HDU4920-Matrix multiplication-矩阵乘法 51nod-1137 矩阵乘法
Matrix multiplication
Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/Others)
Total Submission(s): 5236 Accepted Submission(s): 2009
bobo hates big integers. So you are only asked to find the result modulo 3.
The first line contains n (1≤n≤800). Each of the following n lines contain n integers -- the description of the matrix A. The j-th integer in the i-th line equals Aij. The next n lines describe the matrix B in similar format (0≤Aij,Bij≤109).
Print n lines. Each of them contain n integers -- the matrix A×B in similar format.
#include<iostream>
#include<cstdio>
#include<algorithm>
#include<cstring>
#include<cstdlib>
#include<string.h>
#include<set>
#include<vector>
#include<queue>
#include<stack>
#include<map>
#include<cmath>
using namespace std; int a[][],b[][],c[][]; int main(){
int n;
while(~scanf("%d",&n)){
for(int i=;i<n;i++)
for(int j=;j<n;j++){
scanf("%d",&a[i][j]);
a[i][j]%=;
c[i][j]=;
}
for(int i=;i<n;i++)
for(int j=;j<n;j++){
scanf("%d",&b[i][j]);
b[i][j]%=;
}
for(int i=;i<n;i++)
for(int j=;j<n;j++){
if(!a[i][j])continue;//判断优化
for(int k=;k<n;k++)
c[i][k]=c[i][k]+a[i][j]*b[j][k];
}
for(int i=;i<n;i++){
for(int j=;j<n;j++)
if(j==n-)printf("%d\n",c[i][j]%);
else printf("%d ",c[i][j]%);
}
}
return ;
}
看其他题解
这个题有两种解法,一种是先对矩阵进行%3,
然后在3次方循环里判断如果元素如果是0,则continue不进行乘积的累加的结果。能起到优化的作用。
还有一种就是对矩阵进行某一个进行转置后,再进行两个矩阵的乘积累加。也能起到优化。
代码:
#include<iostream>
#include<cstring>
#include<cmath>
#include<cstdio>
#include<algorithm>
using namespace std;
int a[][],b[][],c[][]; int main(){
int n;
while(~scanf("%d",&n)){
for(int i=;i<n;i++)
for(int j=;j<n;j++){
scanf("%d",&a[i][j]);
a[i][j]%=;
c[i][j]=;
}
for(int i=;i<n;i++)
for(int j=;j<n;j++){
scanf("%d",&b[i][j]);
b[i][j]%=;
}
for(int i=;i<n;i++)
for(int j=;j<n;j++)
swap(b[i][j],b[j][i]);//转置优化
for(int i=;i<n;i++)
for(int j=;j<n;j++){
//if(!a[i][j])continue;
for(int k=;k<n;k++)
c[i][k]=c[i][k]+a[i][j]*b[j][k];
}
for(int i=;i<n;i++){
for(int j=;j<n;j++)
if(j==n-)printf("%d\n",c[i][j]%);
else printf("%d ",c[i][j]%);
}
}
return ;
}
用转置的话,也可以继续用3次方循环里判断元素是否为0,continue来优化。
直接判断的优化,时间跑1279MS,用转置不用判断是1653MS,用转置也用判断是1482MS,emnnnn。。。
for(int i=;i<n;i++)
for(int j=;j<n;j++){
for(int k=;k<n;k++)
c[i][k]=c[i][k]+a[i][j]*b[j][k];
}
如果是按这种循环写,不管有没有在3次方循环里判断元素是否为0,或者不管有没有转置,都不会超时!!!
