细说java系列之HashMap原理

目录
类图
在正式分析HashMap实现原理之前,先来看看其类图。

源码解读
下面集合HashMap的put(K key, V value)方法探究其实现原理。
// 在HashMap内部用于存放插入数据的是一个名为"table"的一维Node对象数组
// Node对象为实际存放插入数据Key和Value的数据结构
transient Node<K,V>[] table;
// 外部调用插入数据的接口方法
public V put(K key, V value) {
return putVal(hash(key), key, value, false, true);
}
// 内部真正执行数据插入的方法
final V putVal(int hash, K key, V value, boolean onlyIfAbsent,
boolean evict) {
Node<K,V>[] tab; Node<K,V> p; int n, i;
if ((tab = table) == null || (n = tab.length) == 0)
// 第一次插入数据时,初始化table数组
n = (tab = resize()).length;
if ((p = tab[i = (n - 1) & hash]) == null)
// 变量n为HashMap当前容量大小,实际上就是table数组的容量大小
// 将(n-1)与插入数据Key的hashcode值进行逻辑与运算,找到一个随机位置i
// 如果table[i]值为null,说明该位置还没有存放数据,新建一个Node对象并存放在table[i],本次插入完毕,返回null值
tab[i] = newNode(hash, key, value, null);
else {
// 如果table[i]值不为null,说明该位置已经存放了数据,继续寻找插入数据的位置
Node<K,V> e; K k;
if (p.hash == hash &&
((k = p.key) == key || (key != null && key.equals(k))))
// 如果新插入数据Key的hashcode值与table[i]位置存放对象Key的hascode值相同
// 并且新插入数据Key与table[i]位置存放对象的Key引用的是同一个对象或者它们相等(通过equals方法比较)
// 则使用新插入数据的Value替换table[i]位置存放对象的Value,本次插入完毕,返回之前存放在该位置对象的Value值
e = p;
else if (p instanceof TreeNode)
// 如果table[i]位置存放对象属于TreeNode类型,进行特别处理
// 为什么需要判断是否为TreeNode类型?
e = ((TreeNode<K,V>)p).putTreeVal(this, tab, hash, key, value);
else {
// 如果新插入数据Key不与table[i]位置存放对象Key相同,那么寻找一个满足如下条件的位置,将新数据插入到对应位置
// 条件1:如果table[i]位置对象的next属性为null,直接通过该next属性引用插入数据新建的Node对象,并返回null
