【算法】字典的诞生:有序数组 PK 无序链表
- 有序数组
- 无序链表
(二叉树的实现方案将在下一篇文章介绍)
字典的定义和相关操作
- 查询某个特定的数据是否在查找表中
- 检索某个特定的数据元素的各种属性
- 在查找表中插入一个数据元素
- 从查找表中删除某个数据元素
有序数组实现字典
有序数组实现字典思路



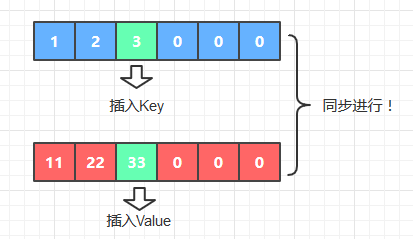
Key和Value的位置是相同的
字典长度和数组长度
- 数组长度是创建后固定不变的,例如一开始就是N
- 字典的长度是可变的, 开始是0, 逐渐递增到N。


选择有序数组的原因
- 选择无序数组实现字典, 也就意味着选择了顺序查找。
- 而选择有序数组实现字典, 代表着你可以选择二分查找(或插值查找等), 并享受查找性能上的巨大提升。
三个成员变量,一个核心方法
public class BinarySearchST {
int [] keys; // 存储key
int [] vals; // 存储value
int N = 0; // 计算字典长度
public BinarySearchST (int n) { // 根据输入的数组长度初始化keys和vals
keys = new int[n];
vals = new int[n];
}
public int rank (int key) { // 查找Key的位置并返回
// 核心方法
}
public void put (int key, int val) {
// 通过一些方式调用rank
}
public int get (int key) {
// 通过一些方式调用rank
}
public int delete (int key) {
// 通过一些方式调用rank
}
}
无序链表实现的字典API
1. rank方法
- 查找成功,返回Key的位置
- 查找失败(Key不存在),返回 - 1
- 查找成功,返回Key的位置
- 查找失败(Key不存在),返回小于给定Key的元素数量
public int rank (int key) {
int mid;
int low= 0,high = N-1;
while (low<=high) {
mid = (low + high)/2;
if(key<keys[mid]) {
high = mid - 1;
}
else if(key>keys[mid]) {
low = mid + 1;
}
else {
return mid; // 查找成功,返回Key的位置
}
}
return low; // 返回小于给定Key的元素数量
}
2. put方法
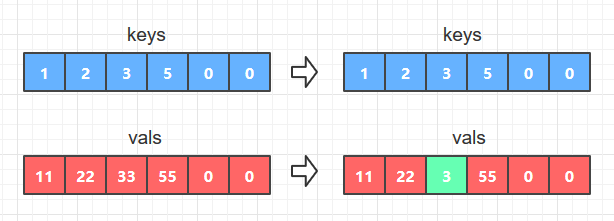
- 如果key等于keys[i],说明查找成功, 那么只要替换vals数组中的vals[i]为新的val就可以了,如图A
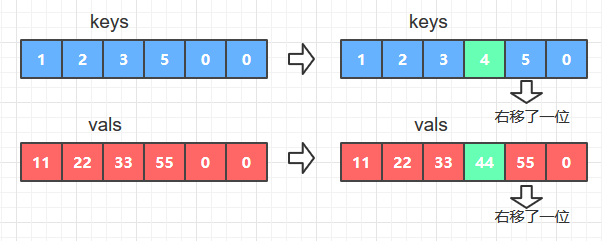
- 如果key不等于keys[i],那么在字典中插入新的 key-val键值对,具体操作是将数组keys和vals中大于给定key和val的元素全部右移一位, 然后使keys[i]=key; vals[i] = val; 如图B


