[数据分析工具] Pandas 功能介绍(一)
- 如果你在使用 Pandas(Python Data Analysis Library) 的话,下面介绍的对你一定会有帮助的。
- DataFrame:行列数据,类似 Excel 的 sheet,或关系型数据库的表
- series:单列数据
- axis:0:行,1:列
- shape:DataFrame的行列数,(行数,列数)
1. 加载 CSV
- 直接加载
- 无参数加载
- 无参数加载

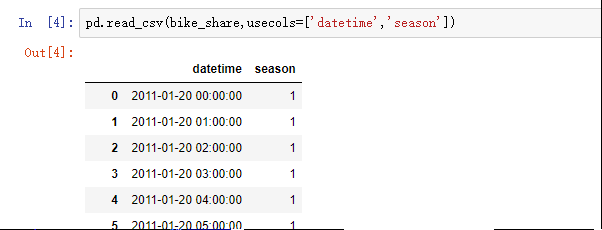
- 选择特定列加载

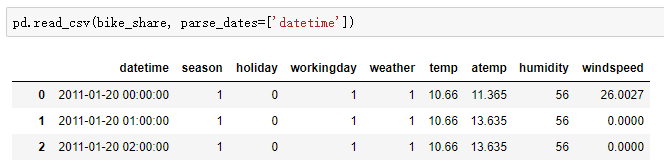
- 时间转换加载

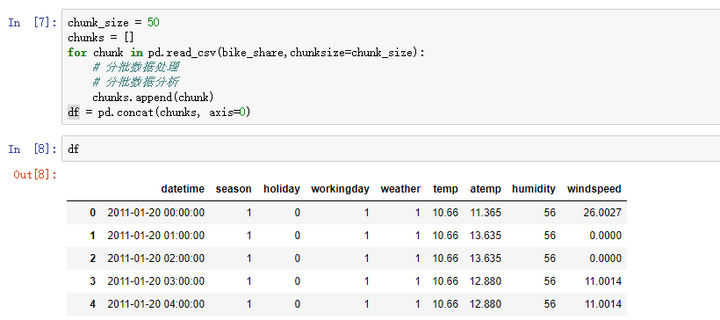
- 分批加载

2. 浏览 DataFrame 数据
- df.head(n):浏览数据的前 n 行,默认 5 行
- df.tail(n):浏览数据的末尾 n 行,默认 5 行
- df.sample(n):随机浏览 n 行数据,默认 5 行
- df.shape:tuple 类型的数据行列数,(行数,列数)
- df.describe():计算评估数据的趋势
- df.info():内存和数据类型
3. 在 DataFrame 中增加列
- 简单方式
df['new_column'] = 1
- 计算方式
- 条件方式

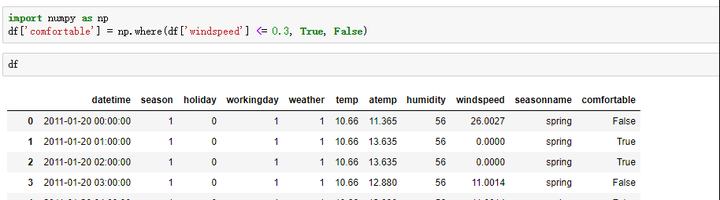
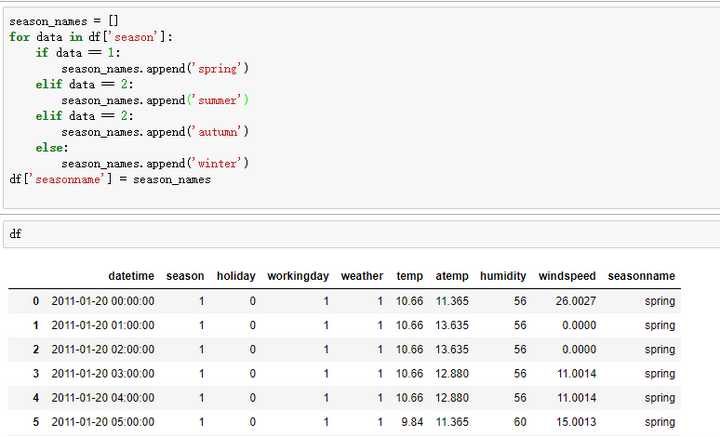
- 循环方式

4. 选择指定单元格
- loc 根据标签选取loc
- iloc 根据索引选取
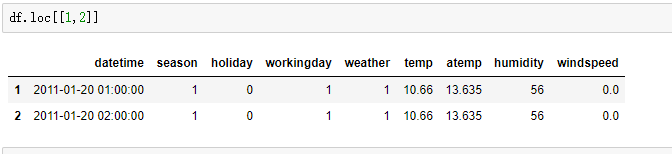
- 选取行数据
- df.loc[[行索引数组]],df.iloc[[行索引数组]]

- 索引开始位置:闭区间
- 索引结束位置:开区间
- loc 和 iloc 选取整列数据的时候,看上去与 df[列名数组] 的方式一致,但是其实前者返回的仍然是 DataFrame,后者返回的是 Series