// 条件2:如果table[i]位置对象的next属性不为null,那么就在该位置对象链表上寻找一个插入新数据的位置,在这个过程中根据如下满足条件进行处理
// 条件3:如果插入数据的Key与链表上的某个Node对象的Key相同,那么使用新插入的Value替换该Node对象的Value,并返回该Node之前的Value值
// 如果不满足上诉3个条件,将插入数据保存在table[i]位置对象链表的末端,并返回null
// 总结:HashMap存放实际数据的是一个一维数组,而每一个数组元素又支持链表结构
for (int binCount = 0; ; ++binCount) {
if ((e = p.next) == null) {
p.next = newNode(hash, key, value, null);
if (binCount >= TREEIFY_THRESHOLD - 1) // -1 for 1st
treeifyBin(tab, hash);
break;
}
if (e.hash == hash &&
((k = e.key) == key || (key != null && key.equals(k))))
break;
p = e;
}
}
if (e != null) { // existing mapping for key
V oldValue = e.value;
if (!onlyIfAbsent || oldValue == null)
e.value = value;
afterNodeAccess(e);
return oldValue;
}
}
++modCount;
if (++size > threshold)
resize();
afterNodeInsertion(evict);
return null;
}
将上述HashMap实现插入数据的过程以插入4个数据为示例描述如下:
1.插入第一个数据时,初始化HashMap内部名为“table”的一维数组,默认大小为16,每一个数组元素值为null。
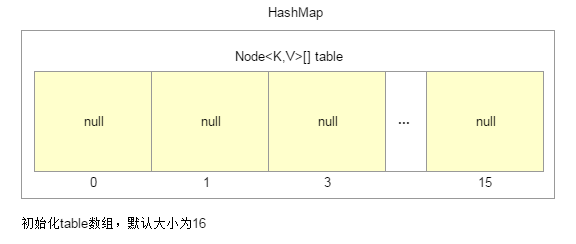
寻找一个插入数据的位置i,这在HashMap中的实现非常巧妙,这个插入位置通过如下表达式计算得到:i = (n - 1) & hash。其中,n为当前HashMap的容量,其实就是内部table数组的大小,hash为插入数据Key的hashCode值。通过该表达式将会随机找个一个插入位置i,i的值范围为[0,n-1]。必须注意的是: 插入位置是随机的!并不是按照一维数组的顺序插入方式,这是因为HashMap这个数据结构的特点所决定的。因为是插入第一个数据,所以随机找到的位置“i=3”处对象为null值,因此直接在该位置处插入一个Node对象。本次插入操作完毕,返回null值。
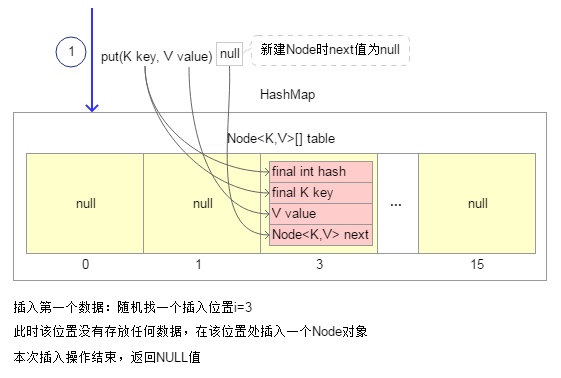
2.插入第二个数据时,先随机找到一个插入位置“i=1”,而且该位置处的对象为null值,说明还没有存放任何数据,直接在该位置处插入一个Node对象。本次插入操作完毕,返回null值。
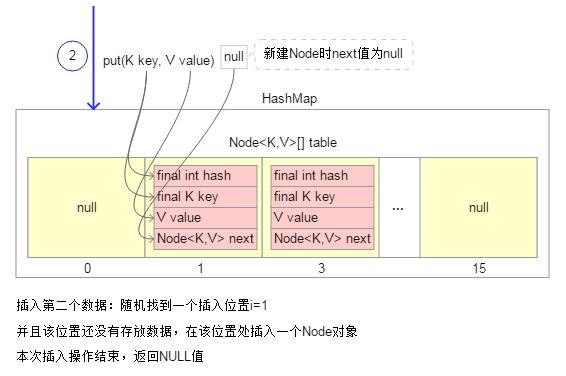
