Python——LOL官方商城皮肤信息爬取(一次练手)
# -*- coding utf-8 -*-
import urllib
import urllib.request
import json
import time
import xlsxwriter
from asyncio.tasks import sleep
import re # 根据第一页数据创建信息表头
header = []
url = "http://apps.game.qq.com/daoju/v3/api/hx/goods/api/list/v54/GoodsListApp.php?view=biz_cate&page=1&pageSize=8&orderby=dtShowBegin&ordertype=desc&cate=17&appSource=pc&appSourceDetail=pc_lol_revison&channel=1001&storagetype=6501&plat=0&output_format=jsonp&biz=lol"
data = json.loads(urllib.request.urlopen(url).read().decode("gbk").replace("var ogoods_list_api = ","").replace("\n",""))
goods_info = data["data"]["goods"][0]["valiDate"][0]
for i in range(len(goods_info)):
header.append(''.join((re.findall("\w",str(str(goods_info).split(",")[i]).split(":")[0]))).strip()) # 创建工作簿,写表头
workbook = xlsxwriter.Workbook("E:/lol_sales.xlsx")
sheet = workbook.add_worksheet("result")
for i in range(len(header)):
sheet.write(0,i,header[i]) # 获取数据
row_index = 1
for page_index in range(1,61):
url = "http://apps.game.qq.com/daoju/v3/api/hx/goods/api/list/v54/GoodsListApp.php?view=biz_cate&page=" + str(page_index) + "&pageSize=8&orderby=dtShowBegin&ordertype=desc&cate=17&appSource=pc&appSourceDetail=pc_lol_revison&channel=1001&storagetype=6501&plat=0&output_format=jsonp&biz=lol"
data = json.loads(urllib.request.urlopen(url).read().decode("gbk").replace("var ogoods_list_api = ","").replace("\n",""))
for goods_index in range(6):
try:
for col_index in range(len(header)):
if header[col_index] == "award":
pass
else:
sheet.write(row_index,col_index,data["data"]["goods"][goods_index]["valiDate"][0][header[col_index]])
row_index += 1
except:
pass
print("page" + str(page_index))
workbook.close()
print("finish")
获取的数据内容如下:
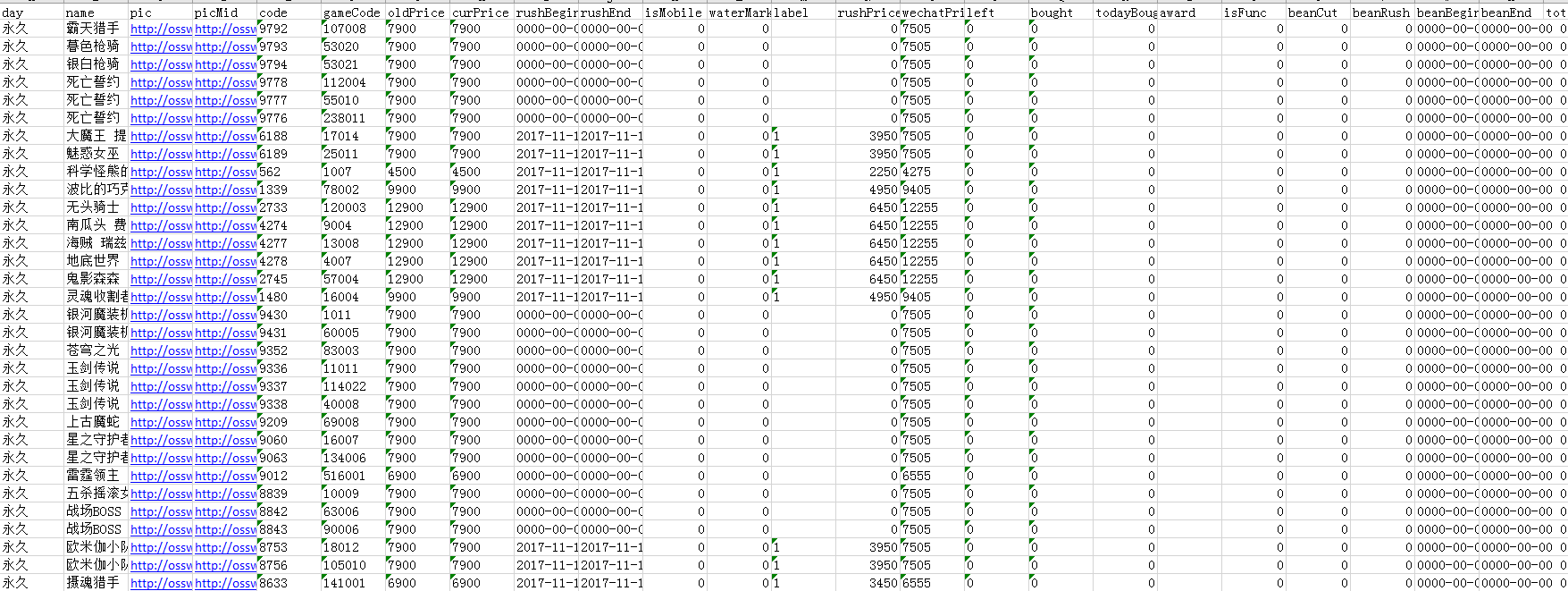
总结:
1.表头的获取方式。
不要再自己编写表头啦,一是太费事,二是不灵活。
通过创建空的列表,读取示范页面(如第一页)的信息表头,使用.append即可创建所需表头。
2.多数网站的数据格式都是json,但是其返回的还附带了json数据的表头,注意删除掉。
如.replace("var ogoods_list_api = ","").replace("\n","")。这样才是符合格式要求的json(可以用这个网站测试json格式是否标准:Be JSON),否则无法用json.loads()读取,因为会被识别成字符串。
3.json.loads(s),中读取的是字符串数据。
4.即使读取出来的数据编码是unicode,但是写入excel的时候就被解码了。(使用了多种方式仍无法对数据解码,故打算提取后单独解码,后发现写入excel的是解码后的数据。意外发现。)
5.关于表头的提取:
- 首先使用两次split,分别是“,”和“:”将json的key提取出来。
- 接下来使用正则表达式提取{'ret'中的ret。在这里使用了这样的方法:用\w提取英文字符,再用''.join()合并起来
Python——LOL官方商城皮肤信息爬取(一次练手)的更多相关文章
- 关于python的中国历年城市天气信息爬取
一.主题式网络爬虫设计方案(15分)1.主题式网络爬虫名称 关于python的中国城市天气网爬取 2.主题式网络爬虫爬取的内容与数据特征分析 爬取中国天气网各个城市每年各个月份的天气数据, 包括最高城 ...
