Java集合中的LinkedHashMap类
jdk1.8.0_144
本文阅读最好先了解HashMap底层,可前往《Java集合中的HashMap类》。
LinkedHashMap由于它的插入有序特性,也是一种比较常用的Map集合。它继承了HashMap,很多方法都直接复用了父类HashMap的方法。本文将探讨LinkedHashMap的内部实现,以及它是如何保证插入元素是按插入顺序排序的。
在分析前可以先思考下,既然是按照插入顺序,并且以Linked-开头,就很有可能是链表实现。如果纯粹以链表实现,也不是不可以,LinkedHashMap内部维护一个链表,插入一个元素则把它封装成Entry节点,并把它插入到链表尾部。功能可以实现,但这带来的查找效率达到了O(n),显然远远大于HashMap在没有冲突的情况下O(1)的时间复杂度。这就丝毫不能体现出Map这种数据结构随机存取快的优点。
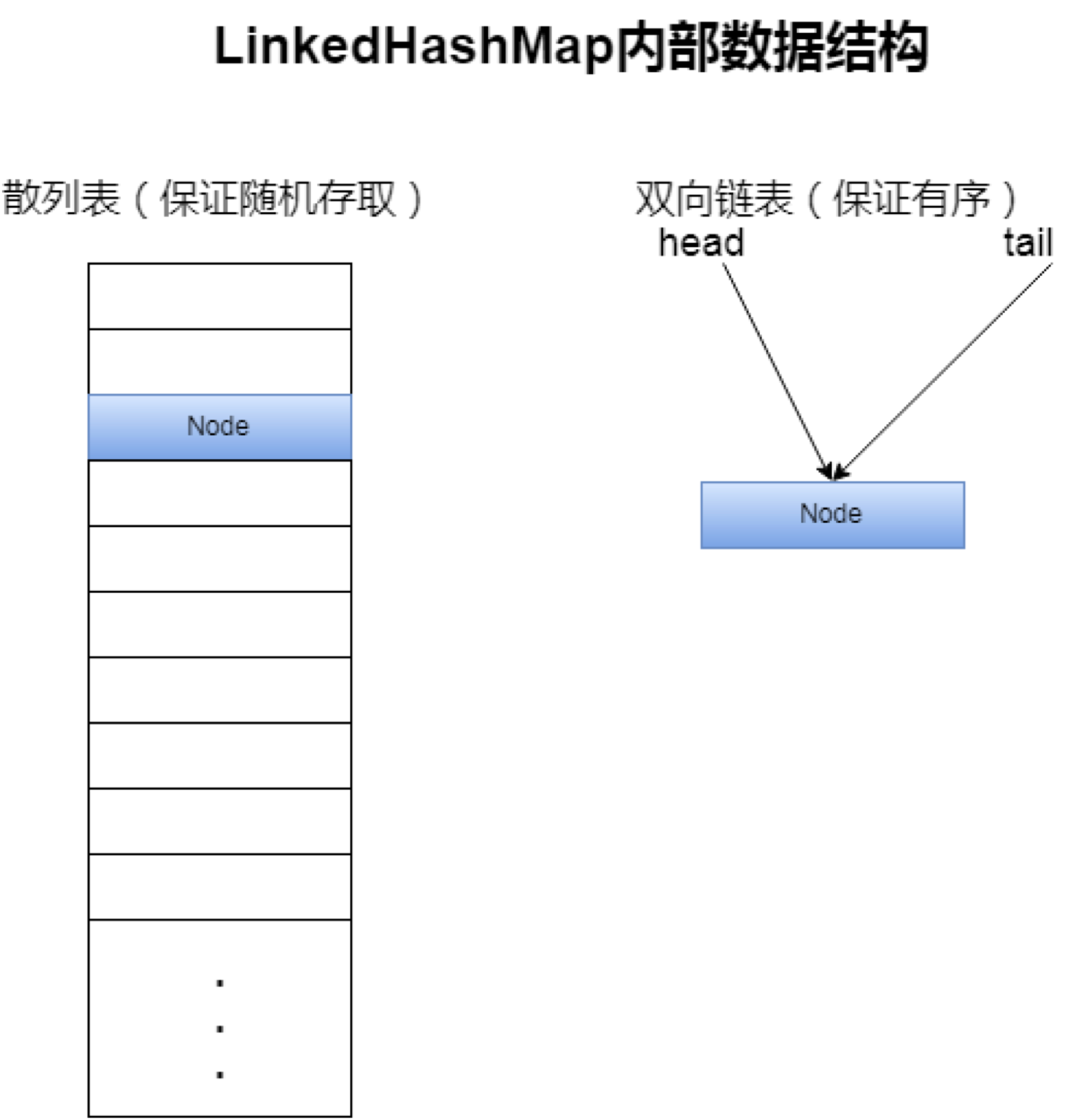
所以显然,LinkedHashMap不可能只有一个链表来维护Entry节点,它极有可能维护了两种数据结构:散列表+链表。
为便于理解,将不会分析每个方法,会从插入开始分析LinkedHashMap的数据结构及实现。
LinkedHashMap继承了HashMap类,并且没有重写put方法,而是直接沿用了HashMap#put方法。有关HashMap#put已经在《Java集合中的HashMap类》有了较为详细的介绍。从调用HashMap#put方法可知,它的插入过程和HashMap相同,也就是说它也一样有着和HashMap相同的散列表结构。不过要小心尽管调用的是HashMap#put方法,但在这个方法中有一个方法是构造一个新节点newNode,这里LinkedHashMap重写了,所以调用的是LinkedHashMap#newNode,也正是这个方法实现了对LinkedHashMap链表的维护。
忽略其余代码,关键代码在HashMap#putVal中tab[i] = newNode(hash, key, value, null),稍后再来查看LinkedHashMap#newNode方法。
其过程先用图例来说明。
链表插入过程如下代码所示:
//LinkedHashMap#newNode,构造一个新的节点
Node<K,V> newNode(int hash, K key, V value, Node<K,V> e) {
LinkedHashMap.Entry<K,V> p =
new LinkedHashMap.Entry<K,V>(hash, key, value, e);
linkNodeLast(p);
return p;
}
//LinkedHashMap#linkNodeLast,插入到链表尾部
private void linkNodeLast(LinkedHashMap.Entry<K,V> p) {
