bs4模块
一、导入模块
from bs4 import BeautifulSoup
二、创建对象
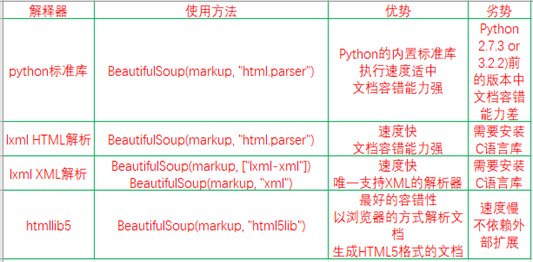
Beautiful Soup支持Python标准库中的HTML解析器,还支持一些第三方的解析器,如果我们不安装它,则 Python 会使用 Python默认的解析器,lxml 解析器更加强大,速度更快,推荐安装。
html = """
<html>
<head><title>A Tale of Two Cities</title></head>
<body>
<p class="title" name="dromouse"><b>A Tale of Two Cities</b></p>
<p class="story">
It was the best of times;It was the worst of times.
<a href="http://example.com/age" class="of" id="link1">It was the age of wisdom;it was the age of foolishness </a>.
<a href="http://example.com/epoch" class="of" id="link2">It was the epoch of belief;it was the epoch of incredulity </a>.
<a href="http://example.com/season" class="of" id="link3">It was the season of Light;it was the season of Darkness </a>.
It was the spring of hope;it was the winter of despair.
</p>
<h2 class="story"> <!-- This is comment --> </h2>
<h3 class="hey"> Hey<!-- Now --> </h3>
<h4>Well Done</h4>
</body>
</html>
"""
soup = BeautifulSoup(html, features="lxml")
#另外,我们还可以用本地 HTML 文件来创建对象,例如
soup = BeautifulSoup(open('index.html'), features="lxml")
#上面这句代码便是将本地 index.html 文件打开,用它来创建 soup 对象
三、对象的方法属性调用
1、对象归类
Beautiful Soup 将复杂HTML文档转换成一个复杂的树形结构,每个节点都是 Python 对象,所有对象可以归纳为4种:Tag,NavigableString,BeautifulSoup,Comment。
1)、TAG
print soup.p #获取p标签,它查找的是所有内容中第一个符合要求的标签
print soup.title #获取title标签
print soup.p.attrs #获取p标签属性
print soup.p["class"] #获取p标签的class属性值
print soup.p.get("class") #获取p标签的class属性值
soup.p['class']="newClass" #对p标签的class属性值进行修改
2)、NavigableString
既然我们已经得到了标签的内容,那么问题来了,我们要想获取标签内部的文字怎么办呢?很简单,用 .string 即可,例如:
print soup.p.string #获取标签的文本内容
3)、BeautifulSoup
BeautifulSoup 对象表示的是一个文档的全部内容.大部分时候,可以把它当作 Tag 对象,是一个特殊的 Tag,我们可以分别获取它的类型,名称,以及属性来感受一下:
print soup.name #获取soup的name:[document]
print type(soup) #获取soup的name的类型:<type 'unicode'>
print soup.attrs #获取soup的属性:{}
4)、Comment
Comment 对象是一个特殊类型的 NavigableString 对象,其实输出的内容仍然不包括注释符号,但是如果不好好处理它,可能会对我们的文本处理造成意想不到的麻烦。
print soup.h2.string #获取h2标签的文本内容是:This is comment
print type(soup.h2.string) #类型是:<class 'bs4.element.Comment'>
print soup.h3.string #获取h3标签的文本内容是:Hey
print type(soup.h3.string) #类型是:<type 'NoneType'>
print soup.h4.string #获取h4标签的文本内容是:Well Done
print type(soup.h4.string) #类型是:<class'bs4.element.NavigableString'>
2、遍历对象--文档树
1)、子节点
print type(soup.p.children) # 类型是: <type 'listiterator'>
print len(list(soup.p.children)) #获取子节点数
for i in soup.p.children: #遍历所有子节点
print i print type(soup.p.descendants) # 类型是: <type 'generator'>
print len(list(soup.p.descendants)) #获取子节点数
for j in soup.p.descendants: #遍历所有子节点(但是它把每个节点文本内容也当成了一个循环遍历,所以遍历的时候可以直接获取内容)
