python数据分析算法(决策树2)CART算法
CART(Classification And Regression Tree),分类回归树,,决策树可以分为ID3算法,C4.5算法,和CART算法。ID3算法,C4.5算法可以生成二叉树或者多叉树,CART只支持二叉树,既可支持分类树,又可以作为回归树。
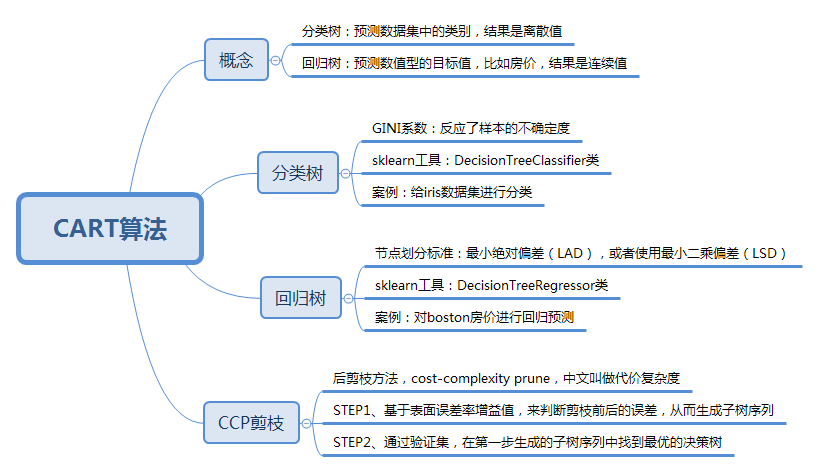
分类树: 基于数据判断某物或者某人的某种属性(个人理解)可以处理离散数据,就是有限的数据,输出样本的类别
回归树: 给定了数据,预测具体事物的某个值;可以对连续型的数据进行预测,也就是数据在某个区间内都有取值的可能,它输出的是一个数值
CART 分类树的工作流程
CART和C4.5算法类似,知识属性选择的指标采用的是基尼系数,基尼系数本身反应了样本的不确定度,当基尼系数越小的时候,说明样本之间的差异性小,不确定度低。分类的过程是一个不确定度降低的过程,即纯度提升的过程,所以构造分类树的时候会基于基尼系数最小的属性作为划分。
了解基尼系数:
假设t为节点,那么该节点的GINI系数的计算公式为:
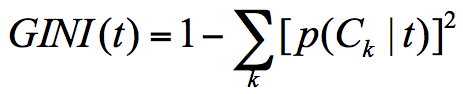
p(Ck|t) 表示t属性类别Ck的概率,节点t的基尼系数为1减去各个分类Ck概率平方和
例如集合1: 6个人去游泳, 那么p(Ck|t)=1,因此 GINI(t) = 1-1 =0
集合2 : 3个人去游泳,3个人不去,那么p(C1k|t) = 0.5 ,p(C2k|t) = 0.5
得出,集合1样本基尼系数最小,样本最稳定,2的样本不稳定性大

该公式表示节点D的基尼系数等于子节点D1,D2的归一化基尼系数之和
使用CART算法创建分类树
iris是sklearn 自带IRIS(鸢尾花)数据集sklearn中的来对特征处理功能进行说明包含4个特征(Sepal.Length(花萼长度)、Sepal.Width(花萼宽度)、Petal.Length(花瓣长度)、Petal.Width(花瓣宽度)),特征值都为正浮点数,单位为厘米
目标值为鸢尾花的分类(Iris Setosa(山鸢尾)、Iris Versicolour(杂色鸢尾),Iris Virginica(维吉尼亚鸢尾))
1 # encoding=utf-8
from sklearn.model_selection import train_test_split
from sklearn.metrics import accuracy_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.datasets import load_iris
# 准备数据集
iris=load_iris()
# 获取特征集和分类标识
features = iris.data
labels = iris.target
# 随机抽取 33% 的数据作为测试集,其余为训练集 使用sklearn.model_selection train_test_split 训练
train_features, test_features, train_labels, test_labels = train_test_split(features, labels, test_size=0.33, random_state=0)
# 创建 CART 分类树
clf = DecisionTreeClassifier(criterion='gini')
# 拟合构造 CART 分类树
clf = clf.fit(train_features, train_labels)
# 用 CART 分类树做预测 得到预测结果
test_predict = clf.predict(test_features)
# 预测结果与测试集结果作比对
score = accuracy_score(test_labels, test_predict)
print("CART 分类树准确率 %.4lf" % score)
CART 分类树准确率 0.9600
train_test_split 可以把数据集抽取一部分作为测试集,就可以德奥训练集和测试集
14 初始化一棵cart树,16 训练集的特征值和分类表示作为参数进行拟合得到cart分类树
cart回归树的工作流程
cart回归树划分数据集的过程和分类树的过程是一样的,回归树得到的预测结果是连续值,评判不纯度的指标不同,分类树采用的是基尼系数,回归树需要根据样本的离散程度来评价 不纯度
样本离散程度计算方式,每个样本值到均值的差值,可以去差值的绝对值,或者方差