public void put (int key, int val) {
int i = rank(key);
if(i<N&&key == keys[i]) { // 查找到Key, 替换vals[i]为val
vals[i] = val;
return ; // 返回
}
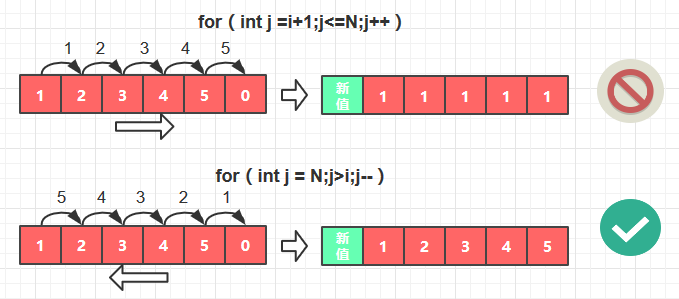
for (int j=N;j>i;j-- ) { // 未查找到Key
keys[j] = keys[j-1]; // 将keys数组中小于key的值全部右移一位
vals[j] = vals[j-1]; // 将vals数组中小于val的值全部右移一位
}
keys[i] = key; // 插入给定的key
vals[i] = val; // 插入给定的val
N++;
}


for (int j=N;j>i;j-- ) {
}
for (int j=i + 1;j<=N;j++ ) {
}

3. get方法
public boolean isEmpty () {
return N == 0;
} // 判断字典是否为空(不是数组!)
public int get (int key) {
if(isEmpty()) return -1; // 当字典为空时,不需要进行查找,提示操作失败
int i = rank(key);
if(i<N&&keys[i] == key) {
return vals[i]; // 当查找成功时候, 返回和key对应的value值
}
return -1; // 没有查找到给定的key,提示操作失败
}
4. delete方法
- 和get方法一样, 查找前要通过isEmpty判断字典是否为空,是则无需删除
- 和put方法类似, 删除要将keys/vals中大于key/value的元素全部“左移一位”
public int delete (int key) {
if(isEmpty()) return -1; // 字典为空, 无需删除
int i = rank(key);
if(i<N&&keys[i] == key) { // 当给定key存在时候,删除该key-value对
for(int j=i;j<=N-1;j++) {
keys[j] = keys[j+1]; // 删除key
vals[j] = keys[j+1]; // 删除value
}
N--; // 字典长度减1
return key; // 删除成功,返回被删除的key
}
return -1; // 未查找到给定key,删除失败
}
for (int j=N;j>i;j-- ) { }
for(int j=i;j<=N-1;j++) { }
5. floor方法

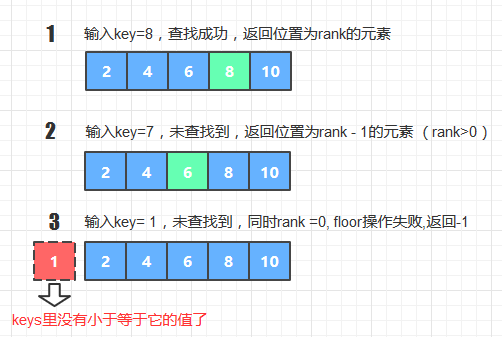
public int floor (int key) {
int k = get(key); // 查找key, 返回其value
int rank = rank(key); // 返回给定key的位置
if(k!=-1) return key; // 查找成功,返回值为key
else if(k==-1&&rank>0) return keys[rank-1]; // 未查找到key,同时给定key并没有排在字典最左端,则返回小于key的前一个值
else return -1; // 未查找到key,给定Key排在字典最左端,没有floor值
}
6. ceiling方法
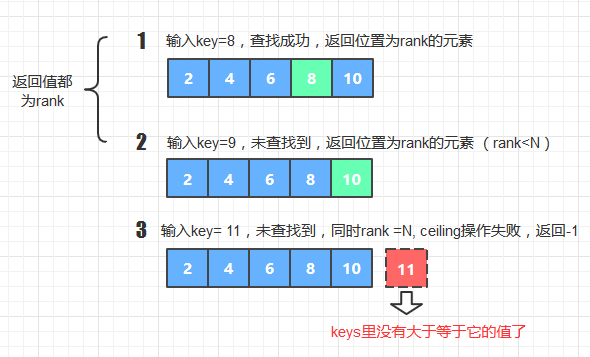
代码
public int ceiling (int key) {
int k = rank(key);
if(k==N) return -1;
return keys[k];
}

