文本主题模型之LDA(二) LDA求解之Gibbs采样算法
文本主题模型之LDA(二) LDA求解之Gibbs采样算法
文本主题模型之LDA(三) LDA求解之变分推断EM算法(TODO)
本文是LDA主题模型的第二篇,读这一篇之前建议先读文本主题模型之LDA(一) LDA基础,同时由于使用了基于MCMC的Gibbs采样算法,如果你对MCMC和Gibbs采样不熟悉,建议阅读之前写的MCMC系列MCMC(四)Gibbs采样。
1. Gibbs采样算法求解LDA的思路
首先,回顾LDA的模型图如下:
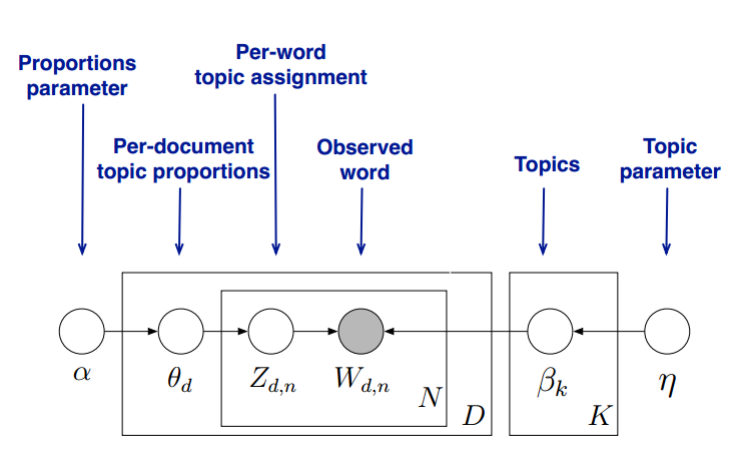
在Gibbs采样算法求解LDA的方法中,我们的$\alpha, \eta$是已知的先验输入,我们的目标是得到各个$z_{dn}, w_{kn}$对应的整体$\vec z,\vec w$的概率分布,即文档主题的分布和主题词的分布。由于我们是采用Gibbs采样法,则对于要求的目标分布,我们需要得到对应分布各个特征维度的条件概率分布。
具体到我们的问题,我们的所有文档联合起来形成的词向量$\vec w$是已知的数据,不知道的是语料库主题$\vec z$的分布。假如我们可以先求出$w,z$的联合分布$p(\vec w,\vec z)$,进而可以求出某一个词$w_i$对应主题特征$z_i$的条件概率分布$p(z_i=k| \vec w,\vec z_{\neg i})$。其中,$\vec z_{\neg i}$代表去掉下标为$i$的词后的主题分布。有了条件概率分布$p(z_i=k| \vec w,\vec z_{\neg i})$,我们就可以进行Gibbs采样,最终在Gibbs采样收敛后得到第$i$个词的主题。
如果我们通过采样得到了所有词的主题,那么通过统计所有词的主题计数,就可以得到各个主题的词分布。接着统计各个文档对应词的主题计数,就可以得到各个文档的主题分布。
以上就是Gibbs采样算法求解LDA的思路。
2. 主题和词的联合分布与条件分布的求解
从上一节可以发现,要使用Gibbs采样求解LDA,关键是得到条件概率$p(z_i=k| \vec w,\vec z_{\neg i})$的表达式。那么这一节我们的目标就是求出这个表达式供Gibbs采样使用。
首先我们简化下Dirichlet分布的表达式,其中$\triangle(\alpha)$是归一化参数:$$Dirichlet(\vec p| \vec \alpha) = \frac{\Gamma(\sum\limits_{k=1}^K\alpha_k)}{\prod_{k=1}^K\Gamma(\alpha_k)}\prod_{k=1}^Kp_k^{\alpha_k-1} = \frac{1}{\triangle( \vec \alpha)}\prod_{k=1}^Kp_k^{\alpha_k-1}$$
现在我们先计算下第d个文档的主题的条件分布$p(\vec z_d|\alpha)$,在上一篇中我们讲到$\alpha \to \theta_d \to \vec z_d$组成了Dirichlet-multi共轭,利用这组分布,计算$p(\vec z_d| \vec \alpha)$如下:$$ \begin{align} p(\vec z_d| \vec \alpha) & = \int p(\vec z_d | \vec \theta_d) p(\theta_d | \vec \alpha) d \vec \theta_d \\ & = \int \prod_{k=1}^Kp_k^{n_d^{(k)}} Dirichlet(\vec \alpha) d \vec \theta_d \\ & = \int \prod_{k=1}^Kp_k^{n_d^{(k)}} \frac{1}{\triangle( \vec \alpha)}\prod_{k=1}^Kp_k^{\alpha_k-1}d \vec \theta_d \\ & = \frac{1}{\triangle( \vec \alpha)} \int \prod_{k=1}^Kp_k^{n_d^{(k)} + \alpha_k-1}d \vec \theta_d \\ & = \frac{\triangle(\vec n_d + \vec \alpha)}{\triangle( \vec \alpha)} \end{align}$$
其中,在第d个文档中,第k个主题的词的个数表示为:$n_d^{(k)}$, 对应的多项分布的计数可以表示为 $$\vec n_d = (n_d^{(1)}, n_d^{(2)},...n_d^{(K)})$$
有了单一一个文档的主题条件分布,则可以得到所有文档的主题条件分布为:$$p(\vec z|\vec \alpha) = \prod_{d=1}^Mp(\vec z_d|\vec \alpha) = \prod_{d=1}^M \frac{\triangle(\vec n_d + \vec \alpha)}{\triangle( \vec \alpha)} $$