3.插入第三个数据时,随机找到插入位置“i=1”,该位置上已经存放了数据;并且插入数据的Key不与该位置Node对象的Key相同(Key相同的条件时:首先必须hashCode值相同,并且他们引用的是同一个对象或者他们通过equals()方法比较时相等),此时需要将新插入数据保存到该位置Node对象的next属性中(看起来像是链接到该位置Node对象的尾部)。本次插入操作完毕,返回null值。
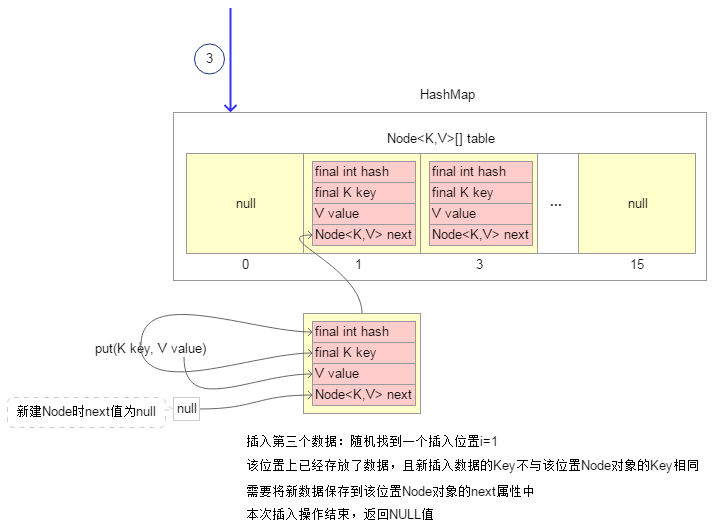
4.插入第四个数据时,随机找到插入位置“i=1”,该位置上已经存放了数据;并且插入数据的Key与该位置Node对象的Key相同,此时使用新插入数据的Value替换该位置Node对象当前的Value值。本次插入操作完毕,返回该位置Node对象之前的Value值。
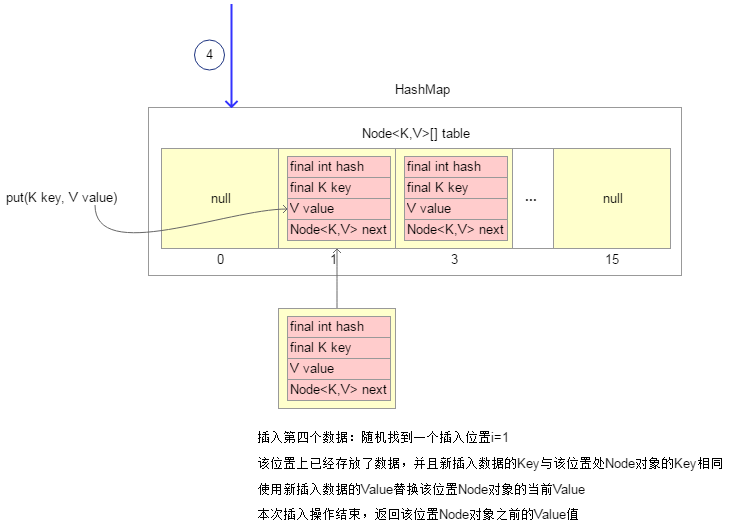
上述示例描述的就是HashMap插入数据的原理,实际上除了上述描述的核心操作之外,在返回值之前需要判断HashMap当前的容量是否能够存储更多插入的数据,根据判断之后可能会进行扩容,如下代码所示:
if (++size > threshold)
resize();
总结
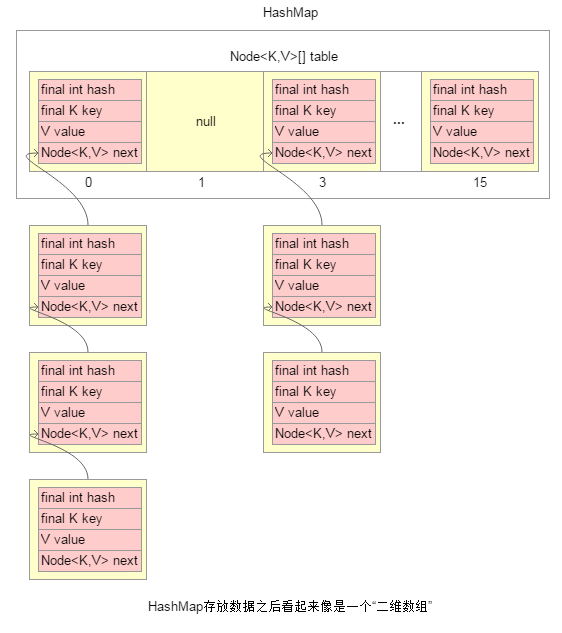
1.先明确一个事实,HashMap内部实际存放数据的是一个一维数组,但是存储的元素类型支持链表结构。所以,存放数据之后的HashMap看起来像是一个“二维数组”(注意: 并不是真正的二维数组)。
2.判断HashMap存放对象Key是否相同,方法如下:
- 新插入Key的hashCode值必须与已经存在对象Key的hashCode值相等,这是前提
- 新插入Key与已存在对象Key引用的是同一个对象,或者他们通过equals()方法比较时相等
3.HashMap内部名为“table”的一维数组可能存在“存不满”数据的情况,因为插入数据的位置是通过表达式i = (n - 1) & hash计算的,可以认为这是一个随机的值。
4.最后,还是需要老生常谈地强调一下,HashMap不是线程安全的,其内部用于存放数据的容器本质上是一个一维数组,该数组本身并不是线程安全的,而且HashMap在写操作时也并未进行线程同步。如果需要使用线程安全的HashMap,应该使用ConcurrentHashMap,因为在其中用于存储数据的数组是线程安全的:
/**
* The array of bins. Lazily initialized upon first insertion.
* Size is always a power of two. Accessed directly by iterators.
*/
// ConcurrentHashMap内部存储数据的table通过关键字volatile修饰,因此是线程安全的
transient volatile Node<K,V>[] table;
细说java系列之HashMap原理的更多相关文章
- 【Java基础】HashMap原理详解
哈希表(hash table) 也叫散列表,是一种非常重要的数据结构,应用场景及其丰富,许多缓存技术(比如memcached)的核心其实就是在内存中维护一张大的哈希表,本文会对java集合框架中Has ...
