Elasticsearch JAVA api轻松搞定groupBy聚合
本文给出如何使用Elasticsearch的Java API做类似SQL的group by聚合。
为了简单起见,只给出一级groupby即group by field1(而不涉及到多级,例如group by field1, field2, ...);如果你需要多级的groupby,在实现上可能需要拆分的更加细致。
即将给出的方法,适用于如下的场景:
场景1:找出分组中的所有桶,例如,select group_name from index_name group by group_name;
场景2:灵活添加一个或者多个聚合函数,例如,select group_name, max(count), avg(count) group by group_name;
1、用法
GroupBy类是我们的实现。
1)测试用例
public static void main(String[] args) {
/*
* 初始化es客户端
* */
ESClient esClient = new ESClient(
"dqa-cluster",
"10.93.21.21:9300,10.93.18.34:9300,10.93.18.35:9300,100.90.62.33:9300,100.90.61.14:9300",
false);
/*
* 为了演示, 构造了一个距离查询, 相当于where子句.
* */
GeoDistanceRangeQueryBuilder queryBuilder = QueryBuilders.geoDistanceRangeQuery("location")
.point(39.971424, 116.398251)
.from("0m")
.to(String.format("%fm", 500.0))
.includeLower(true)
.includeUpper(true)
.optimizeBbox("memory")
.geoDistance(GeoDistance.SLOPPY_ARC);
SearchRequestBuilder search = esClient.getClient().prepareSearch("moon").setTypes("bj")
.setSearchType(SearchType.DFS_QUERY_AND_FETCH)
.setQuery(queryBuilder);
/*
* GroupBy类就是我们的实现, 初始化的时候传入的参数依次是, search, 桶命名, 分桶字段, 排序asc
* select date as date_group from index group by date;
* */
GroupBy groupBy = new GroupBy(search, "date_group", "date", true);
/*
* 添加各种分组函数
* 这里我实现了10种, 下面是其中的6种
* */
groupBy.addSumAgg("pre_total_fee_sum", "pre_total_fee");
groupBy.addAvgAgg("pre_total_fee_avg", "pre_total_fee");
groupBy.addPercentilesAgg("pre_total_fee_percent", "pre_total_fee");
groupBy.addPercentileRanksAgg("pre_total_fee_percentRank", "pre_total_fee", new double[]{13, 16, 20});
groupBy.addStatsAgg("pre_total_fee_stats", "pre_total_fee");
groupBy.addCardinalityAgg("type_card", "type");
/*
* 获取groupBy聚合的结果
* 结果是两级Map, 这里的实现是TreeMap因为要保护桶的排序
* */
Map<String, Object> groupbyResponse = groupBy.getGroupbyResponse();
for (Map.Entry<String, Object> entry : groupbyResponse.entrySet()) {
String bucketKey = entry.getKey();
Map<String, String> subAggMap = (Map<String, String>) entry.getValue();
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_sum", subAggMap.get("pre_total_fee_sum")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_avg", subAggMap.get("pre_total_fee_avg")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_percent", subAggMap.get("pre_total_fee_percent")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_percentRank", subAggMap.get("pre_total_fee_percentRank")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "pre_total_fee_stats", subAggMap.get("pre_total_fee_stats")));
System.out.println(String.format("%s\t%s\t%s", bucketKey, "type_card", subAggMap.get("type_card")));
}
}
2)初始化
初始化的时候,相当于构造了这样一个SQL:select date as date_group from index group by date;
传入search对象,相当于where子句
传入分桶命名, 相当于 as date_group
传入分桶字段,相当于date
传入排序,asc=true
3)初始化完成后,可以添加各种聚合函数,也就是场景2。
GroupBy类里实现了10种聚合函数
4)读取结果
结果的返回是两级Map,为了保护分桶的排序,实现中使用了TreeMap。
这里需要注意的是,有些聚合函数的返回,并不是一个值,而是一组值,如Percentiles、Stats等等,这里我们把这一组值压缩成JSONString了。
5)打印输出
我们以日期进行了分桶,同一个分桶中的聚合结果,sum、avg、cardinality都是单个的值。而percentiles、percentileRanks、stats是压缩的jsonstring。
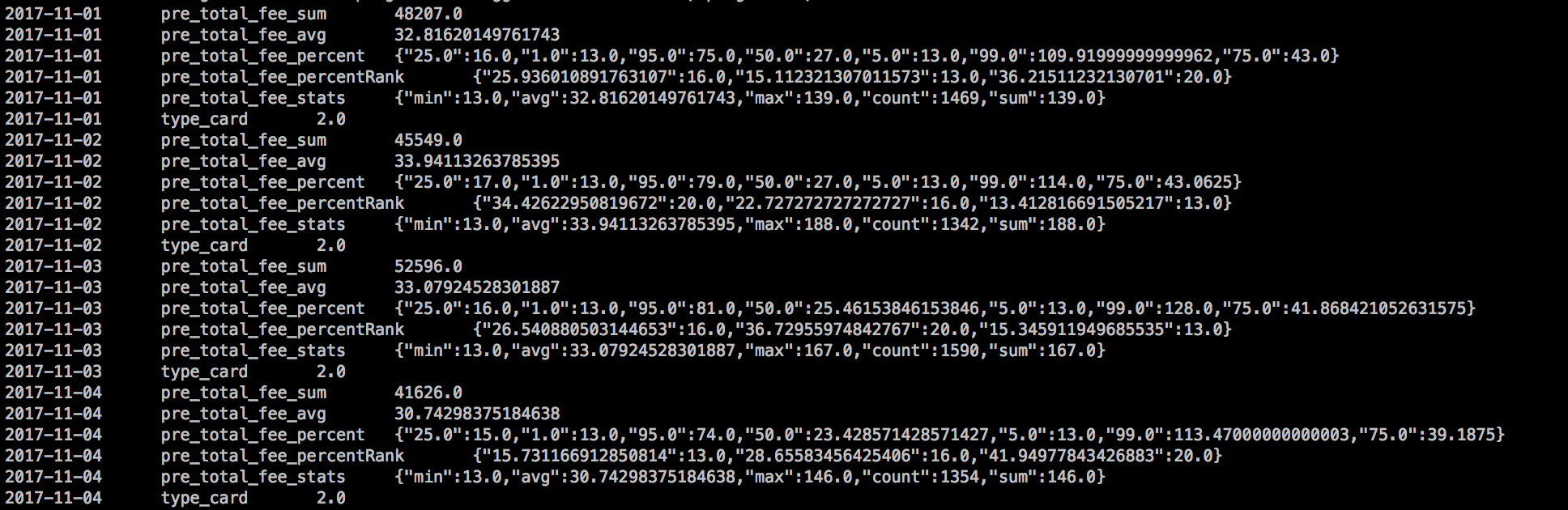
2、实现
先上代码,然后在后面进行讲解。
public class GroupBy {
private SearchRequestBuilder search;
private String termsName;
private TermsBuilder termsBuilder;
private List<Map<String, Object>> subAggList = new ArrayList<Map<String, Object>>();
public GroupBy(SearchRequestBuilder search, String termsName, String fieldName, boolean asc) {