同样的方法,可以得到,第k个主题对应的词的条件分布$p(\vec w|\vec z, \vec \eta)$为:$$p(\vec w|\vec z, \vec \eta) =\prod_{k=1}^Kp(\vec w_k|\vec z, \vec \eta) =\prod_{k=1}^K \frac{\triangle(\vec n_k + \vec \eta)}{\triangle( \vec \eta)}$$
其中,第k个主题中,第v个词的个数表示为:$n_k^{(v)}$, 对应的多项分布的计数可以表示为 $$\vec n_k = (n_k^{(1)}, n_k^{(2)},...n_k^{(V)})$$
最终我们得到主题和词的联合分布$p(\vec w, \vec z| \vec \alpha, \vec \eta)$如下:$$p(\vec w, \vec z) = p(\vec w, \vec z| \vec \alpha, \vec \eta) = p(\vec z|\vec \alpha) p(\vec w|\vec z, \vec \eta) = \prod_{d=1}^M \frac{\triangle(\vec n_d + \vec \alpha)}{\triangle( \vec \alpha)}\prod_{k=1}^K \frac{\triangle(\vec n_k + \vec \eta)}{\triangle( \vec \eta)} $$
有了联合分布,现在我们就可以求Gibbs采样需要的条件分布$p(z_i=k| \vec w,\vec z_{\neg i})$了。需要注意的是这里的i是一个二维下标,对应第d篇文档的第n个词。
对于下标$i$,由于它对应的词$w_i$是可以观察到的,因此我们有:$$p(z_i=k| \vec w,\vec z_{\neg i}) \propto p(z_i=k, w_i =t| \vec w_{\neg i},\vec z_{\neg i})$$
对于$z_i=k, w_i =t$,它只涉及到第d篇文档和第k个主题两个Dirichlet-multi共轭,即:$$\vec \alpha \to \vec \theta_d \to \vec z_d $$$$\vec \eta \to \vec \beta_k \to \vec w_{(k)}$$
其余的$M+K-2$个Dirichlet-multi共轭和它们这两个共轭是独立的。如果我们在语料库中去掉$z_i,w_i$,并不会改变之前的$M+K$个Dirichlet-multi共轭结构,只是向量的某些位置的计数会减少,因此对于$\vec \theta_d, \vec \beta_k$,对应的后验分布为:$$p(\vec \theta_d | \vec w_{\neg i},\vec z_{\neg i}) = Dirichlet(\vec \theta_d | \vec n_{d, \neg i} + \vec \alpha) $$$$p(\vec \beta_k | \vec w_{\neg i},\vec z_{\neg i}) = Dirichlet(\vec \beta_k | \vec n_{k, \neg i} + \vec \eta) $$
现在开始计算Gibbs采样需要的条件概率:$$ \begin{align} p(z_i=k| \vec w,\vec z_{\neg i}) & \propto p(z_i=k, w_i =t| \vec w_{\neg i},\vec z_{\neg i}) \\ & = \int p(z_i=k, w_i =t, \vec \theta_d , \vec \beta_k| \vec w_{\neg i},\vec z_{\neg i}) d\vec \theta_d d\vec \beta_k \\ & = \int p(z_i=k, \vec \theta_d | \vec w_{\neg i},\vec z_{\neg i})p(w_i=t, \vec \beta_k | \vec w_{\neg i},\vec z_{\neg i}) d\vec \theta_d d\vec \beta_k \\ & = \int p(z_i=k|\vec \theta_d )p( \vec \theta_d | \vec w_{\neg i},\vec z_{\neg i})p(w_i=t|\vec \beta_k)p(\vec \beta_k | \vec w_{\neg i},\vec z_{\neg i}) d\vec \theta_d d\vec \beta_k \\ & = \int p(z_i=k|\vec \theta_d ) Dirichlet(\vec \theta_d | \vec n_{d, \neg i} + \vec \alpha) d\vec \theta_d \\ & * \int p(w_i=t|\vec \beta_k) Dirichlet(\vec \beta_k | \vec n_{k, \neg i} + \vec \eta) d\vec \beta_k \\ & = \int \theta_{dk} Dirichlet(\vec \theta_d | \vec n_{d, \neg i} + \vec \alpha) d\vec \theta_d \int \beta_{kt} Dirichlet(\vec \beta_k | \vec n_{k, \neg i} + \vec \eta) d\vec \beta_k \\ & = E_{Dirichlet(\theta_d)}(\theta_{dk})E_{Dirichlet(\beta_k)}(\beta_{kt})\end{align}$$