7. size方法
public int size () { return N; }
- 在声明N的时候初始化了: int N = 0;
- put操作完成时执行了N++
- delete操作完成时执行了N--;
8. max, min,select方法
public int max () { return keys[N-1]; } // 返回最大的key
public int min () { return keys[0]; } // 返回最小的key
public int select (int k) { // 根据下标返回key
if(k<0||k>N) return -1;
return keys[k];
}
9. resize
keys = tempKeys;
vals = tempVals;
private void resize (int max) { // 调整数组大小
int [] tempKeys = new int[max];
int [] tempVals = new int[max];
for(int i=0;i<N;i++) {
tempKeys[i] = keys[i];
tempVals[i] = vals[i];
}
keys = tempKeys;
vals = tempVals;
}
// 字典长度赶上了数组长度,将数组长度扩大为原来的2倍
if(N == keys.length) { resize(2*keys.length) }
/**
* @Author: HuWan Peng
* @Date Created in 11:54 2017/12/10
*/
public class BinarySearchST {
int [] keys;
int [] vals;
int N = 0;
public BinarySearchST (int n) {
keys = new int[n];
vals = new int[n];
} public int size () { return N; } public int max () { return keys[N-1]; } // 返回最大的key public int min () { return keys[0]; } // 返回最小的key public int select (int k) { // 根据下标返回key
if(k<0||k>N) return -1;
return keys[k];
} public int rank (int key) {
int mid;
int low= 0,high = N-1;
while (low<=high) {
mid = (low + high)/2;
if(key<keys[mid]) {
high = mid - 1;
}
else if(key>keys[mid]) {
low = mid + 1;
}
else {
return mid;
}
}
return low;
} public void put (int key, int val) {
int i = rank(key);
if(i<N&&key == keys[i]) { // 查找到Key, 替换vals[i]为val
vals[i] = val;
return ; // 返回
}
for (int j=N;j>i;j-- ) { // 未查找到Key
keys[j] = keys[j-1]; // 将keys数组中小于key的值全部右移一位
vals[j] = vals[j-1]; // 将vals数组中小于val的值全部右移一位
}
keys[i] = key; // 插入给定的key
vals[i] = val; // 插入给定的val
N++;
} public boolean isEmpty () {
return N == 0;
} // 判断字典是否为空(不是数组!) public int get (int key) {
if(isEmpty()) return -1; // 当字典为空时,不需要进行查找,提示操作失败
int i = rank(key);
if(i<N&&keys[i] == key) {
return vals[i]; // 当查找成功时候, 返回和key对应的value值
}
return -1; // 没有查找到给定的key,提示操作失败
} public int delete (int key) {
if(isEmpty()) return -1; // 字典为空, 无需删除
int i = rank(key);
if(i<N&&keys[i] == key) { // 当给定key存在时候,删除该key-value对
for(int j=i;j<=N-1;j++) {
keys[j] = keys[j+1]; // 删除key
vals[j] = keys[j+1]; // 删除value
}
N--; // 字典长度减1
return key; // 删除成功,返回被删除的key
}
return -1; // 未查找到给定key,删除失败
} public int ceiling (int key) {
int k = rank(key);
if(k==N) return -1;
return keys[k];
} public int floor (int key) {
int k = get(key); // 查找key, 返回其value
int rank = rank(key); // 返回给定key的位置
if(k!=-1) return key; // 查找成功,返回值为key
else if(k==-1&&rank>0) return keys[rank-1]; // 未查找到key,同时给定key并没有排在字典最左端,则返回小于key的前一个值
else return -1; // 未查找到key,给定Key排在字典最左端,没有floor值
} }
无序链表
字典类的结构
public class SequentialSearchST {
Node first; // 头节点
int N = 0; // 链表长度
private class Node { // 内部Node类
int key;
int value;
Node next; // 指向下一个节点
public Node (int key,int value,Node next) {
this.key = key;
this.value = value;
this.next = next;
}
}
public void put (int key, int value) { }
public int get (int key) { }
public void delete (int key) { }
}

