贝叶斯深度学习(bayesian deep learning)
本文简单介绍什么是贝叶斯深度学习(bayesian deep learning),贝叶斯深度学习如何用来预测,贝叶斯深度学习和深度学习有什么区别。对于贝叶斯深度学习如何训练,本文只能大致给个介绍。(不敢误人子弟)
在介绍贝叶斯深度学习之前,先来回顾一下贝叶斯公式。
贝叶斯公式
\[p(z|x) = \frac{p(x, z)}{p(x)} = \frac{p(x|z)p(z)}{p(x)} \tag{1}\]
其中,\(p(z|x)\) 被称为后验概率(posterior),\(p(x, z)\) 被称为联合概率,\(p(x|z)\) 被称为似然(likelihood),\(p(z)\) 被称为先验概率(prior),\(p(x)\) 被称为 evidence。
如果再引入全概率公式 \(p(x) = \int p(x|z)p(z) dz\),式(1)可以再变成如下形式:
\[p(z|x) = \frac{p(x|z)p(z)}{\int p(x|z)p(z) dz} \tag{2}\]
如果 \(z\) 是离散型变量,则将式(2)中分母积分符号 \(\int\) 改成求和符号 \(\sum\) 即可。(概率分布中的概率质量函数一般用大写字母 \(P(\cdot)\) 表示,概率密度函数一般用小写字母 \(p(\cdot)\) 表示,这里为了简便,不多做区分,用连续型变量举例)
什么是贝叶斯深度学习?
一个最简单的神经元网络结构如下图所示:
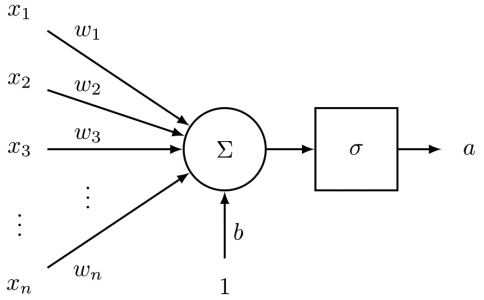
在深度学习中,\(w_i, (i = 1,...,n)\) 和 \(b\) 都是一个确定的值,例如 \(w_1 = 0.1, b = 0.2\)。即使我们通过梯度下降(gradient decent)更新 \(w_i = w_i - \alpha\cdot\frac{\partial J}{\partial w_i}\),我们仍未改变 “\(w_i\) 和 \(b\) 都是一个确定的值” 这一事实。
那什么是贝叶斯深度学习?将 \(w_i\) 和 \(b\) 由确定的值变成分布(distributions),这就是贝叶斯深度学习。
贝叶斯深度学习认为每一个权重(weight)和偏置(bias)都应该是一个分布,而不是一个确定的值。(这很贝叶斯。)如下图所示,给出一个直观的例子:
图 2 展示了一个结构为 4x3x1 的贝叶斯神经网络。(输入层神经元个数为 4,中间隐含层神经元个数为 3,输出层神经元个数为 1。)
贝叶斯深度学习如何进行预测?
说了这么多,贝叶斯神经网络该怎么用?网络的权重和偏置都是分布,分布咋用,采样呗。想要像非贝叶斯神经网络那样进行前向传播(feed-forward),我们可以对贝叶斯神经网络的权重和偏置进行采样,得到一组参数,然后像非贝叶斯神经网络那样用即可。
当然,我们可以对权重和偏置的分布进行多次采样,得到多个参数组合,参数的细微改变对模型结果的影响在这里就可以体现出来。这也是贝叶斯深度学习的优势之一,多次采样最后一起得到的结果更加 robust。
贝叶斯深度学习如何进行训练?