在上一篇LDA基础里我们讲到了Dirichlet分布的期望公式,因此我们有:$$E_{Dirichlet(\theta_d)}(\theta_{dk}) = \frac{n_{d, \neg i}^{k} + \alpha_k}{\sum\limits_{s=1}^Kn_{d, \neg i}^{s} + \alpha_s}$$$$E_{Dirichlet(\beta_k)}(\beta_{kt})= \frac{n_{k, \neg i}^{t} + \eta_t}{\sum\limits_{f=1}^Vn_{k, \neg i}^{f} + \eta_f}$$
最终我们得到每个词对应主题的Gibbs采样的条件概率公式为:$$p(z_i=k| \vec w,\vec z_{\neg i}) = \frac{n_{d, \neg i}^{k} + \alpha_k}{\sum\limits_{s=1}^Kn_{d, \neg i}^{s} + \alpha_s} \frac{n_{k, \neg i}^{t} + \eta_t}{\sum\limits_{f=1}^Vn_{k, \neg i}^{f} + \eta_f}$$
有了这个公式,我们就可以用Gibbs采样去采样所有词的主题,当Gibbs采样收敛后,即得到所有词的采样主题。
利用所有采样得到的词和主题的对应关系,我们就可以得到每个文档词主题的分布$\theta_d$和每个主题中所有词的分布$\beta_k$。
3. LDA Gibbs采样算法流程总结
现在我们总结下LDA Gibbs采样算法流程。首先是训练流程:
1) 选择合适的主题数$K$, 选择合适的超参数向量$\vec \alpha,\vec \eta$
2) 对应语料库中每一篇文档的每一个词,随机的赋予一个主题编号$z$
3) 重新扫描语料库,对于每一个词,利用Gibbs采样公式更新它的topic编号,并更新语料库中该词的编号。
4) 重复第2步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛。
5) 统计语料库中的各个文档各个词的主题,得到文档主题分布$\theta_d$,统计语料库中各个主题词的分布,得到LDA的主题与词的分布$\beta_k$。
下面我们再来看看当新文档出现时,如何统计该文档的主题。此时我们的模型已定,也就是LDA的各个主题的词分布$\beta_k$已经确定,我们需要得到的是该文档的主题分布。因此在Gibbs采样时,我们的$E_{Dirichlet(\beta_k)}(\beta_{kt})$已经固定,只需要对前半部分$E_{Dirichlet(\theta_d)}(\theta_{dk})$进行采样计算即可。
现在我们总结下LDA Gibbs采样算法的预测流程:
1) 对应当前文档的每一个词,随机的赋予一个主题编号$z$
2) 重新扫描当前文档,对于每一个词,利用Gibbs采样公式更新它的topic编号。
3) 重复第2步的基于坐标轴轮换的Gibbs采样,直到Gibbs采样收敛。
4) 统计文档中各个词的主题,得到该文档主题分布。
4. LDA Gibbs采样算法小结
使用Gibbs采样算法训练LDA模型,我们需要先确定三个超参数$K, \vec \alpha,\vec \eta$。其中选择一个合适的$K$尤其关键,这个值一般和我们解决问题的目的有关。如果只是简单的语义区分,则较小的$K$即可,如果是复杂的语义区分,则$K$需要较大,而且还需要足够的语料。
由于Gibbs采样可以很容易的并行化,因此也可以很方便的使用大数据平台来分布式的训练海量文档的LDA模型。以上就是LDA Gibbs采样算法。
后面我们会介绍用变分推断EM算法来求解LDA主题模型,这个方法是scikit-learn和spark MLlib都使用的LDA求解方法。
(欢迎转载,转载请注明出处。欢迎沟通交流: pinard.liu@ericsson.com)
文本主题模型之LDA(二) LDA求解之Gibbs采样算法的更多相关文章
- 文本主题模型之LDA(三) LDA求解之变分推断EM算法
文本主题模型之LDA(一) LDA基础 文本主题模型之LDA(二) LDA求解之Gibbs采样算法 文本主题模型之LDA(三) LDA求解之变分推断EM算法 本文是LDA主题模型的第三篇,读这一篇之前 ...