- 细说java系列之泛型
什么是范型 简言之,范型是Java支持在编译期进行类型检查的机制. 这里面包含2层含义:其一,可以使用范型进行类型检查:其二,在编译期进行类型检查. 那么,什么叫做在编译期进行类型检查?可以在运行时进 ...
- 细说java系列之反射
什么是反射 反射机制允许在Java代码中获取被JVM加载的类信息,如:成员变量,方法,构造函数等. 在Java包java.lang.reflect下提供了获取类和对象反射信息的相关工具类和接口,如:F ...
- 细说java系列之注解
写在前面 Java从1.5版本之后开始支持注解,通过注解可以很方便地实现某些功能,使用得最普遍的就是Spring框架的注解,大大简化了Bean的配置. 注解仅仅是一种Java提供的工具,并不是一种编程 ...
- Java基础之HashMap原理分析(put、get、resize)
在分析HashMap之前,先看下图,理解一下HashMap的结构 我手画了一个图,简单描述一下HashMap的结构,数组+链表构成一个HashMap,当我们调用put方法的时候增加一个新的 key-v ...
- java基础解析系列(七)---ThreadLocal原理分析
java基础解析系列(七)---ThreadLocal原理分析 目录 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)-- ...
- java基础解析系列(六)---注解原理及使用
java基础解析系列(六)---注解原理及使用 java基础解析系列(一)---String.StringBuffer.StringBuilder java基础解析系列(二)---Integer缓存及 ...
- java数据结构之hashMap
初学JAVA的时候,就记得有句话两个对象的hashCode相同,不一定equal,但是两个对象equal,hashCode一定相同,当时一直不理解是什么意思,最近在极客时间上学习了课程<数据结构 ...
- Java 集合系列 09 HashMap详细介绍(源码解析)和使用示例
java 集合系列目录: Java 集合系列 01 总体框架 Java 集合系列 02 Collection架构 Java 集合系列 03 ArrayList详细介绍(源码解析)和使用示例 Java ...
随机推荐
- ftp配置详解
FTP配置文件位置/etc/vsftpd.conflisten=NO设置为YES时vsftpd以独立运行方式启动,设置为NO时以xinetd方式启动(xinetd是管理守护进程的,将服务集中管理,可以 ...
- selenium跳过webdriver检测并模拟登录淘宝
目录 简介 编写思路 使用教程 演示图片 源代码 @(文章目录) 简介 模拟登录淘宝已经不是一件新鲜的事情了,过去我曾经使用get/post方式进行爬虫,同时也加入IP代理池进行跳过检验,但随着大型网 ...
- selenium3(java)之屏幕截图操作
selenium提供了截图的功能,分别是接口是TakesScreenshot和类RemoteWebDriver.该功能是在运行测试用例的过程中,需要验证某个元素的状态或者显示的数值时,可以将屏幕截取下 ...
- Python----逻辑回归
逻辑回归 1.逻辑函数 sigmoid函数就出现了.这个函数的定义如下: sigmoid函数具有我们需要的一切优美特性,其定义域在全体实数,值域在[0, 1]之间,并且在0点值为0.5. 那么,如何将 ...
- [转] package-lock.json
其实用一句话来概括很简单,就是锁定安装时的包的版本号,并且需要上传到git,以保证其他人在npm install时大家的依赖能保证一致. 引用知乎@周载南的回答 根据官方文档,这个package-lo ...
- centos7重置root密码
修改centos7的root密码重置非常简单,只需要登录系统,执行passwd按enter即可, 但是如果忘记root密码,该如何修改呢 1, 重启系统之后,系统启动进入欢迎界面,加载内核步骤时,选中 ...
- Linux(Ubuntu)使用日记------trash-cli防止误删文件
1.安装过程 cd /tmp git clone https://github.com/andreafrancia/trash-cli cd trash-cli sudo python setup.p ...
- 时间通用类 datetime
/// <summary> /// 时间通用类 /// </summary> public class DateTimeGeneral { /// <summary> ...
- Vue.js 2.x笔记:安装与起步(1)
1. 环境准备 Vue是一套用于构建用户界面的渐进式框架,设计为可以自底向上逐层应用.Vue 的核心库只关注视图层. 安装Node.js,下载:https://nodejs.org/ 查看安装: $ ...
- Alan Turing的纪录片观后感
清明假期,火车上闲着,上B站看了图灵的纪录片 好吧,感想就两个词,数字化 和 自动化