然后就是还发现了一个问题,如果三层循环里面写的是c[i][j]的循环会超时的。
for(int i=;i<n;i++)
for(int j=;j<n;j++){
for(int k=;k<n;k++)
c[i][j]=c[i][j]+a[i][k]*b[k][j];
}
这个题简直有毒啊。
不管是直接判断优化还是转置优化,还是转置+判断优化,都是超时。
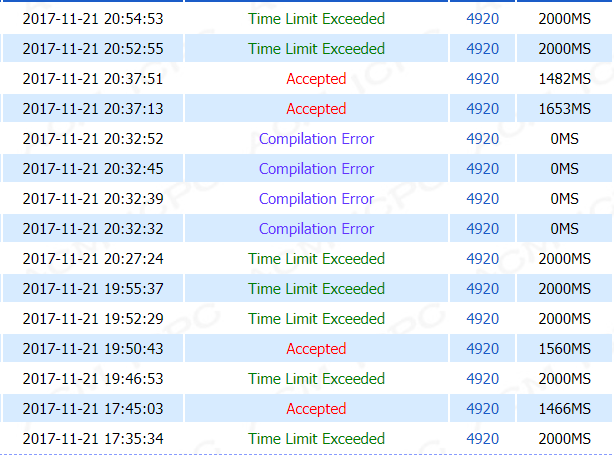
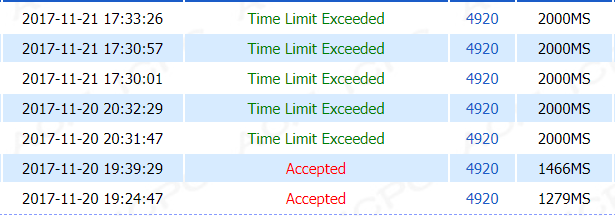
在经过这么多次智障操作之后(之后又交了一发,一共23次),并且在记录了循环的次数之后!!!
我发现。。。
int num=;
for(int i=;i<n;i++)
for(int j=;j<n;j++){
//if(!a[i][j])continue;
for(int k=;k<n;k++){
c[i][k]=c[i][k]+a[i][j]*b[j][k];
num++;
}
}
在都不经过优化的情况下,num的次数都是一样的,两个循环的次数都是一样的。
为什么一个可以过,一个就超时呢???(所有的都测过了_(:з」∠)_ )
未解之谜啊啊啊啊啊啊啊啊啊啊啊啊啊啊_(:з」∠)_
玩不了玩不了。。。
由于C与C++的二维数组是以行为主序存储的。
因此矩阵a的行数据元素是连续存储的,而矩阵b的列数据元素是不连续存储的(N*1的矩阵除外),
为了在矩阵相乘时对矩阵b也连续读取数据,根据局部性原理对矩阵b进行转置。
然而并没有什么用,在不转置的情况下,c[i][k]的是两个按行的,c[i][j]是一个按行的。c[i][k]比c[i][j]快我可以理解。但是!!!
转置之后,c[i][k]是两个按列的,c[i][j]是一个按行的,按道理应该是c[i][j]的快啊,但是为什么还是c[i][k]]快啊。
啊啊啊啊啊啊啊,玩不了玩不了。
HDU4920-Matrix multiplication-矩阵乘法 51nod-1137 矩阵乘法的更多相关文章
- hdu4920 Matrix multiplication 模3矩阵乘法
hdu4920 Matrix multiplication Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131072/131072 ...
- 51nod 1137.矩阵乘法-矩阵乘法
1137 矩阵乘法 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 给出2个N * N的矩阵M1和M2,输出2个矩阵相乘后的结果. Input 第1行:1个数N, ...
- 51nod 1137 矩阵乘法【矩阵】
1137 矩阵乘法 基准时间限制:1 秒 空间限制:131072 KB 分值: 0 难度:基础题 收藏 关注 给出2个N * N的矩阵M1和M2,输出2个矩阵相乘后的结果. Input 第1行 ...
- HDU-4920 Matrix multiplication
矩阵相乘,采用一行的去访问,比采用一列访问时间更短,根据数组是一行去储存的.神奇小代码. Matrix multiplication Time Limit: 4000/2000 MS (Java/Ot ...
- 51nod 1137 矩阵乘法
基本的矩阵乘法 中间for(int j=0;i<n;i++) //这里写错了 应该是j<n 晚上果然 效率不行 等会早点儿睡 //矩阵乘法 就是 两个矩阵 第一个矩阵的列 等与 第 ...
