
a1.channels.c1.byteCapacity = 800000
6.3 常见sinks
1) logger sink
logger顾名思义,就是将收集到的日志写到flume的log中,是个十分简单但非常实用的sink。
2) avro sink
avro可以将接受到的日志发送到指定端口,供级联agent的下一跳收集和接受日志,使用时需要指定目的ip和端口:例子如下:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = avro
a1.sinks.k1.channel = c1
a1.sinks.k1.hostname = 10.10.10.10
a1.sinks.k1.port = 4545
3) file roll sink
file_roll可以将一定时间内收集到的日志写到一个指定的文件中,具体过程为用户指定一个文件夹和一个周期,然后启动agent,这时该文件夹会产生一个文件将该周期内收集到的日志全部写进该文件内,直到下一个周期再次产生一个新文件继续写入,以此类推,周而复始。下面给出一个具体的例子:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = file_roll
a1.sinks.k1.channel = c1
a1.sinks.k1.sink.rollInterval=0
a1.sinks.k1.deserializer.maxBlobLength = 2000000000
a1.sinks.k1.batchSize=1
a1.sinks.k1.sink.directory = /var/log/flume
4) hdfs sink
hdfs与file roll有些类似,都是将收集到的日志写入到新创建的文件中保存起来,但区别是file roll的文件存储路径为系统的本地路径,而hdfs的存储路径为分布式的文件系统hdfs的路径,同时hdfs创建新文件的周期可以是时间,也可以是文件的大小,还可以是采集日志的条数。具体实例如下:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hdfs
a1.sinks.k1.channel = c1
a1.sinks.k1.hdfs.path = /flume/events/%y-%m-%d/%H%M/%S
a1.sinks.k1.hdfs.filePrefix = events-
a1.sinks.k1.hdfs.round = true
a1.sinks.k1.hdfs.roundValue = 10
a1.sinks.k1.hdfs.roundUnit = minute
5) hbase sink
hbase是一种数据库,可以储存日志,使用时需要指定存储日志的表名和列族名,然后agent就可以将收集到的日志逐条插入到数据库中。例子如下:
a1.channels = c1
a1.sinks = k1
a1.sinks.k1.type = hbase
a1.sinks.k1.table = foo_table
a1.sinks.k1.columnFamily = bar_cf
a1.sinks.k1.serializer = org.apache.flume.sink.hbase.RegexHbaseEventSerializer
a1.sinks.k1.channel = c1
flume原理的更多相关文章
- flume原理及代码实现
转载标明出处:http://www.cnblogs.com/adealjason/p/6240122.html 最近想玩一下流计算,先看了flume的实现原理及源码 源码可以去apache 官网下载 ...
- Flume(一)Flume原理解析
前言 最近有一点浮躁,遇到了很多不该发生在我身上的事情.没有,忘掉这些.好好的学习,才是正道! 一.Flume简介 flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应 ...
- Flume原理解析【转】
一.Flume简介 flume 作为 cloudera 开发的实时日志收集系统,受到了业界的认可与广泛应用.Flume 初始的发行版本目前被统称为 Flume OG(original generati ...
- Flume原理分析与使用案例
1.flume的特点: flume是一个分布式.可靠.和高可用的海量日志采集.聚合和传输的系统.支持在日志系统中定制各类数据发送方,用于收集数据:同时,Flume提供对数据进行简单处理,并写到各种数据 ...
- 海量日志采集Flume(HA)
海量日志采集Flume(HA) 1.介绍: Flume是Cloudera提供的一个高可用的,高可靠的,分布式的海量日志采集.聚合和传输的系统,Flume支持在日志系统中定制各类数据发送方,用于收集数据 ...
- 【Flume学习之二】Flume 使用场景
环境 apache-flume-1.6.0 一.多agent连接 1.node101配置 option2 # Name the components on this agent a1.sources ...
- 【Flume学习之一】Flume简介
环境 apache-flume-1.6.0 Flume是分布式日志收集系统.可以将应用产生的数据存储到任何集中存储器中,比如HDFS,HBase:同类工具:Facebook Scribe,Apache ...
- flume面试题
1 你是如何实现Flume数据传输的监控的使用第三方框架Ganglia实时监控Flume. 2 Flume的Source,Sink,Channel的作用?你们Source是什么类型?1.作用 (1)S ...
- 吴超hadoop7天视频教程全集
吴超hadoop7天视频教程全集 一.初级班全套视频 1.linux使用(3节) 2.伪分布模式安装hadoop(2节) 3.HDFS的体系结构和操作(2节) 4.HDFS的java操作方式(4节) ...
随机推荐
- Python代码运行助手
将下述demo文件保存下来,比如存为learning.py 然后运行,如果出现: Ready for Python code on port 39093... 则说明成功了. demo #!/usr/ ...
- [信号处理技术]关于EMD的产生
通俗易懂,有助于理解EMD和HHT,就原封不动的搬过来了. 原文链接:关于EMD的产生 自傅里叶变换与频谱分析技术产生,人们得以从另外一个角度观察时域信号,信号里各个点的密集程度,得以确定性地度量.之 ...
- 【Android 应用开发】Ubuntu 下 Android Studio 开发工具使用详解 (旧版本 | 仅作参考)
. 基本上可以导入项目开始使用了 ... . 作者 : 万境绝尘 转载请注明出处 : http://blog.csdn.net/shulianghan/article/details/21035637 ...
- 怎样使用projectproperty sheet(.vsprops)来管理工程
怎样使用projectproperty sheet(.vsprops)来管理工程 IDE:VS2005 前言 Project Property Sheet的意思是项目属性表,在大型项目中基本上都会使用 ...
- android Timer与TimerTask的相关操作
项目上面的部分操作需要使用到定时器进行周期性的控制.网络上面对于定时器的操作通常有三种实现方法. 我是通过Timer与TimerTask相结合实现的定时器功能.具体实现过程如下: 第一步,得到Time ...
- iOS 网络编程模式总结
IOS 可以采用三类api 接口进行网络编程,根据抽象层次从低到高分别为socket方式.stream方式.url 方式. 一 .socket 方式 IOS 提供的socket 方式的网络编程接口为C ...
- Android 开发中遇到Read-only file system问题解决方案
问题描述: 在往scdcard中复制mp3文件时,复制不成功.查看了一下sdcard里面没有内容,且无法直接在里面创建文件会出现-- read only file system类似的内容提示. ...
- 一个类搞定UIScrollView那些事儿
前言 UIScrollView可以说是我们在日常编程中使用频率最多.扩展性最好的一个类,根据不同的需求和设计,我们都能玩出花来,当然有一些需求是大部分应用通用的,今天就聊一下以下需求,在一个categ ...
- 【43】Activity的几种LaunchMode及使用场景
standard 模式 这是默认模式,每次激活Activity时都会创建Activity实例,并放入任务栈中.使用场景:大多数Activity. singleTop 模式 如果在任务的栈顶正好存在该A ...
- C++之多继承
#include <iostream> using namespace std ; class AA { public: int a ; void Say_hello(void) { co ...