在Ubuntu下配置运行Hadoop2.4.0单节点配置
还没有修改hosts,请先按前文修改。
还没安装java的,请按照前文配置。
(1)增加用户并设立公钥:
sudo addgroup hadoop
sudo adduser --ingroup hadoop hduser
su - hduser
cat $HOME/.ssh/id_rsa.pub >> $HOME/.ssh/authorized_keys
ssh localhost
exit
(2)把编译完的hadoop复制到/usr/local目录,并修改目录权限
cp –r /root/hadoop-2.4.0-src/hadoop-dist/target/hadoop-2.4.0 /usr/local
cd /usr/local
chown -R hduser:hadoop hadoop-2.4.0

(3)关闭ipv6
su
vi /etc/sysctl.conf
加入:
net.ipv6.conf.all.disable_ipv6 = 1
net.ipv6.conf.default.disable_ipv6 = 1
net.ipv6.conf.lo.disable_ipv6 = 1
重启:
reboot
测试:
cat /proc/sys/net/ipv6/conf/all/disable_ipv6

输出1表示ipv6已关闭。
(4)修改启动配置文件~/.bashrc
su hduser
vi ~/.bashrc
加入以下代码:
JAVA_HOME=/usr/lib/jvm/jdk1.7.0_55
JRE_HOME=${JAVA_HOME}/jre
export ANDROID_JAVA_HOME=$JAVA_HOME
export CLASSPATH=.:${JAVA_HOME}/lib:$JRE_HOME/lib:${JAVA_HOME}/lib/tools.jar:$CLASSPATH
export JAVA_PATH=${JAVA_HOME}/bin:${JRE_HOME}/bin
export JAVA_HOME;
export JRE_HOME;
export CLASSPATH;
HOME_BIN=~/bin/
export PATH=${PATH}:${JAVA_PATH}:${HOME_BIN};
export PATH=${JAVA_HOME}/bin:$PATH
export HADOOP_HOME=/usr/local/hadoop-2.4.0
unalias fs &> /dev/null
alias fs="hadoop fs"
unalias hls &> /dev/null
alias hls="fs -ls"
lzohead () {
hadoop fs -cat $1 | lzop -dc | head -1000 | less
}
export PATH=$PATH:$HADOOP_HOME/bin
export HADOOP_COMMON_LIB_NATIVE_DIR=$HADOOP_HOME/lib/native
#export HADOOP_OPTS=-Djava.net.preferIPv4Stack=true
export HADOOP_OPTS="-Djava.library.path=$HADOOP_HOME/lib"
export HADOOP_MAPRED_HOME=$HADOOP_HOME
export HADOOP_COMMON_HOME=$HADOOP_HOME
export HADOOP_HDFS_HOME=$HADOOP_HOME
export YARN_HOME=$HADOOP_HOME
export HADOOP_CONF_DIR=$HADOOP_HOME/etc/hadoop
使修改生效:
source ~/.bashrc
(5)在hadoop目录中创建datanode和namenode目录
mkdir -p $HADOOP_HOME/yarn/yarn_data/hdfs/namenode
mkdir -p $HADOOP_HOME/yarn/yarn_data/hdfs/datanode
(6)修改Hadoop配置参数
为了方便可以 cd $HADOOP_CONF_DIR
在$HADOOP_HOME下直接执行:
vi etc/hadoop/hadoop-env.sh
加入JAVA_HOME变量
export JAVA_HOME=/usr/lib/jvm/jdk1.7.0_55
vi etc/hadoop/yarn-site.xml
加入以下信息:
<property> <name>yarn.nodemanager.aux-services</name> <value>mapreduce_shuffle</value> </property> <property> <name>yarn.nodemanager.aux-services.mapreduce_shuffle.class</name> <value>org.apache.hadoop.mapred.ShuffleHandler</value> </property>
建立hadoop.tmp.dir
sudo mkdir -p /app/hadoop/tmp
(如果出错:hduser is not in the sudoers file. This incident will be reported.
su
vi /etc/sudoers
加入hduser ALL=(ALL) ALL
)
#sudo chown hduser:hadoop /app/hadoop/tmp
sudo chown -R hduser:hadoop /app
sudo chmod 750 /app/hadoop/tmp
cd $HADOOP_HOME
vi etc/hadoop/core-site.xml
<property>
<name>hadoop.tmp.dir</name>
<value>/app/hadoop/tmp</value>
<description>A base for other temporary directories.</description>
</property>
<property>
<name>fs.default.name</name>
<value>hdfs://localhost:9000</value>
</property>
vi etc/hadoop/hdfs-site.xml
<property> <name>dfs.replication</name> <value>1</value> </property> <property> <name>dfs.namenode.name.dir</name> <value>file:/usr/local/hadoop-2.4.0/yarn/yarn_data/hdfs/namenode</value> </property> <property> <name>dfs.datanode.data.dir</name> <value>file:/usr/local/hadoop-2.4.0/yarn/yarn_data/hdfs/datanode</value> </property>
vi etc/hadoop/mapred-site.xml
<property>
<name>mapreduce.framework.name</name>
<value>yarn</value>
</property>
好
(7)格式化namenode节点:
bin/hadoop namenode –format