print j
2)、父节点
print type(soup.p.parent) # 类型是: <class 'bs4.element.Tag'>
print len(list(soup.p.parent)) #获取父节点数
for i in soup.p.parent: #遍历父节点所有对象
print i print type(soup.p.parenst) # 类型是: <type 'generator'>
print len(list(soup.p.parents)) #获取所有父节点数
for j in soup.p.parents: #遍历所有父节点的对象
print j
3)、兄弟节点
print type(bs.p.next_sibling) #p标签下一个兄弟标签类型是:<class 'bs4.element.Tag'>
print len(list(bs.p.next_sibling)) #p标签下一个兄弟标签节点数
for i in bs.p.next_sibling: #遍历p标签下一个兄弟标签节点对象
print i #.next_sibling 属性获取了该节点的下一个兄弟节点。 .previous_sibling 则与之相反,如果节点不存在,则返回 None print type(bs.p.next_siblings) #p标签个所有标签类型是:<type 'generator'>
print len(list(bs.p.next_siblings)) #p标签个所有兄弟标签节点数
for j in bs.p.next_siblings: #遍历p标签个所有兄弟标签节点对象
print j #.next_siblings 属性获取了该节点的下个所有兄弟节点。 .previous_siblings 则与之相反,如果节点不存在,则返回 None
4)、前后节点
#知识点:.next_element .previous_element 属性
#与 .next_sibling .previous_sibling 不同,它并不是针对于兄弟节点,而是在所有节点,不分层次
#比如 head 节点为:<head><title>The Dormouse's story</title></head>
#那么它的下一个节点便是 title,它是不分层次关系的
print soup.head.next_element #<title>The Dormouse's story</title> #所有前后节点--知识点:.next_elements .previous_elements 属性
$通过 .next_elements 和 .previous_elements 的迭代器就可以向前或向后访问文档的解析内容,就好像文档正在被解析一样
5)、文本内容
print type(bs.p.string) #p标签内容类型是:<class 'bs4.element.NavigableString'>
print len(list(bs.p.string)) #p标签内容节点数 print type(bs.p.strings) #p标签内容类型是:<class 'bs4.element.NavigableString'>
print len(list(bs.p.strings)) #p标签所有内容节点数
for i in bs.p.strings: #遍历内容
print i
#.strings获取多个内容,不过需要遍历获取,输出的字符串中可能包含了很多空格或空行,使用 .stripped_strings 可以去除多余空白内容
3、搜索文档树
1)、find_all( name , attrs , recursive , text , **kwargs )
#传字符串
'''最简单的过滤器是字符串.在搜索方法中传入一个字符串参数,Beautiful Soup 会查找与字符串完整匹配的内容,下面的例子用于查找文档中所有的 标签'''
soup.find_all('b')
#传正则表达式
'''如果传入正则表达式作为参数,Beautiful Soup 会通过正则表达式的 match() 来匹配内容.下面例子中找出所有以b开头的标签,这表示 和 标签都应该被找到'''
soup.find_all(re.compile("^b"))
#传列表
'''如果传入列表参数,Beautiful Soup 会将与列表中任一元素匹配的内容返回.下面代码找到文档中所有 <a> 标签和 <b> 标签'''
soup.find_all(["a", "b"])
#传 True
'''True 可以匹配任何值,下面代码查找到所有的 tag,但是不会返回字符串节点'''
soup.find_all(True)
#传方法
'''如果没有合适过滤器,那么还可以定义一个方法,方法只接受一个元素参数 [4] ,如果这个方法返回 True 表示当前元素匹配并且被找到,如果不是则反回 False
下面方法校验了当前元素,如果包含 class 属性却不包含 id 属性,那么将返回 True'''
def has_class_but_no_id(tag):
return tag.has_attr('class') and not tag.has_attr('id')
soup.find_all(has_class_but_no_id)
#keyword 参数
'''注意:如果一个指定名字的参数不是搜索内置的参数名,搜索时会把该参数当作指定名字 tag 的属性来搜索,如果包含一个名字为 id 的参数,Beautiful Soup 会搜索每个 tag 的 ”id” 属性
soup.find_all(id='link2')
如果传入 href 参数,Beautiful Soup 会搜索每个 tag 的 ”href” 属性
soup.find_all(href=re.compile("elsie"))
使用多个指定名字的参数可以同时过滤 tag 的多个属性
soup.find_all(href=re.compile("elsie"), id='link1')