[数据分析工具] Pandas 功能介绍(一)的更多相关文章
- [数据分析工具] Pandas 功能介绍(二)
条件过滤 我们需要看第一季度的数据是怎样的,就需要使用条件过滤 体感的舒适适湿度是40-70,我们试着过滤出体感舒适湿度的数据 最后整合上面两种条件,在一季度体感湿度比较舒适的数据 列排序 数据按照某 ...
- pt-query-digest工具的功能介绍了:
Ok,可以查看 pt-query-digest工具的功能介绍了: [root@472322 percona-toolkit-2.2.5]# pt-query-digest --help pt-quer ...
- 数据分析工具Pandas
参考学习资料:http://pandas.pydata.org 1.什么是Pandas? Pandas的名称来自于面板数据(panel data)和Python数据分析(data analys ...
- 数据分析工具pandas简介
什么是Pandas? Pandas的名称来自于面板数据(panel data)和Python数据分析(data analysis). Pandas是一个强大的分析结构化数据的工具集,基于NumPy构建 ...
- python数据分析工具 | pandas
pandas是python下强大的数据分析和探索工具,是的python在处理数据时非常快速.简单.它是构建在numpy之上的,包含丰富的数据处理函数,支持时间序列分析功能,支持灵活处理缺失数据. pa ...
- python数据分析工具——Pandas、StatsModels、Scikit-Learn
Pandas Pandas是 Python下最强大的数据分析和探索工具.它包含高级的数据结构和精巧的工具,使得在 Python中处理数据非常快速和简单. Pandas构建在 Numpy之上,它使得以 ...
- 浏览器开发者工具----F12 功能介绍
笔者技巧: 看了些其它回答,有些是用来扒图片的,有些是写爬虫的(这个不要看Elements,因为浏览器会对一些不符合规范的标签做补全或者其它处理,最好是Ctrl+U). 图片的话就不要看Network ...
- 用python做数据分析4|pandas库介绍之DataFrame基本操作
原文地址 怎样删除list中空字符? 最简单的方法:new_list = [ x for x in li if x != '' ] 今天是5.1号. 这一部分主要学习pandas中基于前面两种数据结构 ...
- 机器学习(4):数据分析的工具-pandas的使用
前面几节说一些沉闷的概念,你若看了估计已经心生厌倦,我也是.所以,找到了一个理由来说一个有兴趣的话题,就是数据分析.是什么理由呢?就是,机器学习的处理过程中,数据分析是经常出现的操作.就算机器对大量样 ...
随机推荐
- ArcGIS API for JavaScript 4.2学习笔记[19] 搜索小部件——使用更多数据源
上一篇中提到,空间搜索小部件是Search这个类的实例化,作为视图的ui属性添加进去后,视图就会出现搜索框了. 这节的主体代码和上篇几乎一致,区别就在上篇提及的sources属性. 先看看结果: 由于 ...
- Jmeter中java.net.URISyntaxException错误
今天在做服务发布性能测试的时候,傻傻的犯了个错,没有对参数进行仔细的检查,直接从fiddler中copy到jmeter中了,业务流程配置好后执行测试报错... jmeter中的响应结果如下: java ...
- [编织消息框架][netty源码分析]9 Promise 实现类DefaultPromise职责与实现
netty Future是基于jdk Future扩展,以监听完成任务触发执行Promise是对Future修改任务数据DefaultPromise是重要的模板类,其它不同类型实现基本是一层简单的包装 ...
- 【读书笔记】A Swift Tour
素材:A Swift Tour 推荐下载Playground:Download Playground objc 自己较为熟悉,想熟悉下风头正劲的 swift.就先从官方的入门手册开始撸. 每一小节,我 ...
- 房上的猫:经典排序算法 - 冒泡排序Bubble sort
原理是临近的数字两两进行比较,按照从小到大或者从大到小的顺序进行交换,这样一趟过去后,最大或最小的数字被交换到了最后一位,然后再从头开始进行两两比较交换,直到倒数第二位时结束,以此类推例子为从小到大排 ...
- Windows上Python2与Python3共存
首先安装好python2与python3版本 因为安装顺序的不同,所以系统默认的版本也不同.如果先安装的是python,那么系统默认的就是python2 如果根据需求需要使用不同的版本,可以使用py命 ...
- webpack之loader实践
初识前端模板概念的开发者,通常都使用过underscore的template方法,非常简单好用,支持赋值,条件判断,循环等,基本可以满足我们的需求. 在使用Webpack搭建开发环境的时候,如果要使用 ...
- 代码审计之XiaoCms(后台任意文件上传至getshell,任意目录删除,会话固定漏洞)
0x00 前言 这段时间就一直在搞代码审计了.针对自己的审计方法做一下总结,记录一下步骤. 审计没他,基础要牢,思路要清晰,姿势要多且正. 下面是自己审计的步骤,正在逐步调整,寻求效率最高. 0x01 ...
- ASP.NET MVC 解决区域和全局控制器同名的问题
话不多少 直接上代码 通常我们以为上边的是解决控制同名问题,是解决了一点,但是又出了以下问题,默认请求的不是项目默认的控制器而是该区域的控制器,在我之前开发的项目中,默认指向的是区域下的home控制器 ...
- 【转】Tableau 9.3.8 desktop for Mac 中文破解
tableau破解版本下载地址 安装步骤: 1. 编辑hosts 文件 在终端输入:sudo nano /etc/hosts 添加如下内容: 127.0.0.1 licensing.tableauso ...