(8)运行Hadoop 示例
sbin/hadoop-daemon.sh start namenode
sbin/hadoop-daemon.sh start datanode
sbin/hadoop-daemon.sh start secondarynamenode
sbin/yarn-daemon.sh start resourcemanager
sbin/yarn-daemon.sh start nodemanager
sbin/mr-jobhistory-daemon.sh start historyserver
(9)监测运行情况:
jps

netstat –ntlp

http://localhost:50070/ for NameNode
http://localhost:8088/cluster for ResourceManager
http://localhost:19888/jobhistory for Job History Server



(10)出错处理:
log文件存放目录:
cd $HADOOP_HOME/logs
或进入namenode网页查看log
http://192.168.85.136:50070/logs/hadoop-hduser-datanode-ubuntu.log
1.错误:
出现DataNode启动后jps进程消失,阅读以下网页查看log,
http://192.168.85.136:50070/logs/hadoop-hduser-datanode-ubuntu.log
错误信息如下:
2014-07-07 03:03:41,446 FATAL org.apache.hadoop.hdfs.server.datanode.DataNode: Initialization failed for block pool Block pool <registering> (Datanode Uuid unassigned) service to localhost/127.0.0.1:9000
发现问题:./bin/hadoop namenode –format重新创建一个namenodeId,而存放datanode数据的tmp/dfs/data目录下包含了上次format下的 id,namenode format清空了namenode下的数据,但是没有清除datanode下的数据,导致启动时失败,所要做的就是每次fotmat前,清空tmp一下 的所有目录.
参考:http://stackoverflow.com/questions/22316187/datanode-not-starts-correctly
解决办法:
rm -rf /usr/local/hadoop-2.4.0/yarn/yarn_data/hdfs/*
./bin/hadoop namenode –format
2.警告调试:
14/07/03 06:13:25 WARN util.NativeCodeLoader: Unable to load native-hadoop library for your platform... using builtin-java classes where applicable
调试:
export HADOOP_ROOT_LOGGER=DEBUG,console
hadoop fs -text /test/data/origz/access.log.gz
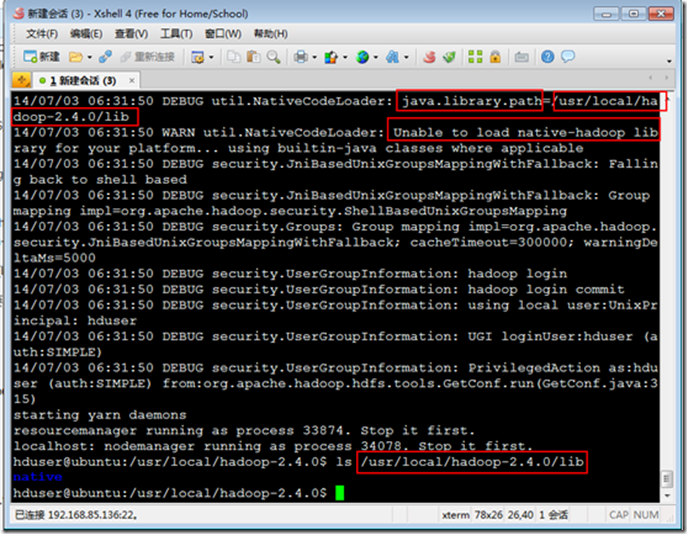
解决办法:
cp /usr/local/hadoop-2.4.0/lib/native/* /usr/local/hadoop-2.4.0/lib/
(11)创建一个文本文件,把它放进Hdfs中:
mkdir in
vi in/file
Hadoop is fast
Hadoop is cool
bin/hadoop dfs -copyFromLocal in/ /in

(12)运行wordcount示例程序:
bin/hadoop jar share/hadoop/mapreduce/hadoop-mapreduce-examples-2.4.0.jar wordcount /in /out