LinkedHashMap.Entry<K,V> last = tail; //LinkedHashMap定义了tail尾指针和head头指针,且链表为双向链表
tail = p;
if (last == null)
head = p;
else {
//双向链表的插入
p.before = last;
last.after = p;
}
}
对于LinkedHashMap插入,散列表部分和HashMap一致,而双向链表部分则是来一个就插到尾部,这样就保证了保持插入顺序。
通过插入基本了解了LinkedHashMap的内部实现,get方法很简单,同样是计算出key的hash和对应散列表的下标即可。
在LinkedHashMap还需要提到三个方法,这三个方法在HashMap中定义,但是并没有具体实现,具体实现放到了LinkedHashMap中。
void afterNodeAccess(Node<K,V> p)
此方法可以实现通过访问顺序排序,方法中如果定义accessOrder=true,则会将访问(get)过的元素放到链表尾部。accessOrder设置可以通过构造方法传递。
void afterNodeInsertion(boolean evict)
这个方法在LinkedHashMap并无意义,因为它调用的removeEldestEntry始终返回false,此时程序就会返回不会执行。但如果重写了removeEldestEntry方法,则可以实现LRU(最近最少使用)缓存。
void afterNodeRemoval(Node<K,V> p)
移除Map中的元素时调用,更新双向链表。
这是一个能给程序员加buff的公众号 
Java集合中的LinkedHashMap类的更多相关文章
- Java集合中的HashMap类
jdk1.8.0_144 HashMap作为最常用集合之一,继承自AbstractMap.JDK8的HashMap实现与JDK7不同,新增了红黑树作为底层数据结构,结构变得复杂,效率变得更高.为满足自 ...
- Java集合中List,Set以及Map等集合体系详解
转载请注明出处:Java集合中List,Set以及Map等集合体系详解(史上最全) 概述: List , Set, Map都是接口,前两个继承至collection接口,Map为独立接口 Set下有H ...
- Java集合中List、Set以及Map
概述: List , Set, Map都是接口:List , Set继承至Collection接口,Map为独立接口 Set下有HashSet,LinkedHashSet,TreeSet List下有 ...
- java集合中List与set的区别
java集合中List与set的区别. List可以存储元素为有序性并且元素可以相同. set存储元素为无序性并且元素不可以相同. 下面贴几段代码感受一下: ArrayL ...