this.search = search;
this.termsName = termsName;
termsBuilder = AggregationBuilders.terms(termsName).field(fieldName).order(Terms.Order.term(asc)).size(0);
}
private void addSubAggList(String aggName, MetricsAggregationBuilder aggBuilder) {
Map<String, Object> subAgg = new HashMap<String, Object>();
subAgg.put("aggName", aggName);
subAgg.put("aggBuilder", aggBuilder);
subAggList.add(subAgg);
}
public void addSumAgg(String aggName, String fieldName) {
SumBuilder builder = AggregationBuilders.sum(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketSumAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof SumBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addCountAgg(String aggName, String fieldName) {
ValueCountBuilder builder = AggregationBuilders.count(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketCountAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof ValueCountBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addAvgAgg(String aggName, String fieldName) {
AvgBuilder builder = AggregationBuilders.avg(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketAvgAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof AvgBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addMinAgg(String aggName, String fieldName) {
MinBuilder builder = AggregationBuilders.min(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketMinAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof MinBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addMaxAgg(String aggName, String fieldName) {
MaxBuilder builder = AggregationBuilders.max(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketMaxAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof MaxBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public void addStatsAgg(String aggName, String fieldName) {
StatsBuilder builder = AggregationBuilders.stats(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketStatsAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof StatsBuilder) {
Stats stats = bucket.getAggregations().get(aggName);
JSONObject jsonObject = new JSONObject();
jsonObject.put("min", stats.getMin());
jsonObject.put("max", stats.getMax());
jsonObject.put("sum", stats.getMax());
jsonObject.put("count", stats.getCount());
jsonObject.put("avg", stats.getAvg());
tmpMap.put(aggName, jsonObject.toJSONString());
return true;
} else {
return false;
}
}
public void addExtendedStatsAgg(String aggName, String fieldName) {
ExtendedStatsBuilder builder = AggregationBuilders.extendedStats(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketExtendedStatsAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof ExtendedStatsBuilder) {
ExtendedStats extendedStats = bucket.getAggregations().get(aggName);
JSONObject jsonObject = new JSONObject();
jsonObject.put("min", extendedStats.getMin());
jsonObject.put("max", extendedStats.getMax());
jsonObject.put("sum", extendedStats.getMax());
jsonObject.put("count", extendedStats.getCount());
jsonObject.put("avg", extendedStats.getAvg());
jsonObject.put("stdDeviation", extendedStats.getStdDeviation());
jsonObject.put("sumOfSquares", extendedStats.getSumOfSquares());
jsonObject.put("variance", extendedStats.getVariance());
tmpMap.put(aggName, jsonObject.toJSONString());
return true;
} else {
return false;
}
}
public void addPercentilesAgg(String aggName, String fieldName) {