- 文本主题模型之LDA(一) LDA基础
文本主题模型之LDA(一) LDA基础 文本主题模型之LDA(二) LDA求解之Gibbs采样算法 文本主题模型之LDA(三) LDA求解之变分推断EM算法(TODO) 在前面我们讲到了基于矩阵分解的 ...
- 文本主题模型之非负矩阵分解(NMF)
在文本主题模型之潜在语义索引(LSI)中,我们讲到LSI主题模型使用了奇异值分解,面临着高维度计算量太大的问题.这里我们就介绍另一种基于矩阵分解的主题模型:非负矩阵分解(NMF),它同样使用了矩阵分解 ...
- 我是这样一步步理解--主题模型(Topic Model)、LDA
1. LDA模型是什么 LDA可以分为以下5个步骤: 一个函数:gamma函数. 四个分布:二项分布.多项分布.beta分布.Dirichlet分布. 一个概念和一个理念:共轭先验和贝叶斯框架. 两个 ...
- 文本主题模型之潜在语义索引(LSI)
在文本挖掘中,主题模型是比较特殊的一块,它的思想不同于我们常用的机器学习算法,因此这里我们需要专门来总结文本主题模型的算法.本文关注于潜在语义索引算法(LSI)的原理. 1. 文本主题模型的问题特点 ...
- 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率
隐马尔科夫模型HMM(一)HMM模型 隐马尔科夫模型HMM(二)前向后向算法评估观察序列概率 隐马尔科夫模型HMM(三)鲍姆-韦尔奇算法求解HMM参数(TODO) 隐马尔科夫模型HMM(四)维特比算法 ...
- 自然语言处理之LDA主题模型
1.LDA概述 在机器学习领域,LDA是两个常用模型的简称:线性判别分析(Linear Discriminant Analysis)和 隐含狄利克雷分布(Latent Dirichlet Alloca ...
- 机器学习-LDA主题模型笔记
LDA常见的应用方向: 信息提取和搜索(语义分析):文档分类/聚类.文章摘要.社区挖掘:基于内容的图像聚类.目标识别(以及其他计算机视觉应用):生物信息数据的应用; 对于朴素贝叶斯模型来说,可以胜任许 ...
- LDA概率主题模型
目录 LDA 主题模型 几个重要分布 模型 Unigram model Mixture of unigrams model PLSA模型 LDA 怎么确定LDA的topic个数? 如何用主题模型解决推 ...
随机推荐
- python+request+robot framework接口自动化测试
python+requests实现接口的请求前篇已经介绍,还有不懂或者疑问的可以访问 python+request接口自动化框架 目前我们需要考虑的是如何实现关键字驱动实现接口自动化输出,通过关键字的 ...
- Invalid command 'RailsBaseURI'
官方指导 http://www.redmine.org/projects/redmine/wiki/HowTo_Install_Redmine_on_Ubuntu_step_by_step 解决使 ...
- 一些CSS/JS小技巧
CSS部分 1.文本框不可点击 .inputDisabled{ background-color: #eee;cursor: not-allowed;} 2.禁止复制粘贴 onpaste=" ...
- var的一些理解
var 是 variable(变量,可变物)的简写.在多种编程语言中,var 被用作定义变量的关键字,在一些操作系统中也能见到它的身影.类似object,但是效率比object高一点. var是一个局 ...
- mysql数据库实操笔记20170418
一.建立商品分类表和价格表: 1.分类表`sankeq``sankeq`CREATE TABLE cs_mysql11(id INT(11) NOT NULL AUTO_INCREMENT,categ ...
- 基于jquery 的分页插件,前端实现假分页效果
上次分享了一款jquery插件,现在依旧分享这个插件,不过上一次分享主要是用于regular框件,且每一页数据都是从后端获取过来的,这一次的分享主要是讲一次性获取完数据 然后手动进行分页.此需求基本上 ...
- HTML表单基本格式与代码
咱们先来看下今天咱们需要学习的内容,理解起来很简单,像我这种英语不好的只是需要背几个单词 在HTML中创建表单需要用到的最基本的代码和格式 <form method="post/get ...
- JS中的循环嵌套 BOM函数
[嵌套循环特点] 外层循环转一次,内层循环转一圈 外层循环控制行数,内层循环控制每行元素个数 [做 ...
- 关于Java内存管理的几个小技巧
这里将介绍几则Java内存管理的小技巧,让你让你从Java入门开始告别陋习,为Java程序提速.有不少人都说"Java完了,只等着衰亡吧!",为什么呢?最简单的的例子就是Java做 ...
- Linux 练习(1)
1) 新建用户natasha,uid为1000,gid为555,备注信息为"master" useradd -u 1000 -g 555 -c 'master' natasha2) ...