- Java集合框架(常用类) JCF
Java集合框架(常用类) JCF 为了实现某一目的或功能而预先设计好一系列封装好的具有继承关系或实现关系类的接口: 集合的由来: 特点:元素类型可以不同,集合长度可变,空间不固定: 管理集合类和接口 ...
- Java集合中Comparator和Comparable接口的使用
在Java集合中,如果要比较引用类型泛型的List,我们使用Comparator和Comparable两个接口. Comparable接口 -- 默认比较规则,可比较的 实现该接口表示:这个类的实例可 ...
- Java集合中Set的常见问题及用法
在这里演示的案例是衔接Java集合中的List(点击查看)那篇博文的,本节我们学习的Set的用法. Set是Collection的一个重要的子接口,Set中的元素是无序排列的,并且元素不可以重复,被称 ...
- Java最重要的21个技术点和知识点之JAVA集合框架、异常类、IO
(三)Java最重要的21个技术点和知识点之JAVA集合框架.异常类.IO 写这篇文章的目的是想总结一下自己这么多年JAVA培训的一些心得体会,主要是和一些java基础知识点相关的,所以也希望能分享 ...
- 【java集合框架源码剖析系列】java源码剖析之java集合中的折半插入排序算法
注:关于排序算法,博主写过[数据结构排序算法系列]数据结构八大排序算法,基本上把所有的排序算法都详细的讲解过,而之所以单独将java集合中的排序算法拿出来讲解,是因为在阿里巴巴内推面试的时候面试官问过 ...
随机推荐
- [UWP]做个调皮的BusyIndicator
1. 前言 最近突然想要个BusyIndicator.做过WPF开发的程序员对BusyIndicator应该不陌生,Extended WPF Toolkit 提供了BusyIndicator的开源实现 ...
- 微博爬虫“免登录”技巧详解及 Java 实现(业余草的博客)
一.微博一定要登录才能抓取? 目前,对于微博的爬虫,大部分是基于模拟微博账号登录的方式实现的,这种方式如果真的运营起来,实际上是一件非常头疼痛苦的事,你可能每天都过得提心吊胆,生怕新浪爸爸把你的那些账 ...
- uva12325 暴力枚举
这题刚开始我就贪心,直接wrong了,贪心适合可以取一个物体部分的题. 还是老实枚举吧,注意枚举要分类,不然可能会超时,还有注意答案是long long AC代码: #include<cstdi ...
- 约瑟夫环-循环队列算法(曾微软,google笔试题)
这也是我们聚会时常常做的游戏之一. 算法思路: 此处我使用循环链表模拟人围城一圈,每一个结点代表一个人.链表是一个有序链表,链表结点数据域是一个整型,代表人的序号.出局等同于链表删除元素,每次出局后重 ...
- SQL注入攻击三部曲之入门篇
SQL注入攻击三部曲之入门篇 服务器安全管理员和攻击者的战争仿佛永远没有停止的时候,针对国内网站的ASP架构的SQL注入攻击又开始大行其道.本篇文章通过SQL注入攻击原理引出SQL注入攻击的实施方法, ...
- 如何拼接FusionCharts的JSON格式的双轴图
1.问题背景 假如,项目中遇到这样一个问题:利用FusionCharts中的JSON格式拼接双轴图,并将JSON字符串转换成JSON对象传输到前台,在页面上展示出来. 2.设计源码 /** * * @ ...
- 如何修改64位Eclipse中的代码字体大小
1.双击打开Eclipse,如下图所示: 2.找到菜单栏中的Window,单击它,选择Preferences 3.在左侧的树形菜单中找到General--->Appearance--->C ...
- windows驱动之WDF---CharSample
驱动程序部分: NTSTATUS DriverEntry( IN PDRIVER_OBJECT DriverObject, IN PUNICODE_STRING RegistryPath ) /*++ ...
- fineuploader使用实例
1.Fine Uploader特点 Fine Uploader Features: A:支持文件上传进度显示. B:文件拖拽浏览器上传方式 C:Ajax页面无刷新. D:多文件上传. F:跨浏览器. ...
- TypeError: Error #1034: 强制转换类型失败:无法将 "" 转换为 Array。
1.错误描述 TypeError: Error #1034: 强制转换类型失败:无法将 "" 转换为 Array. at mx.charts.series::LineSeries/ ...