PercentilesBuilder builder = AggregationBuilders.percentiles(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public void addPercentilesAgg(String aggName, String fieldName, double[] percentiles) {
PercentilesBuilder builder = AggregationBuilders.percentiles(aggName).field(fieldName).percentiles(percentiles);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketPercentilesAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof PercentilesBuilder) {
Percentiles percentiles = bucket.getAggregations().get(aggName);
JSONObject jsonObject = new JSONObject();
for (Percentile percentile : percentiles) {
jsonObject.put(String.valueOf(percentile.getPercent()), percentile.getValue());
}
tmpMap.put(aggName, jsonObject.toJSONString());
return true;
} else {
return false;
}
}
public void addPercentileRanksAgg(String aggName, String fieldName, double[] percentiles) {
PercentileRanksBuilder builder = AggregationBuilders.percentileRanks(aggName).field(fieldName).percentiles(percentiles);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketPercentileRanksAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof PercentileRanksBuilder) {
PercentileRanks percentileRanks = bucket.getAggregations().get(aggName);
JSONObject jsonObject = new JSONObject();
for (Percentile percentile : percentileRanks) {
jsonObject.put(String.valueOf(percentile.getPercent()), percentile.getValue());
}
tmpMap.put(aggName, jsonObject.toJSONString());
return true;
} else {
return false;
}
}
public void addCardinalityAgg(String aggName, String fieldName) {
CardinalityBuilder builder = AggregationBuilders.cardinality(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
public boolean bucketCardinalityAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof CardinalityBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
public List<Terms.Bucket> getTermsBucket() {
search.addAggregation(termsBuilder);
Terms termsGroup = search.get().getAggregations().get(termsName);
return termsGroup.getBuckets();
}
public Map<String, Object> getGroupbyResponse() {
Map<String, Object> aggResponseMap = new TreeMap<String, Object>();
for (Terms.Bucket bucket : getTermsBucket()) {
String bucketKeyAsString = bucket.getKeyAsString();
Map<String, String> tmpMap = new TreeMap<String, String>();
for (Map<String, Object> subAgg : subAggList) {
String subAggName = subAgg.get("aggName").toString();
MetricsAggregationBuilder subAggBuilder = (MetricsAggregationBuilder) subAgg.get("aggBuilder");
if (bucketAvgAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketMaxAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketMinAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketSumAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketCountAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketCardinalityAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketPercentileRanksAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketPercentilesAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketExtendedStatsAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketStatsAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
}
aggResponseMap.put(bucketKeyAsString, tmpMap);
}
return aggResponseMap;
}
}
1)构造函数
构造函数中,核心逻辑是termsBuilder = AggregationBuilders.terms(termsName).field(fieldName).order(Terms.Order.term(asc)).size(0);
实例化了termsBuilder也就是分桶。
后面调用add...函数簇添加聚合函数的时候,都是通过termsBuilder.subAggregation(builder)在分桶的基础上添加了子聚合。
