python模块shutil
shutil 模块简单使用
shutil.copyfileobj(fsrc, fdst,[ length]):拷贝文件句柄,将类文件对象fsrc的内容复制到类文件对象fdst。如果给定整数长度,则为缓冲区大小。如果长度是负值意味着复制数据时不需要以块的形式对源数据进行循环,默认情况下,数据是块读取的,以避免不受控制的内存消耗。注意,如果fsrc对象的当前文件位置不是0,那么只复制从当前文件位置到文件末尾的内容。
如下,拷贝文件操作:
import shutil
with open("test.txt",mode="r",encoding="utf-8") as f1, \
open("abc",mode="a",encoding="utf-8") as f2:
shutil.copyfileobj(f1,f2) # 拷贝文件句柄
拷贝后的数据如下图所示:

shutil.copyfile(src, dst, *, follow_symlinks=True)
src:源文件。
dst:目标文件
*:模式不用管编码方式默认是utf-8
仅拷贝状态的信息,包括:mode bits, atime, mtime, flags
如果follow_symlinks为false, src是一个符号链接(快捷方式),那么将创建一个新的符号链接(快捷方式),而不是复制src指向的文件。
文件拷贝,操作如下:
import shutil
shutil.copyfile("test.txt","abc")
拷贝后如下图所示:

shutil.copymode(src, dst, *, follow_symlinks=True):将src权限复制到dst。文件内容、所有者和组不受影响。如果follow_symlinks为假,并且src和dst都是符号链接,copymode()将尝试修改dst本身的模式(而不是它指向的文件)。此功能并非在每个平台上都可用;有关更多信息,请参见copystat()。如果copymode()不能修改本地平台上的符号链接,并且被要求这样做,那么它将什么也不做并返回。
shutil.copystat(src, dst, *, follow_symlinks=True):将src文件状态拷贝到dst,dst文件必须存在。如上次访问时间、上次修改时间和标志从src复制到dst。在Linux上,copystat()也尽可能地复制“扩展属性”。文件内容、所有者和组不受影响。
如果follow_symlinks为假,并且src和dst都引用符号链接,copystat()将对符号链接本身进行操作,而不是对符号链接引用的文件进行操作,从src符号链接读取信息,并将信息写入dst符号链接。
shutil.copy(src, dst, *, follow_symlinks=True):将文件src复制到文件或目录dst。如果dst指定一个目录,该文件将使用来自src的文件名复制到dst文件夹中,如果dst是文件名将src文件内容复制一份到dst文件中。
拷贝文件test.txt内容到abc中,拷贝test.txt到一个目录下。
import shutil
shutil.copy("test.txt","abc")
shutil.copy("test.txt",r"I:\python_work\test")
拷贝后的内容如下:

shutil.copy2(src, dst, *, follow_symlinks=True):功能与copy相同,但可以试图保存目标文件的原数据,(实验没成功,拷贝后会覆盖原有数据)。
shutil.copytree(src, dst, symlinks=False, ignore=None, copy_function=copy2, ignore_dangling_symlinks=False):递归复制位于src的整个目录树,返回目标目录。由dst命名的目标目录必须不存在,它将被当做父目录。
import shutil
shutil.copytree("a","z")
如下图示拷贝后的数据:
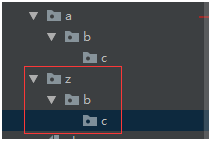
shutil.rmtree(path, ignore_errors=False, onerror=None):递归的删除目录,一定要注意在删除时,无论目录是空目录还是有文件的目录,都会不提示的删除,而且删除的数据不经过回收站,无法恢复,所以慎用。
import shutil
shutil.rmtree("z")
shutil.move(src, dst, copy_function=copy2):相当于剪切,如果在同目录下就相当于重命名的操作。
如下面相当于重命名操作,剪切也类似就不演示了。
import shutil
shutil.move("abc","abc.txt")
shutil.disk_usage(path):以命名元组的形式返回给定路径的磁盘使用情况统计信息,属性为total、used和free,即总空间、已用空间和可用空间量(以字节为单位)。在Windows上,路径必须是目录;在UNIX上,路径可以是文件或目录。
import shutil
ret = shutil.disk_usage(r"I:\python_work")
print(ret) # 打印字节形式 # 打印GB形式的
print("total:",int(ret[0] / (1024 ** 3)),"GB")
print("used:",int(ret[1] / (1024 ** 3)),"GB")
print("free",int(ret[2] / (1024 ** 3)),"GB")
内容如下:

shutil.chown(path, user=None, group=None):更改文件用户的所有者和用户组。
shutil.which(cmd, mode=os.F_OK | os.X_OK, path=None):返回可以行文件的路径,如下所示:
import shutil
print(shutil.which("cmd")) # 打印内容如下
C:\Windows\system32\cmd.EXE
shutil.make_archive(base_name, format, root_dir=None, base_dir=None, verbose=0,dry_run=0, owner=None, group=None, logger=None):
创建压缩包并返回文件路径,例如:zip、tar。
base_name: 要创建的文件名,如果有路径则将文件保存到路径下,如果没有路径则保存到当前目录下,件名是没有扩展名的。
format:压缩包种类,“zip”, “tar”, “bztar”,“gztar”
root_dir:要被打包的文件路径
base_dir:被打包文件的路径,优先级高于root_dir
owner:用户,默认当前用户
group:组,默认当前组
logger:用于记录日志,通常是logging.Logger对象
如下:
import shutil
shutil.make_archive(base_name=r"I:\test\python_work_zip",
format="zip", root_dir=r"I:\test")
打包后的内容如下:
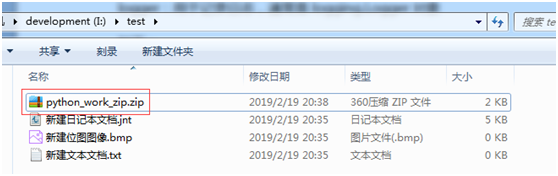
shutil 对压缩包的处理是调用 ZipFile 和 TarFile 两个模块来进行的
zipfile模块
压缩文件:
import zipfile
z = zipfile.ZipFile('test.zip', 'w') # 压缩后的文件名
z.write('test') # 要被压缩的文件
z.close() # 关闭zip对象
压缩后的内容如下:
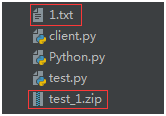
解压文件:
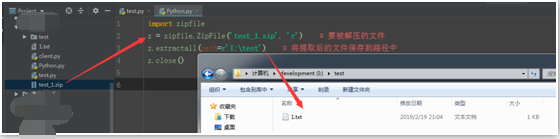
import zipfile
z = zipfile.ZipFile('test_1.zip', 'r') # 要被解压的文件
z.extractall(path=r'I:\test') # 将提取后的文件保存到路径中
z.close()
解压后的文件如下:
tarfile压缩:
import tarfile
t=tarfile.open('test.tar','w') # 压缩后的名字
t.add('test',arcname='a.bak') # 要压缩的文件和压缩后将被压缩文件改名为a.bak
t.close()
压缩后的文件内容如下:
解压:
import tarfile
t=tarfile.open('test.tar','r') # 要被解压的包
t.extractall(path=r"I:\test") # 解压后保存的路径
t.close()
解压后内容如下:

下一篇:re正则表达式:https://www.cnblogs.com/caesar-id/p/10467396.html
python模块shutil的更多相关文章
- python模块------shutil
说明 shutil -- High-level file operations 是一种高层次的文件操作工具 类似于高级API,而且主要强大之处在于其对文件的复制与删除操作更是比较支持好. copy() ...
- python(6)-shutil模块
高级的 文件.文件夹.压缩包 处理模块 shutil.copyfileobj(fsrc, fdst[, length]) 将文件内容拷贝到另一个文件中: #源码 def copyfileobj(fsr ...
- Python 第五篇(下):系统标准模块(shutil、logging、shelve、configparser、subprocess、xml、yaml、自定义模块)
目录: shutil logging模块 shelve configparser subprocess xml处理 yaml处理 自定义模块 一,系统标准模块: 1.shutil:是一种高层次的文件操 ...
- python模块之os sys shutil
os模块 os模块是与操作系统交互的一个接口 #当前执行这个python文件的工作目录相关的工作路径 os.getcwd() 获取当前工作目录,即当前python脚本工作的目录路径 os.chdir( ...
- python基础--shutil模块
shutil模块提供了大量的文件的高级操作. 特别针对文件拷贝和删除,主要功能为目录和文件操作以及压缩操作.对单个文件的操作也可参见os模块. 注意 即便是更高级别的文件复制函数(shutil.cop ...
- Python模块:shutil、序列化(json&pickle&shelve)、xml
shutil模块: 高级的 文件.文件夹.压缩包 处理模块 shutil.copyfileobj(fscr,fdst [, length]) # 将文件内容拷贝到另一个文件中 import shu ...
- python day 9: xlm模块,configparser模块,shutil模块,subprocess模块,logging模块,迭代器与生成器,反射
目录 python day 9 1. xml模块 1.1 初识xml 1.2 遍历xml文档的指定节点 1.3 通过python手工创建xml文档 1.4 创建节点的两种方式 1.5 总结 2. co ...
- python笔记7 logging模块 hashlib模块 异常处理 datetime模块 shutil模块 xml模块(了解)
logging模块 日志就是记录一些信息,方便查询或者辅助开发 记录文件,显示屏幕 低配日志, 只能写入文件或者屏幕输出 屏幕输出 import logging logging.debug('调试模式 ...
- Python 文件操作模块 shutil 详解
1.导入模块 shutil import shutil 2.shutil方法 2.1 shutil.copy(src,dst) //将 src 复制到 dst 保留文件权限 例:将Alan复制到 ...
随机推荐
- server.properties 文件详解
[转载]:server.properties 文件详解 # 每一个Broker在集群中的唯标识.即使Broker的IP地址发生了变化,broker.id只要没变,则不会影响consumers的消息情况 ...
- Java面向对象特征之封装
package practice;/** * @功能 创建动物类,对动物的属性进行封装 * @author square 凉 * */public class Animal { /** * 动物姓名 ...
- Mysql的两种偏移量分页写法
当一个查询语句偏移量offset很大的时候,如select * from table limit 10000,10 , 先获取到offset的id后,再直接使用limit size来获取数据,效率会有 ...
- 侯哥的Python分享
侯哥语录 我曾经是一个职业教育者,现在是一个自由开发者.我希望我的分享可以和更多人一起进步.分享一段我喜欢的话给大家:"我所理解的自由不是想干什么就干什么,而是想不干什么就不干什么.当你还没 ...
- Integer简介
// 当创建范围为[-128,127]时 Integer a = ; Integer b = ; Integer c = ); System.out.println("a == b :&qu ...
- [Abp 源码分析]十二、多租户体系与权限验证
0.简介 承接上篇文章我们会在这篇文章详细解说一下 Abp 是如何结合 IPermissionChecker 与 IFeatureChecker 来实现一个完整的多租户系统的权限校验的. 1.多租户的 ...
- Vuex的模块化、优点
前言:如果说我们的vuex的仓库代码量巨大,我们要不要采用就像后端与一样的分层,要不然一吨的代码放在main里,呵呵.所以我们要采用模块化! 看这篇文章的时候,一定要看看上一篇的vuex入门精讲:Vu ...
- Solr 08 - 在Solr Web管理页面中查询索引数据 (Solr中各类查询参数的使用方法)
目录 1 Solr管理页面的查询入口 2 Solr查询输入框简介 3 Solr管理页面的查询方案 1 Solr管理页面的查询入口 选中需要查询的SolrCore, 然后在菜单栏选择[Query]: 2 ...
- iterm2 快捷键(转载)
Mac 下 iterm2 的快捷键,转自:https://github.com/sumiaowen/iterm2-shortcuts iterm2-shortcuts(iterm 2 快捷键) 标签 ...
- 理解和使用Promise.all和Promise.race
一.Pomise.all的使用 Promise.all可以将多个Promise实例包装成一个新的Promise实例.同时,成功和失败的返回值是不同的,成功的时候返回的是一个结果数组,而失败的时候则返回 ...