- 豆瓣电影信息爬取(json)
豆瓣电影信息爬取(json) # a = "hello world" # 字符串数据类型# b = {"name":"python"} # ...
- 安居客scrapy房产信息爬取到数据可视化(下)-可视化代码
接上篇:安居客scrapy房产信息爬取到数据可视化(下)-可视化代码,可视化的实现~ 先看看保存的数据吧~ 本人之前都是习惯把爬到的数据保存到本地json文件, 这次保存到数据库后发现使用mongod ...
- Python爬虫学习三------requests+BeautifulSoup爬取简单网页
第一次第一次用MarkDown来写博客,先试试效果吧! 昨天2018俄罗斯世界杯拉开了大幕,作为一个伪球迷,当然也得为世界杯做出一点贡献啦. 于是今天就编写了一个爬虫程序将腾讯新闻下世界杯专题的相关新 ...
- 初识python 之 爬虫:使用正则表达式爬取“糗事百科 - 文字版”网页数据
初识python 之 爬虫:使用正则表达式爬取"古诗文"网页数据 的兄弟篇. 详细代码如下: #!/user/bin env python # author:Simple-Sir ...
- Python爬虫学习之使用beautifulsoup爬取招聘网站信息
菜鸟一只,也是在尝试并学习和摸索爬虫相关知识. 1.首先分析要爬取页面结构.可以看到一列搜索的结果,现在需要得到每一个链接,然后才能爬取对应页面. 关键代码思路如下: html = getHtml(& ...
- Python爬虫(二十)_动态爬取影评信息
本案例介绍从JavaScript中采集加载的数据.更多内容请参考:Python学习指南 #-*- coding:utf-8 -*- import requests import re import t ...
- 【Python】博客信息爬取-微信消息自动发送
1.环境安装 python -m pip install --upgrade pip pip install bs4 pip install wxpy pip install lxml 2.博客爬取及 ...
- Python爬虫——使用 lxml 解析器爬取汽车之家二手车信息
本次爬虫的目标是汽车之家的二手车销售信息,范围是全国,不过很可惜,汽车之家只显示100页信息,每页48条,也就是说最多只能够爬取4800条信息. 由于这次爬虫的主要目的是使用lxml解析器,所以在信息 ...
随机推荐
- js实现语音功能
在项目中需要对ajax请求返回的消息进行语音播报.那么什么录制的就是在太low啦.下面js贴代码 str 为返回的data //语音播报function voiceAnnouncements(str) ...
- c/c++ 右值引用,forward关键字
c++ forward关键字 forward的由来:模板函数中的推导类型,作为另一函数的参数时,不管实参是什么类型,作为另一个参数的实参时,都变成了左值.因为C++里规定函数的形参就是左值,不过调用侧 ...
- koa-ueditor上传图片到七牛
问题描述:服务器系统架构采用的是koa(并非koa2),客户端富文本编辑器采用的是百度的ueditor控件.现在需要ueditor支持将图片直接上传到七牛云. 前提:百度的ueditor需要在本地配置 ...
- 小程序--scroll-view的横向滑动无效
- A Diversity-Promoting Objective Function for Neural Conversation Models论文阅读
本文来自李纪为博士的论文 A Diversity-Promoting Objective Function for Neural Conversation Models 1,概述 对于seq2seq模 ...
- 【css】图片垂直水平居中
一.已知宽高的图片实现垂直水平居中 1.借助margin-top负边距实现垂直居中 <!DOCTYPE html> <html> <head> <meta c ...
- 多线程手写Future模式
future模式 在进行耗时操作的时候,线程直接阻塞,我们需要优化这样的代码,让他再启动一个线程,不阻塞.可以执行下面的代码. 这个时候我们就用到了未来者模式 future设计类 只有一个方法 pub ...
- 分布式存储ceph——(6)ceph 讲解
一.Ceph简介: Ceph是一种为优秀的性能.可靠性和可扩展性而设计的统一的.分布式文件系统.ceph 的统一体现在可以提供文件系统.块存储和对象存储,分布式体现在可以动态扩展.在国内一些公司的云环 ...
- 一些矩阵范数的subgradients
目录 引 正交不变范数 定理1 定理2 例子:谱范数 例子:核范数 算子范数 定理3 定理4 例子 \(\ell_2\) <Subgradients> Subderivate-wiki S ...
- UnityEditorWindow自建窗口扩展
这里主要记录UnityEditorWindow的创建,以及常用的API接口样式 1,创建UnityEditorWindow 在Unity目录中,创建一个名为Editor的文件夹(任何位置),然后创建如 ...