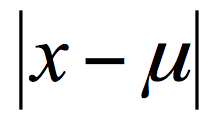
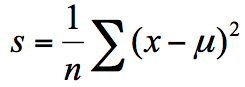 方差为每个样本值减去样本均值的平方和除以样本可数
方差为每个样本值减去样本均值的平方和除以样本可数
最小绝对偏差(LAD) 最小二乘偏差
如何使用CART回归树做预测
这里使用sklearn字典的博士度房价数据集,该数据集给出了影响房价的一些指标,比如犯罪了房产税等,最后给出了房价
# encoding=utf-8
from sklearn.metrics import mean_squared_error
from sklearn.model_selection import train_test_split
from sklearn.datasets import load_boston
from sklearn.metrics import r2_score,mean_absolute_error,mean_squared_error
from sklearn.tree import DecisionTreeRegressor
# 准备数据集
boston=load_boston()
# 探索数据
print(boston.feature_names)
# 获取特征集和房价
features = boston.data
prices = boston.target
# 随机抽取 33% 的数据作为测试集,其余为训练集
train_features, test_features, train_price, test_price = train_test_split(features, prices, test_size=0.33)
# 创建 CART 回归树
dtr=DecisionTreeRegressor()
# 拟合构造 CART 回归树
dtr.fit(train_features, train_price)
# 预测测试集中的房价
predict_price = dtr.predict(test_features)
# 测试集的结果评价
print('回归树二乘偏差均值:', mean_squared_error(test_price, predict_price))
print('回归树绝对值偏差均值:', mean_absolute_error(test_price, predict_price))
['CRIM' 'ZN' 'INDUS' 'CHAS' 'NOX' 'RM' 'AGE' 'DIS' 'RAD' 'TAX' 'PTRATIO'
'B' 'LSTAT']
回归树二乘偏差均值: 32.065568862275455
回归树绝对值偏差均值 3.2892215568862277
cart决策树的剪枝
cart决策树剪枝采用的是CCP方法,一种后剪枝的方法,cost-complexity prune 中文:代价复杂度,这种剪枝用到一个指标 叫做 节点的表面误差率增益值,以此作为剪枝前后误差的定义
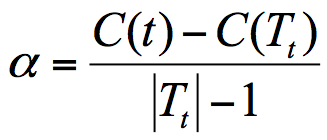 Tt 代表以t为根节点的子树,C(Tt)表示节点t的子树没被裁剪时子树Tt的误差,C(t)表示节点t的子树被剪枝后节点t的误差,|Tt|代子树Tt的叶子树,剪枝后,T的叶子树减一
Tt 代表以t为根节点的子树,C(Tt)表示节点t的子树没被裁剪时子树Tt的误差,C(t)表示节点t的子树被剪枝后节点t的误差,|Tt|代子树Tt的叶子树,剪枝后,T的叶子树减一
所以节点的表面误差率增益值 等于 节点t的子树被剪枝后的误差变化除以 减掉的叶子数量
因此希望剪枝前后误差最小,所以我们要寻找就是最小α值对应的节点,把它减掉。生成第一个子树,重复上面过程继续剪枝,知直到最后为根节点,即为最后一个子树
得到剪枝后的子树集合后,我们需要采用验证集对所有子树的误差计算一遍,可以计算每个子树的基尼指数或平房误差,去最小的那棵树
python数据分析算法(决策树2)CART算法的更多相关文章
- 决策树2 -- CART算法
声明: 1,本篇为个人对<2012.李航.统计学习方法.pdf>的学习总结.不得用作商用,欢迎转载,但请注明出处(即:本帖地址). 2,因为本人在学习初始时有非常多数学知识都已忘记.所以为 ...
- 决策树之CART算法
顾名思义,CART算法(classification and regression tree)分类和回归算法,是一种应用广泛的决策树学习方法,既然是一种决策树学习方法,必然也满足决策树的几大步骤,即: ...