在这里我们想用 class 过滤,不过 class 是 python 的关键词,这怎么办?加个下划线就可以
soup.find_all("a", class_="sister")
有些 tag 属性在搜索不能使用,比如 HTML5 中的 data-* 属性
data_soup = BeautifulSoup('<div data-foo="value">foo!</div>')
data_soup.find_all(data-foo="value")
# SyntaxError: keyword can't be an expression
但是可以通过 find_all() 方法的 attrs 参数定义一个字典参数来搜索包含特殊属性的tag
data_soup.find_all(attrs={"data-foo": "value"})'''
#text 参数
'''通过 text 参数可以搜搜文档中的字符串内容.与 name 参数的可选值一样, text 参数接受 字符串 , 正则表达式 , 列表, True
soup.find_all(text="Elsie")'''
#limit 参数
'''find_all() 方法返回全部的搜索结构,如果文档树很大那么搜索会很慢.如果我们不需要全部结果,可以使用 limit 参数限制返回结果的数量.效果与 SQL 中的 limit 关键字类似,当搜索到的结果数量达到 limit 的限制时,就停止搜索返回结果.
文档树中有3个 tag 符合搜索条件,但结果只返回了2个,因为我们限制了返回数量
soup.find_all("a", limit=2)'''
#recursive 参数
'''调用 tag 的 find_all() 方法时,Beautiful Soup 会检索当前 tag 的所有子孙节点,如果只想搜索 tag 的直接子节点,可以使用参数 recursive=False。'''
参数分析
2)、find( name , attrs , recursive , text , **kwargs )
3)、find_parents() fin_parent()
4)、find_next_siblings() find_next_sibling()
5)、find_previous_siblings() find_previous_sibling()
6)、find_all_next() find_next()
7)、find_all_previous() 和 find_previous()
4、css选择器
我们在写 CSS 时,标签名不加任何修饰,类名前加点,id名前加#,在这里我们也可以利用类似的方法来筛选元素,用到的方法是 soup.select(),返回类型是 list。
1)、通过标签名查找
print soup.select('title')
#[<title>The Dormouse's story</title>]
2)、通过类名查找
print soup.select('.sister')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
3)、通过 id 名查找
print soup.select('#link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
4)、组合查找
组合查找即和写 class 文件时,标签名与类名、id 名进行的组合原理是一样的,例如查找 p 标签中,id 等于 link1 的内容,二者需要用空格分开
print soup.select('p #link1')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
#直接子标签查找
print soup.select("head > title")
#[<title>The Dormouse's story</title>]
5)、属性查找
查找时还可以加入属性元素,属性需要用中括号括起来,注意属性和标签属于同一节点,所以中间不能加空格,否则会无法匹配到。
print soup.select('a[class="sister"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>, <a class="sister" href="http://example.com/lacie" id="link2">Lacie</a>, <a class="sister" href="http://example.com/tillie" id="link3">Tillie</a>]
print soup.select('a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
#同样,属性仍然可以与上述查找方式组合,不在同一节点的空格隔开,同一节点的不加空格
print soup.select('p a[href="http://example.com/elsie"]')
#[<a class="sister" href="http://example.com/elsie" id="link1"><!-- Elsie --></a>]
bs4模块的更多相关文章
- python 全栈开发,Day83(博客系统子评论,后台管理,富文本编辑器kindeditor,bs4模块)
一.子评论 必须点击回复,才是子评论!否则是根评论点击回复之后,定位到输入框,同时加入@评论者的用户名 定位输入框 focus focus:获取对象焦点触发事件 先做样式.点击回复之后,定位到输入框, ...
- 8. 博客系统| 富文本编辑框和基于bs4模块防御xss攻击
views.py @login_required def cn_backend(request): article_list = models.Article.objects.filter(user= ...