对于非贝叶斯神经网络,在各种超参数固定的情况下,我们训练一个神经网络想要的就是各个层之间的权重和偏置。对于贝叶斯深度学习,我们训练的目的就是得到权重和偏置的分布。这个时候就要用到贝叶斯公式了。
给定一个训练集 \(D= \{( \bm{x}_1, y_1), (\bm{x}_2, y_2),..., (\bm{x}_m, y_m)\}\),我们用 \(D\) 训练一个贝叶斯神经网络,则贝叶斯公式可以写为如下形式:
\[
p(w|\bm{x}, y) = \frac{p(y|\bm{x}, w)p(w)}{\int p(y|\bm{x}, w)p(w) dw}
\tag{3}
\]
式(3)中,我们想要得到的是 \(w\) 的后验概率 $p(w|\bm{x}, y) $,先验概率 \(p(w)\) 是我们可以根据经验也好瞎猜也好是知道的,例如初始时将 \(p(w)\) 设成标准正太分布,似然 \(p(y|\bm{x}, w)\) 是一个关于 \(w\) 的函数。当 \(w\) 等于某个值时,式(3)的分子很容易就能算出来,但我们想要得到后验概率 \(p(w|\bm{x}, y)\),按理还要将分母算出来。但事实是,分母这个积分要对 \(w\) 的取值空间上进行,我们知道神经网络的单个权重的取值空间可以是实数集 \(R\),而这些权重一起构成的空间将相当复杂,基本没法积分。所以问题就出现在分母上。
贝叶斯深度学习的训练方法目前有以下几种:(请参考Deep Bayesian Neural Networks. -- Stefano Cosentino)
(1)Approximating the integral with MCMC
(2)Using black-box variational inference (with Edward)
(3)Using MC (Monte Carlo) dropout
第(1)种情况最好理解,用 MCMC(Markov Chains Monte Carlo) 采样去近似分母的积分。第(2)种直接用一个简单点的分布 \(q\) 去近似后验概率的分布 \(p\),即不管分母怎么积分,直接最小化分布 \(q\) 和 \(p\) 之间的差异,如可以使用 KL散度 计算。详情可以参考贝叶斯编程框架 Edward 中的介绍。
贝叶斯深度学习和深度学习有什么区别?
通过之前的介绍,我们也可以发现,在深度学习的基础上把权重和偏置变为 distribution 就是贝叶斯深度学习。
贝叶斯深度学习还有以下优点:
(1)贝叶斯深度学习比非贝叶斯深度学习更加 robust。因为我们可以采样一次又一次,细微改变权重对深度学习造成的影响在贝叶斯深度学习中可以得到解决。
(2)贝叶斯深度学习可以提供不确定性(uncertainty),非 softmax 生成的概率。详情参见 Deep Learning Is Not Good Enough, We Need Bayesian Deep Learning for Safe AI。
贝叶斯神经网络(Bayesian neural network)和贝叶斯网络(Bayesian network)?
请不要混淆贝叶斯神经网络和贝叶斯网络这两者的概念。
“贝叶斯网络(Bayesian network),又称信念网络(belief network)或是有向无环图模型(directed acyclic graphical model),是一种概率图型模型。”
而贝叶斯神经网络(Bayesian neural network)是贝叶斯和神经网络的结合,贝叶斯神经网络和贝叶斯深度学习这两个概念可以混着用。
References
Eric J. Ma - An Attempt At Demystifying Bayesian Deep Learning
Deep Bayesian Neural Networks. -- Stefano Cosentino
Edward -- A library for probabilistic modeling, inference, and criticism.
Deep Learning Is Not Good Enough, We Need Bayesian Deep Learning for Safe AI
贝叶斯网络 -- 百度百科
贝叶斯深度学习(bayesian deep learning)的更多相关文章
- 深度学习(Deep Learning)资料大全(不断更新)
Deep Learning(深度学习)学习笔记(不断更新): Deep Learning(深度学习)学习笔记之系列(一) 深度学习(Deep Learning)资料(不断更新):新增数据集,微信公众号 ...
- 学习笔记之深度学习(Deep Learning)
深度学习 - 维基百科,自由的百科全书 https://zh.wikipedia.org/wiki/%E6%B7%B1%E5%BA%A6%E5%AD%A6%E4%B9%A0 深度学习(deep lea ...
- 读李宏毅《一天看懂深度学习》——Deep Learning Tutorial
大牛推荐的入门用深度学习导论,刚拿到有点懵,第一次接触PPT类型的学习资料,但是耐心看下来收获还是很大的,适合我这种小白入门哈哈. 原PPT链接:http://www.slideshare.net/t ...