- 《机器学习实战》学习笔记第九章 —— 决策树之CART算法
相关博文: <机器学习实战>学习笔记第三章 —— 决策树 主要内容: 一.CART算法简介 二.分类树 三.回归树 四.构建回归树 五.回归树的剪枝 六.模型树 七.树回归与标准回归的比较 ...
- 简单易学的机器学习算法——决策树之ID3算法
一.决策树分类算法概述 决策树算法是从数据的属性(或者特征)出发,以属性作为基础,划分不同的类.例如对于如下数据集 (数据集) 其中,第一列和第二列为属性(特征),最后一列为类别标签,1表示是 ...
- 02-23 决策树CART算法
目录 决策树CART算法 一.决策树CART算法学习目标 二.决策树CART算法详解 2.1 基尼指数和熵 2.2 CART算法对连续值特征的处理 2.3 CART算法对离散值特征的处理 2.4 CA ...
- 机器学习——十大数据挖掘之一的决策树CART算法
本文始发于个人公众号:TechFlow,原创不易,求个关注 今天是机器学习专题的第23篇文章,我们今天分享的内容是十大数据挖掘算法之一的CART算法. CART算法全称是Classification ...
- 决策树-预测隐形眼镜类型 (ID3算法,C4.5算法,CART算法,GINI指数,剪枝,随机森林)
1. 1.问题的引入 2.一个实例 3.基本概念 4.ID3 5.C4.5 6.CART 7.随机森林 2. 我们应该设计什么的算法,使得计算机对贷款申请人员的申请信息自动进行分类,以决定能否贷款? ...
- 决策树模型 ID3/C4.5/CART算法比较
决策树模型在监督学习中非常常见,可用于分类(二分类.多分类)和回归.虽然将多棵弱决策树的Bagging.Random Forest.Boosting等tree ensembel 模型更为常见,但是“完 ...
- 机器学习技法-决策树和CART分类回归树构建算法
课程地址:https://class.coursera.org/ntumltwo-002/lecture 重要!重要!重要~ 一.决策树(Decision Tree).口袋(Bagging),自适应增 ...
随机推荐
- 更改Ubuntu默认python版本的方法
当你安装 Debian Linux 时,安装过程有可能同时为你提供多个可用的 Python 版本,因此系统中会存在多个 Python 的可执行二进制文件.一般Ubuntu默认的Python版本都为2. ...
- LuoGu P4996 咕咕咕
题目描述 小 F 是一个能鸽善鹉的同学,他经常把事情拖到最后一天才去做,导致他的某些日子总是非常匆忙. 比如,时间回溯到了 2018 年 11 月 3 日.小 F 望着自己的任务清单: 看 iG 夺冠 ...
- IISARR方式整合Tomcat失敗
需要在IIS安裝ARR 目标服务器:targetServer 配置反向代理的服务器:reveseProxServer 1.确定最终访问的网址:比如www.baidu.com .www.csdn.ne ...
- Concept of function continuity in topology
Understanding of continuity definition in topology When we learn calculus in university as freshmen, ...
- MySQL通过Navicat实现远程连接的过程
直接使用Navicat通过IP连接会报各种错误,例如:Error 1130: Host '192.168.1.80' is not allowed to connect to this MySQL ...
- 使用Redis构建全局并发锁
谈起Redis的用途,小伙伴们都会说使用它作为缓存,目前很多公司都用Redis作为缓存,但是使用Redis仅仅作为缓存未免太大材小用了.深究Redis的原理后你会发现它有很多用途,在很多场景下能够使用 ...
- python基础篇_006_面向对象
面向对象 1.初识类: # 定义一个函数,我们使用关键字 def """ def 函数名(参数): '''函数说明''' 函数体 return 返回值 "&qu ...
- SQLServer 2014 内存优化表
内存优化表是 SQLServer 2014 的新功能,它是可以将表放在内存中,这会明显提升DML性能.关于内存优化表,更多可参考两位大侠的文章:SQL Server 2014新特性探秘(1)-内存数据 ...
- Fragment基础操作
Fragment和Activity类似,同样是具备UI的属性:也就是都能用于规划UI布局... Building a Dynamic UI with Fragments --> Fragment ...
- [POJ1723]SOLDIERS(中位数)
题意 给出n个点的坐标,它们只能往上.下.左.右一格一格地移动,求使其移动至水平线上的最小步数. 思路 转载 先易后难,对于纵向的问题,我们推个公式,,这个很容易看出是货仓选址问题,k取y[i]的中位 ...