- 解决pycharm不能导入bs4模块问题
问题描述: 在导入bs4模块时有报错提示 “ Traceback (most recent call last): File "E:/project/code/py-pengfu/py-pf ...
- 爬虫模块介绍--Beautifulsoup (解析库模块,正则)
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.它能够通过你喜欢的转换器实现惯用的文档导航,查找,修改文档的方式.Beautiful Soup会帮你节省数小时 ...
- 爬虫模块介绍--request(发送请求模块)
爬虫:可见即可爬 # 每个网站都有爬虫协议 基础爬虫需要使用到的三个模块 requests 模块 # 模拟发请求的模块 PS:python原来有两个模块urllib和urllib的升级urlli ...
- 【python】python打包生成的exe文件运行时提示缺少模块
事情是这样的我用打包命令:pyinstaller -F E:\python\clpicdownload\mypython.py打包了一个exe程序,但是运行时提示我缺 少bs4模块然后我就去查pyin ...
- ImportError: No module named bs4错误解决方法
前言:毕业论文打算用Python做爬虫爬一些数据,最近开始入门Python: 在学习的时候遇到一个问题,按照看的文章安装了Python,也配置了相应的环境(使用window系统),使用pycharm编 ...
- python bs4 BeautifulSoup
Beautiful Soup 是一个可以从HTML或XML文件中提取数据的Python库.bs4 模块的 BeautifulSoup 配合requests库可以写简单的爬虫. 安装 命令:pip in ...
- from bs4 import BeautifulSoup 引入需要安装的文件和步骤
调用beautifulsoup库时,运行后提示错误: ImportError: No module named bs4 , 意思就是没有找到bs4模块,所以解决方法就是将bs4安装上,具体步骤如下: ...
随机推荐
- 进阶!基于CentOS7系统使用cobbler实现单台服务器批量自动化安装不同版本系统(week3_day5_part2)-技术流ken
前言 在上一篇博文<cobbler批量安装系统使用详解-技术流ken>中已经详细讲解了cobbler的使用以及安装,本篇博文将会使用单台cobbler实现自动化批量安装不同版本的操作系统. ...
- golang实现aes-cbc-256加密解密过程记录
我为什么吃撑了要实现go的aes-cbc-256加密解密功能? 之前的项目是用php实现的,现在准备用go重构,需要用到这个功能,这么常用的功能上网一搜一大把现成例子,于是基于go现有api分分钟实现 ...
- (转载)IQueryable和IEnumerable
第一篇:https://www.cnblogs.com/zgqys1980/p/4047315.html: 第二篇:https://www.cnblogs.com/shenbing/p/5394228 ...
- 38.QT-QAxObject快速写入EXCEL示例
参考链接:https://blog.csdn.net/czyt1988/article/details/52121360 http://blog.sina.com.cn/s/blog_a6fb6cc9 ...
- 委托的多线程方法BeginInvoke
同步方法和异步方法: 同步方法调用在程序继续执行之前需要等待同步方法执行完毕返回结果.(比如烧水泡茶,需要等水烧开了才能继续泡茶) 异步方法则在被调用之后立即返回以便程序在被调用方法完成其任务的同时执 ...
- 在 DotNetCore 3.0 程序中使用通用协议方式启动文件关联应用
问题描述 在传统的基于 .NET Framework 的 WPF 程序中,我们可以使用如下代码段启动相关的默认应用: # 启动默认文本编辑器打开 helloworld.txt Process.Star ...
- Fundebug支持浏览器报警
摘要: 除了邮件报警和第三方报警,我们新增了浏览器报警功能. 邮件报警与第三方报警 Fundebug是专业的应用BUG监控服务,当您的线上应用,比如网页.小程序.Java等发生BUG时,我们会第一时间 ...
- shell 查找与替换
grep sed 如果想把一个字符串中的一些字符删除可以如此:#Echo “2006-11-21 22:16:30” | sed ‘s/-//g’ | sed ‘s/ //g’ | sed ‘s/:/ ...
- MyBatis学习---整合SpringMVC
[目录]
- Android Studio教程02-应用程序结构图及应用基础
目录 1. Android应用程序开发技术结构图 2.Android的应用基础 2.1. Android的四大组件: 1. Android组件1: Activity 2. Android组件2: Se ...