(13)查看运行结果:
bin/hadoop fs -ls /out
bin/hadoop dfs -cat /out/part-r-00000

或者也可以去namenode网站查询
http://localhost:50070/dfshealth.jsp
(14)关闭demo:
sbin/hadoop-daemon.sh stop namenode
sbin/hadoop-daemon.sh stop datanode
sbin/hadoop-daemon.sh stop secondarynamenode
sbin/yarn-daemon.sh stop resourcemanager
sbin/yarn-daemon.sh stop nodemanager
sbin/mr-jobhistory-daemon.sh stop historyserver
这篇文章参考了两篇非常不错的博客文章,现列在下方,以便参考:
http://www.thecloudavenue.com/2012/01/getting-started-with-nextgen-mapreduce.html
http://www.michael-noll.com/tutorials/running-hadoop-on-ubuntu-linux-single-node-cluster/
在Ubuntu下配置运行Hadoop2.4.0单节点配置的更多相关文章
- 在Ubuntu14.10中部署Hadoop2.6.0单节点伪分布集群
1. 环境信息如下: ubuntu:14.10 jdk:openjdk-1.7.0 hadoop:2.6.0 2. 下载hadoop2.6.0, http://apache.fayea.com/had ...
- Hadoop 2.2.0单节点的伪分布集成环境搭建
Hadoop版本发展历史 第一代Hadoop被称为Hadoop 1.0 1)0.20.x 2)0.21.x 3)0.22.x 第二代Hadoop被称为Hadoop 2.0(HDFS Federatio ...
- 在Ubuntu 64位OS上运行hadoop2.2.0[重新编译hadoop]
最近在学习搭建Hadoop, 我们从Apache官方网站直接下载最新版本Hadoop2.2.官方目前是提供了linux32位系统可执行文件,结果运行时发现提示 “libhadoop.so.1.0.0 ...
- Hadoop新生报到(一) hadoop2.6.0伪分布式配置详解
首先先不看理论,搭建起环境之后再看: 搭建伪分布式是为了模拟环境,调试方便. 电脑是win10,用的虚拟机VMware Workstation 12 Pro,跑的Linux系统是centos6.5 , ...
- Hadoop2.2.0分布式安装配置详解[2/3]
前言 本文主要通过对hadoop2.2.0集群配置的过程加以梳理,所有的步骤都是通过自己实际测试.文档的结构也是根据自己的实际情况而定,同时也会加入自己在实际过程遇到的问题.搭建环境过程不重要,重要点 ...
- Ubuntu下搭建Hyperledger Fabric v1.0环境
多次尝试才正常启动了Fabric,如遇到各种莫名错误,请参考如下一步步严格安装,特别用户权限需要注意. 一.安装Ubuntu16 虚拟机或双系统,虚拟机有VirtualBox或者VMware,Ub ...
- Hadoop2.2.0多节点分布式安装及测试
众所周知,hadoop在10月底release了最新版2.2.很多国内的技术同仁都马上在网络上推出了自己对新版hadoop的配置心得.这其中主要分为两类: 1.单节点配置 这个太简单了,简单到只要懂点 ...
- Zookeeper+Kafka的单节点配置
Zookeeper+Kafka的单节点配置 环境描述:Ubuntu16.04 server系统,在系统上搭建Java环境,jdk的版本为1.8或更高,我的服务器IP地址为192.168.0.106. ...
- kolla快速集成openstack-ocata和opencontrail-4.0.1.0单节点
参考链接: kolla快速集成openstack-ocata和opencontrail-4.0.1.0单节点 https://github.com/Juniper/contrail-docker/wi ...
随机推荐
- PHP5不重新编译,如何安装自带的未安装过的扩展,如soap扩展?
在虚拟机的CentOS5.5中,一键安装了PHP运行环境,但发现并没有 soap 扩展,而近期项目用需要用到 webservice. 上述的一键安装(lamp0.4),其实是源码编译安装,PHP配置文 ...
- php引用
1.需求 了解php引用 2.变量的引用 目前为止看到的引用是变量的引用, 例子1 $a="ABC"; $b =&$a; echo $a;//这里输出:ABC echo $ ...
- phpstorm的使用教程
1.设置行号:file->settings->Editor->Appearance->Show line numbers 2.设置字体和背景 :file->setting ...
- Python日志logging
logging 用于便捷记录日志且线程安全的模块 1.单文件日志 import logging logging.basicConfig(filename='log.log', format='%(as ...
- poj 1270(toposort)
http://poj.org/problem?id=1270 题意:给一个字符串,然后再给你一些规则,要你把所有的情况都按照字典序进行输出. 思路:很明显这肯定要用到拓扑排序,当然看到discuss里 ...
- java22
1:登录注册IO版本案例(掌握) 要求,对着写一遍. cn.itcast.pojo User cn.itcast.dao UserDao cn.itcast.dao.impl UserDaoImpl( ...
- PHP获取一段时间内的每个周几, 每月几号, 遇到特殊日子就往后延
2016年11月1日 16:18:19 星期二 主要用到的函数是 strtotime() strtotime('+1 Tuesday', $timestamp) 获取下周二, 从时间戳$timesta ...
- ffmpeg-20160926[27]-bin.7z
ffplay 2016.09.26 开始使用 SDL 2.x , CPU 利用率比 SDL 1.x 略微好一些. ESC 退出 0 进度条开关 1 屏幕原始大小 2 屏幕1/2大小 3 屏幕1/3大小 ...
- VIM插件攻略
工欲善其事,必先利其器.一个强大的开发环境可以大大提高工作效率.好吧,我知道这是废话...不过,我想一定有很多跟我一样打算进入Linux平台开发的新手,一开始都为找不到一个像Windows下的VS那样 ...
- 【目录】processing
Processing 小代码 小代码2 小代码3 小代码4 小代码5