- 深度学习(deep learning)
最近deep learning大火,不仅仅受到学术界的关注,更在工业界受到大家的追捧.在很多重要的评测中,DL都取得了state of the art的效果.尤其是在语音识别方面,DL使得错误率下降了 ...
- 如何正确理解深度学习(Deep Learning)的概念
现在深度学习在机器学习领域是一个很热的概念,不过经过各种媒体的转载播报,这个概念也逐渐变得有些神话的感觉:例如,人们可能认为,深度学习是一种能够模拟出人脑的神经结构的机器学习方式,从而能够让计算机具有 ...
- 深度学习研究组Deep Learning Research Groups
Deep Learning Research Groups Some labs and research groups that are actively working on deep learni ...
- 深度学习数据集Deep Learning Datasets
Datasets These datasets can be used for benchmarking deep learning algorithms: Symbolic Music Datase ...
- 深度学习教程Deep Learning Tutorials
Deep Learning Tutorials Deep Learning is a new area of Machine Learning research, which has been int ...
- Caffe——清晰高效的深度学习(Deep Learning)框架
Caffe(http://caffe.berkeleyvision.org/)是一个清晰而高效的深度学习框架,其作者是博士毕业于UC Berkeley的贾扬清(http://daggerfs.com/ ...
随机推荐
- 实例解析Collections源码,Iterator和ListIterator
比如一个视频或文章有多个页面标签设置,我们在看一篇文章或一个视频时,底部有为你推荐栏目. 如何根据这个文章或视频的标签,来实现这个推荐栏目呢. public List<VideoInfoVo&g ...
- 学习Timer定时器
原文地址:http://www.cppblog.com/ivenher/articles/19969.html setTimer函数用于创建一个计时器,KillTimer函数用于销毁一个计时器.计时器 ...
- erlang的脚本执行---escript
1.概述: 作为程序员对于脚本语言应该很熟悉了,脚本语言的优点很多,如快速开发.容易编写.实时开发和执行, 我们常用的脚本有Javascript.shell.python等,我们的erlang语言也有 ...
- ZeroMQ 教程 002 : 高级技巧
本文主要译自 zguide - chapter two. 但并不是照本翻译. 上一章我们简单的介绍了一个ZMQ, 并给出了三个套路的例子: 请求-回应, 订阅-发布, 流水线(分治). 这一章, 我们 ...
- 落入绝地求生的Python神仙,实现绝地求生无后座!
叙述 绝地求生已经出来那么久了,大家应该都晓得如今的游戏情形很是差 .特别在高端局,神仙满天飞 搞得很多人类玩家很是没有游戏体验! 由于绝地求生的火爆,繁衍出许多外挂流传于各个地方.飞机上.网吧内,各 ...
- PCB布线要求
时钟线要求 时钟驱动器布局在PCB中心而非电路板外围,布局尽量靠近,走线圆滑.短,非直角.非T形,布线可选4~8mil,过窄会导致高频信号衰减,并降低信号之间电容性耦合. 避免时钟之间.与信号之间的干 ...
- JavaScript 之函数
刚开 始学习 JS 时,挺不习惯它函数的用法,就比如一个 function 里面会嵌套一个 function,对于函数里创建变量的作用域也感到很迷惑,这个的语法和 JAVA 相差太多,为此,阅读了&l ...
- Python_将指定文件夹中的文件压缩至已有压缩包
from zipfile import ZipFile from os import listdir from os.path import isfile,isdir,join def addFile ...
- 用ECMAScript4 ( ActionScript3) 实现Unity的热更新 -- 使用FairyGUI (二)
上次讲解了FairyGUI的最简单的热更新办法,并对其中一个Demo进行了修改并做成了热更新的方式. 这次我们来一个更加复杂一些的情况:Emoji. FairyGUI的 Example 04 - ...
- es6属性基础教学,30分钟包会
ES6基础智商划重点在实际开发中,ES6已经非常普及了.掌握ES6的知识变成了一种必须.尽管我们在使用时仍然需要经过babel编译.ES6彻底改变了前端的编码风格,可以说对于前端的影响非常巨大.值得高 ...