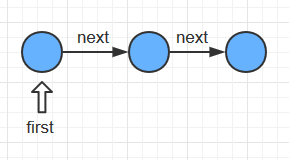
链表和数组在实现字典的不同点
无序链表实现的字典API
1. put 方法
public void put (int key, int value) {
for(Node n=first;n!=null;n=n.next) { // 遍历链表节点
if(n.key == key) { // 查找到给定的key,则更新相应的value
n.value = value;
return;
}
}
// 遍历完所有的节点都没有查找到给定key
// 1. 创建新节点,并和原first节点建立“next”的联系,从而加入链表
// 2. 将first变量修改为新加入的节点
first = new Node(key,value,first);
N++; // 增加字典(链表)的长度
}
first = new Node(key,value,first);
Node newNode = new Node(key,value,first); // 1. 创建新节点,并和原first节点建立“next”的联系
first = newNode // 2. 将first变量修改为新加入的节点


2. get方法
public int get (int key) {
for(Node n=first;n!=null;n=n.next) {
if(n.key==key) return n.value;
}
return -1;
}
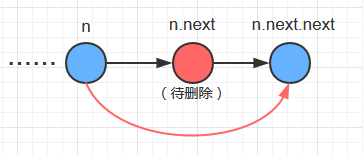
3. delete方法
public void delete (int key) {
for(Node n =first;n!=null;n=n.next) {
if(n.next.key==key) {
n.next = n.next.next;
N--;
return ;
}
}
}
if(n.next.key==key) {
n.next = n.next.next;
}

/**
* @Author: HuWan Peng
* @Date Created in 17:26 2017/12/10
*/
public class SequentialSearchST {
Node first; // 头节点
int N = 0; // 链表长度
private class Node {
int key;
int value;
Node next; // 指向下一个节点
public Node (int key,int value,Node next) {
this.key = key;
this.value = value;
this.next = next;
}
}
public int size () {
return N;
}
public void put (int key, int value) {
for(Node n=first;n!=null;n=n.next) { // 遍历链表节点
if(n.key == key) { // 查找到给定的key,则更新相应的value
n.value = value;
return;
}
}
// 遍历完所有的节点都没有查找到给定key
// 1. 创建新节点,并和原first节点建立“next”的联系,从而加入链表
// 2. 将first变量修改为新加入的节点
first = new Node(key,value,first);
N++; // 增加字典(链表)的长度
}
public int get (int key) {
for(Node n=first;n!=null;n=n.next) {
if(n.key==key) return n.value;
}
return -1;
}
public void delete (int key) {
for(Node n =first;n!=null;n=n.next) {
if(n.next.key==key) {
n.next = n.next.next;
N--;
return ;
}
}
}
}
有序数组和无序链表实现字典的性能差异