最后在获取结果的时候search.addAggregation(termsBuilder);将termsBuilder添加到查询上,进行聚合查询。
2)添加聚合函数add...函数簇
以sum函数为例
public void addSumAgg(String aggName, String fieldName) {
SumBuilder builder = AggregationBuilders.sum(aggName).field(fieldName);
termsBuilder.subAggregation(builder);
addSubAggList(aggName, builder);
}
a)初始化了一个SumBuilder聚合操作,然后作为termsBuilder的子聚合。
b)addSubAggList方法在subAggList属性(subAggList属性是一个List<Map<String, Object>>)上保存了所有添加了的子聚合的名字和builder。这样做是为了在解析结果的时候,知道是哪种type的聚合(instanceof),以便使用不同的逻辑去解析。
private void addSubAggList(String aggName, MetricsAggregationBuilder aggBuilder) {
Map<String, Object> subAgg = new HashMap<String, Object>();
subAgg.put("aggName", aggName);
subAgg.put("aggBuilder", aggBuilder);
subAggList.add(subAgg);
}
3)按类型获取结果
还是以sum函数为例
public boolean bucketSumAgg(Terms.Bucket bucket, String aggName, MetricsAggregationBuilder aggBuilder, Map<String, String> tmpMap) {
if (aggBuilder instanceof SumBuilder) {
tmpMap.put(aggName, bucket.getAggregations().get(aggName).getProperty("value").toString());
return true;
} else {
return false;
}
}
a)这里先判断了aggBuilder是哪种类型的(instanceof),如果是SumBuilder类型的,就按照sum的结果类型去读取返回结果。
b)sum的返回结果就是一个值,当遇到percentiles这种类型的,返回结果不是一个值,此时为了简单,我将结果压缩成了jsonstring,也相当于一个值,可以自行参看代码。
c)后面依赖return true实现了一个逻辑,一旦命中了类型,就不再继续判断了,提升效率。
d)tmpMap是外部传入的一个全局接收器,用来存储结果。
4)解析所有的子聚合结果
public Map<String, Object> getGroupbyResponse() {
Map<String, Object> aggResponseMap = new TreeMap<String, Object>();
for (Terms.Bucket bucket : getTermsBucket()) {
String bucketKeyAsString = bucket.getKeyAsString();
Map<String, String> tmpMap = new TreeMap<String, String>();
for (Map<String, Object> subAgg : subAggList) {
String subAggName = subAgg.get("aggName").toString();
MetricsAggregationBuilder subAggBuilder = (MetricsAggregationBuilder) subAgg.get("aggBuilder");
if (bucketAvgAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketMaxAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketMinAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketSumAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketCountAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketCardinalityAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketPercentileRanksAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketPercentilesAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketExtendedStatsAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
if (bucketStatsAgg(bucket, subAggName, subAggBuilder, tmpMap)) continue;
}
aggResponseMap.put(bucketKeyAsString, tmpMap);
}
return aggResponseMap;
}
这里是解析结果的代码。tmpMap定义为全局接收器。
a)通过遍历subAggList存储的所有子聚合函数,获取所有的子聚合结果,并保存成两级TreeMap。
b)对每个迭代,调用所有的bucket...函数簇,这里通过if判断是否命中类型,如果命中了,就通过continue不再继续检查。
c) aggResponseMap使用treeMap是为了保持bucket的有序。
3、十种聚合函数
最后列出我们实现的十种聚合函数,你可以根据自己的需求继续添加。
1)返回单个值:sum、avg、min、max、count、cardinality(有误差)
2)percentiles:分位数查询,传入分位数,获取分位数上的值;percentileRanks,分位数排名查询,传入值,返回对应的分位数;互为逆向操作。
3)stats和extendedStats,extended聚合更详细的信息max、min、avg、sum、平方和、标准差等。
Elasticsearch JAVA api轻松搞定groupBy聚合的更多相关文章
- Elasticsearch JAVA api搞定groupBy聚合
本文给出如何使用Elasticsearch的Java API做类似SQL的group by聚合.为了简单起见,只给出一级groupby即group by field1(而不涉及到多级,例如group ...
- 【微服务】之六:轻松搞定SpringCloud微服务-API网关zuul
通过前面几篇文章的介绍,我们可以轻松搭建起来微服务体系中比较重要的几个基础构建服务.那么,在本篇博文中,我们重点讲解一下,如何将所有微服务的API同意对外暴露,这个就设计API网关的概念. 本系列教程 ...
- 【微服务】之七:轻松搞定SpringCloud微服务-API权限控制
权限控制,是一个系统当中必须的重要功能.张三只能访问输入张三的特定功能,李四不能访问属于赵六的特定菜单.这就要求对整个体系做一个完善的权限控制体系.该体系应该具备针区分用户.权限.角色等各种必须的功能 ...