- HDU4920 Matrix multiplication 矩阵
不要问窝 为什么过了> < 窝也不造为什么就过了 说是%3变成稀疏矩阵 可是随便YY个案例都会超时.. . 看来数据是随机的诶 #include <stdio.h> #incl ...
- 【bitset】hdu4920 Matrix multiplication
先把两个矩阵全都mod3. S[i][j][k]表示第i(0/1)个矩阵的行/列的第k位是不是j(1/2). 然后如果某两个矩乘对应位上为1.1,乘出来是1: 1.2:2: 2.1:2: 2.2:1. ...
- 矩阵乘法 --- hdu 4920 : Matrix multiplication
Matrix multiplication Time Limit: 4000/2000 MS (Java/Others) Memory Limit: 131072/131072 K (Java/ ...
- hdu 4920 Matrix multiplication(矩阵乘法)2014多培训学校5现场
Matrix multiplication Time ...
- 数学(矩阵乘法,随机化算法):POJ 3318 Matrix Multiplication
Matrix Multiplication Time Limit: 2000MS Memory Limit: 65536K Total Submissions: 17783 Accepted: ...
随机推荐
- 2018年的UX设计师薪酬预测,你能拿多少?
以下内容由Mockplus团队翻译整理,仅供学习交流,Mockplus是更快更简单的原型设计工具. 一个经验丰富的设计师完全可以根据地区和专业来可以预期薪酬之间的差距,其中悬殊最高可达80K. 本 ...
- bzoj 4824: [Cqoi2017]老C的键盘
Description 老 C 是个程序员. 作为一个优秀的程序员,老 C 拥有一个别具一格的键盘,据说这样可以大幅提升写程序的速度,还能让写出来的程序 在某种神奇力量的驱使之下跑得非常快.小 ...
- 7.18 DP考试解题报告
今天的考试真的是天崩地裂,写了的三个题全炸...然而谁叫我弱+不注意细节呢???真的要扇耳光... T1:题意:一段区间的高度为这个区间中高度的最小值,给定n个宽度,求每个宽度的期望高度 40% :算 ...
- HDFS租约实践
一.租约详解 Why租约 HDFS的读写模式为 "write-once-read-many",为了实现write-once,需要设计一种互斥机制,租约应运而生租约本质上是一个有时间 ...
- window下mysql数据备份
今天我有个朋友让我帮他在windowServer服务器上备份一下mysql的数据库,于是花了一天的时间完成了一个每天定时备份数据库的功能,小编在这里为大家记录一下: 首先对于mysql命令行的导入导出 ...
- IDEA 环境设置
IDEA环境设置 任何事物都有两面性,如何用好才是关键.IDEA为我们提供了丰富的功能,但不代表默认的配置就适合于你.我们应当根据自己的条件.需求合理的配置,从而驾驭好这匹悍马.让它成为我们编程的利器 ...
- 如何去除本地文件与svn服务器的关联
1.每个目录逐个去删除.svn文件夹 .svn属于隐藏文件夹,可通过操纵Windows文件资源管理器使隐藏文件可视,删除该文件,即可. 2.首先建立一个新文件,文件命名为remove-svn-fold ...
- Linux的编码及编码转换
如果你需要在Linux中操作windows下的文件,那么你可能会经常遇到文件编码转换的问题.Windows中默认的文件格式是GBK(gb2312),而Linux一般都是UTF-8.下面介绍一下,在Li ...
- python Is 与== 的坑
以前看过一篇python技术贴,说用is替代==,这样更加pythonic?然后我就能把用'=='的地方用'Is'替代,结果程序运行结果的偏差很大,甚至完全不同.后来发现,Is与==使用上是有区别的. ...
- 《UNP》学习之TCP状态转换
CLOSED:TCP起始状态 LISTEN:绑定端口后进入listen状态,一般是服务端 SYN_SENT:发送SYN连接请求,主动打开连接的一方进入SYN_SENT SYN_RCVD:接收到SYN连 ...