【算法】字典的诞生:有序数组 PK 无序链表的更多相关文章
- 【算法】实现字典API:有序数组和无序链表
参考资料 <算法(java)> — — Robert Sedgewick, Kevin Wayne <数据结构> ...
- 《Java数据结构与算法》笔记-CH2有序数组
/** * 上个例子是无序数组,并且没有考虑重复元素的情况. * 下面来设计一个有序数组,我们设定不允许重复,这样提高查找的速度,但是降低了插入操作的速度. * 1.线性查找 * 2.二分查找 * 有 ...
- java面向对象的有序数组和无序数组的比较
package aa; class Array{ //定义一个有序数组 private long[] a; //定义数组长度 private int nElems; //构造函数初始化 public ...
- (算法)两个有序数组的第k大的数
题目: 有两个数组A和B,假设A和B已经有序(从大到小),求A和B数组中所有数的第K大. 思路: 1.如果k为2的次幂,且A,B 的大小都大于k,那么 考虑A的前k/2个数和B的前k/2个数, 如果A ...
- 算法-求两个有序数组两两相加的值最小的K个数
我的思路是: 用队列, 从(0,0)開始入队,每次出队的时候,选(1,0) (0,1) 之间最小的入队,假设是相等的都入队,假设入过队的就不入了,把出队的k个不同的输出来就可以 我測试了几组数据都是 ...
- iOS常用算法之两个有序数组合并, 要求时间复杂度为0(n)
思路: 常规思路: 先将一个数组作为合并后的数组, 然后遍历第二个数组的每项元素, 一一对比, 直到找到合适的, 就插入进去; 简单思路: 设置数组C, 对比A和B数组的首项元素, 找到最小的, 就放 ...
- python经典面试算法题1.2:如何从无序链表中移除重复项
本题目摘自<Python程序员面试算法宝典>,我会每天做一道这本书上的题目,并分享出来,统一放在我博客内,收集在一个分类中. 1.2 如何实现链表的逆序 [蚂蚁金服面试题] 难度系数:⭐⭐ ...
- [Effective JavaScript 笔记]第46条:使用数组而不要使用字典来存储有序集合
对象属性无序性 js对象是一个无序属性集合. var obj={}; obj.a=10; obj.b=30; 属性a和属性b并没有谁前谁后之说.for...in循环,先输出哪个属性都有可能.获取和设置 ...
- 【算法之美】求解两个有序数组的中位数 — leetcode 4. Median of Two Sorted Arrays
一道非常经典的题目,Median of Two Sorted Arrays.(PS:leetcode 我已经做了 190 道,欢迎围观全部题解 https://github.com/hanzichi/ ...
随机推荐
- mongo+mongoose+express
直接上指令: //*代表自定义名字 //使用数据库 use * //检查当前数据库 db //查询数据库列表 show dbs //查询当前数据库集合 show collections //插入文档自 ...
- 如何清楚微信页面的缓存(静态资源(图片,js,页面))
就不说啥子原因了,反正就是微信的缓存问题,照着下面的做法做,一定ok了. 不过就是有些麻烦,但是微信的缓存是为了提高自身的性能,我们这些开发要用人家的平台,只有自己去填坑了. 直接贴代码好了,加上去就 ...
- HDU 3584 Cube(三位树状数组)
Cube Time Limit: 2000/1000 MS (Java/Others) Memory Limit: 131072/65536 K (Java/Others)Total Submi ...
- .Net Core在Ubuntu上操作MySql折腾实录
.Net Core 2.0 发布也这么久了,一直想着折腾着玩玩,无奈一直没时间,这几天准备开始好好学习下C#在跨平台方面的应用,记录下来以备自己以后回忆.学习. 本篇博客的主要内容: MySql在Ub ...
- HDFS--笔记
HDFS的简介 分布式的文件系统,基于流数据模式访问和处理超大文件的分布式文件系统 Hadoop Distributed File System HDFS的优点 处理超大文件 流数据访问 运行廉价的商 ...
- Cocoapods安装过程
1.升级Ruby环境 gem -v gem update --system 如果没有权限去升级Ruby ?就输入 sudo gem update --system 2.换掉Ruby镜像 首先移除现有的 ...
- 在微信端使用video标签,播放结束会出现QQ浏览器推荐视频的解决办法(vue)
会出现播放结束显示QQ浏览器推荐视频的原因:(我是vue的项目,而且我是新手,只是单纯的给大家分享一个方法,代码比较low请自动忽略) 因为在x5(QQ浏览器)内核中,把video标签劫持了,只要是检 ...
- no suitable driver found for jdbc:mysql//localhost:3306/..
出现这样的情况,一般有四种原因(网上查的): 一:连接URL格式出现了问题(Connection conn=DriverManager.getConnection("jdbc:mysql ...
- Maven中settings.xml的配置项说明精讲
1.Maven的配置文件(Maven的安装目录/conf/settings.xml ) 和 Maven仓库下(默认的Maven仓库的是用户家目录下的.m2文件,可以另行制定)的settings.xml ...
- Fis3迁移至Webpack实战
Webpack从2015年9月第一个版本横空初始至今已逾2载.它的出现,颠覆了一大批主流构建如Ant.Grunt和Gulp等等.腾讯NOW直播IVWEB团队之前一直采用Fis构建,本篇文章主要介绍从F ...