- 春节过后就是金三银四求职季,分享几个Java面试妙招,轻松搞定HR!
春节过后就是金三银四,分享几个Java面试妙招,轻松搞定HR! 2020年了,先祝大家新年快乐! 今年IT职位依然相当热门,特别是Java开发岗位.软件开发人才在今年将有大量的就业机会.春节过后,金三 ...
- 【微服务】之三:从零开始,轻松搞定SpringCloud微服务-配置中心
在整个微服务体系中,除了注册中心具有非常重要的意义之外,还有一个注册中心.注册中心作为管理在整个项目群的配置文件及动态参数的重要载体服务.Spring Cloud体系的子项目中,Spring Clou ...
- 【微服务】之四:轻松搞定SpringCloud微服务-负载均衡Ribbon
对于任何一个高可用高负载的系统来说,负载均衡是一个必不可少的名称.在大型分布式计算体系中,某个服务在单例的情况下,很难应对各种突发情况.因此,负载均衡是为了让系统在性能出现瓶颈或者其中一些出现状态下可 ...
- 【微服务】之五:轻松搞定SpringCloud微服务-调用远程组件Feign
上一篇文章讲到了负载均衡在Spring Cloud体系中的体现,其实Spring Cloud是提供了多种客户端调用的组件,各个微服务都是以HTTP接口的形式暴露自身服务的,因此在调用远程服务时就必须使 ...
- 盘它!基于CANN的辅助驾驶AI实战案例,轻松搞定车辆检测和车距计算!
摘要:基于昇腾AI异构计算架构CANN(Compute Architecture for Neural Networks)的简易版辅助驾驶AI应用,具备车辆检测.车距计算等基本功能,作为辅助驾驶入门级 ...
- 【微服务】之二:从零开始,轻松搞定SpringCloud微服务系列--注册中心(一)
微服务体系,有效解决项目庞大.互相依赖的问题.目前SpringCloud体系有强大的一整套针对微服务的解决方案.本文中,重点对微服务体系中的服务发现注册中心进行详细说明.本篇中的注册中心,采用Netf ...
随机推荐
- golang lua使用示例
package main import ( "fmt" "github.com/yuin/gopher-lua" ) func hello(L *lua.LSt ...
- 04-JavaScript之常见运算符
JavaScript之常见运算符 1.赋值运算符 以var x=12,y=5来演示示例 运算符 例子 等同于 运算结果 = x=y x=5 += x+=y x=x+y x=17 -= x-=y x ...
- c++入门之函数指针和函数对象
函数指针可以方便我们调用函数,但采用函数对象,更能体现c++面向对象的程序特性.函数对象的本质:()运算符的重载.我们通过一段代码来感受函数指针和函数对象的使用: int AddFunc(int a, ...
- Webdriver获取多个元素
官方通过如下代码获取多个元素: List<WebElement> inputs = driver.findElements(By.xpath("//input")); ...
- SQL拼接字符串时单引号转义问题 单引号转义字符
要拼接一个单引号到已有字符串前后, 开始以为(错误)可以用 \ 转义,如下: '\''+ str+'\'' 看颜色就知道是不行的. 正确方法是两个单引号就转义为单引号,如下: ''''+str+'' ...
- Python——Microsoft Office编程
一.Excel 需要安装xlrd和xlwt这两个库 1.打开excel readbook = xlrd.open_workbook(r'\test\canying.xlsx') 2.获取读入的文件 ...
- 解决mysql中文乱码问题 在url后面添加?characterEncoding=utf8
- <数据结构基础学习>(三)Part 1 栈
一.栈 Stack 栈也是一种线性的数据结构 相比数组,栈相对应的操作是数组的子集. 只能从一端添加元素,也只能从一端取出元素.这一端成为栈顶. 1,2,3依次入栈得到的顺序为 3,2,1,栈顶为3, ...
- Codeforces 1082B Vova and Trophies(前缀+后缀)
题目链接:Vova and Trophies 题意:给定长度为n的字符串s,字符串中只有G和S,只允许最多一次操作:任意位置的两个字符互换.求连续G的最长长度. 题解:维护pre和pr,nxt和nx. ...
- LoadRunner【第四篇】参数化
参数化的定义及使用场景 定义:将脚本中的特定值用变量替代,该变量值是变化的(注意:这个值是我们自己创建的,不是服务器返回的). 使用参数化: 1.业务考虑,不允许相同信息 2.真实模拟不同用户 3.真 ...